Park, S., Wang, A. Y., Kawas, B., Liao, Q. V., Piorkowski, D., & Danilevsky, M. (2021). Facilitating Knowledge Sharing from Domain Experts to Data Scientists for Building NLP Models. 26th International Conference on Intelligent User Interfaces, 585–596. https://doi.org/10.1145/3397481.3450637
“In this paper, we propose Ziva, a framework to guide domain experts in sharing essential domain knowledge to data scientists for building NLP models.” (Park et al., 2021, p. 585) 🔤在本文中,我们提出了 Ziva,这是一个框架,可指导领域专家与数据科学家共享基本领域知识以构建 NLP 模型。🔤
“With Ziva, experts are able to distill and share their domain knowledge using domain concept extractors and five types of label justification over a representative data sample.” (Park et al., 2021, p. 585) 🔤借助 Ziva,专家能够使用领域概念提取器和五种类型的标签证明对代表性数据样本提炼和分享他们的领域知识。🔤
“Our results highlight that (1) domain experts are able to use Ziva to provide rich domain knowledge, while maintaining low mental load and stress levels; and (2) data scientists find Ziva’s output helpful for learning essential information about the domain, offering scalability of information, and lowering the burden on domain experts to share knowledge. We conclude this work by experimenting with building NLP models using the Ziva output for our case study.” (Park et al., 2021, p. 585) 🔤我们的结果强调 (1) 领域专家能够使用 Ziva 提供丰富的领域知识,同时保持较低的精神负荷和压力水平; (2) 数据科学家发现 Ziva 的输出有助于学习有关领域的基本信息,提供信息的可扩展性,并减轻领域专家分享知识的负担。我们通过使用 Ziva 输出为我们的案例研究构建 NLP 模型进行实验来结束这项工作。🔤
“However, building an ML model in a specialized domain is still expensive and time-consuming for at least two reasons. First, a common bottleneck in developing modern ML technologies is the requirement of a large quantity of labeled data. Second, many steps in an ML development pipeline, from problem definition to feature engineering to model debugging, necessitate an understanding of domain-specific knowledge and requirements.” (Park et al., 2021, p. 585) 🔤然而,出于至少两个原因,在专业领域构建 ML 模型仍然是昂贵且耗时的。首先,发展现代 ML 技术的一个常见瓶颈是需要大量标记数据。其次,ML 开发管道中的许多步骤,从问题定义到特征工程再到模型调试,都需要了解特定领域的知识和要求。🔤
“In this work, we set out to develop methods and interfaces that facilitate knowledge sharing from domain experts to data scientists for model development.” (Park et al., 2021, p. 585) 🔤在这项工作中,我们着手开发方法和接口,以促进从领域专家到数据科学家的知识共享以进行模型开发。🔤
“Instead of a data-labeling tool, Ziva intends to provide a diverse set of elicitation methods to gather knowledge from domain experts, then present the results as a repository to data scientists to serve their domain understanding needs and to build ML models for specialized domains.” (Park et al., 2021, p. 586) 🔤Ziva 不是数据标记工具,而是打算提供一组多样化的启发方法来从领域专家那里收集知识,然后将结果作为存储库呈现给数据科学家,以满足他们的领域理解需求并为专门领域构建 ML 模型。🔤
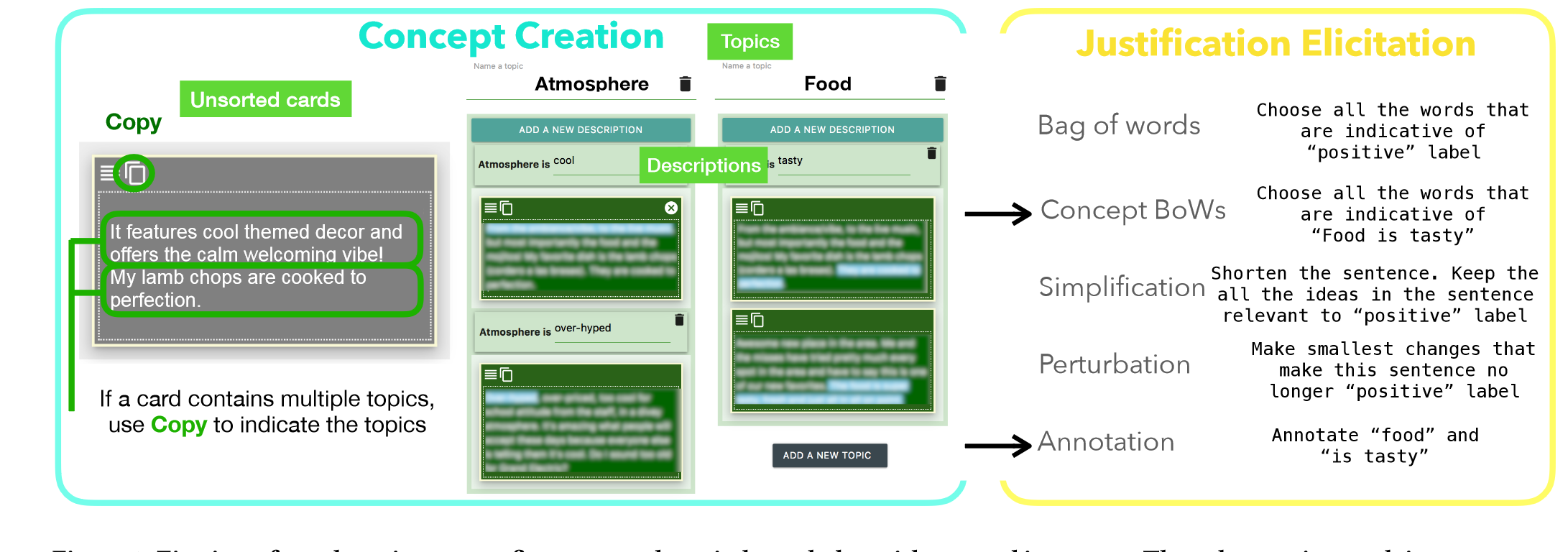
“In the current version of Ziva, we provide five different justification elicitation methods – bag of words, simplification, perturbation, concept bag of words, and concept annotation.” (Park et al., 2021, p. 586) 🔤在当前版本的 Ziva 中,我们提供了五种不同的证明引出方法——词袋法、简化法、扰动法、概念词袋法和概念标注法。🔤
“Through the study, we identified design requirements for domain knowledge-sharing tools in ML development workflow – scalability of information and lowering workload for domain experts.” (Park et al., 2021, p. 586) 通过研究,我们确定了 ML 开发工作流程中领域知识共享工具的设计要求——信息的可扩展性和降低领域专家的工作量。
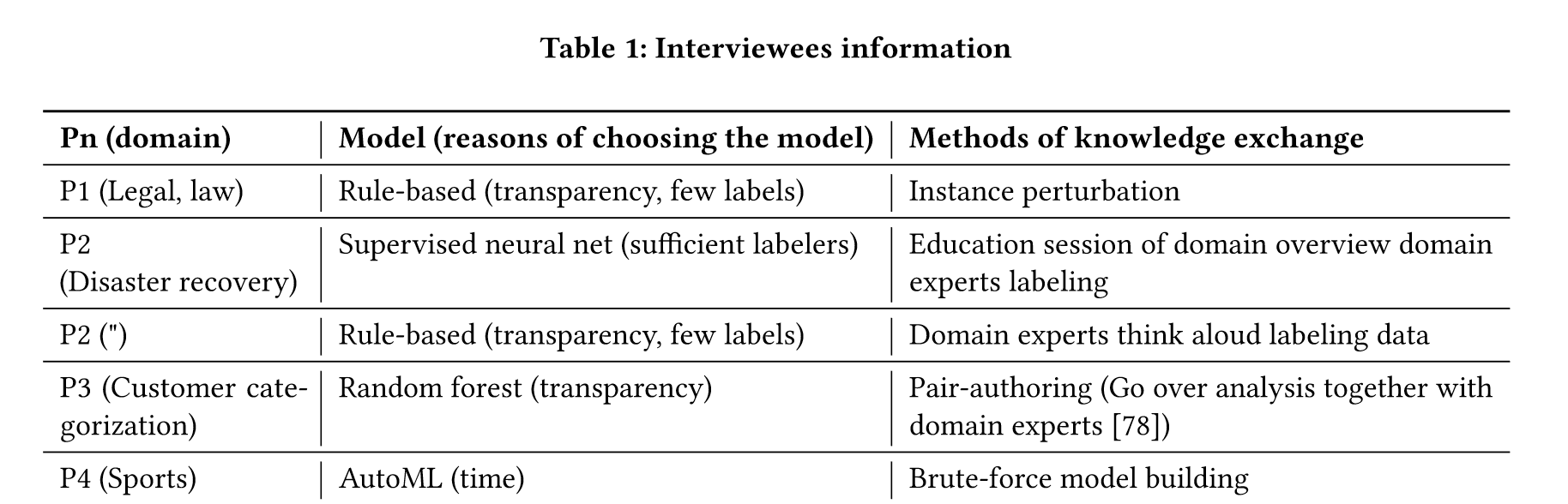
“Through a formative interview with data scientists who built models in a specialized domain, we identified their under-supported needs to learn about a domain from domain experts.” (Park et al., 2021, p. 586) 通过与在专业领域构建模型的数据科学家进行形成性访谈,我们确定了他们从领域专家那里了解领域的需求不足。
“We developed Ziva, a tool providing concept creation and five kinds of justification elicitation to gather domain knowledge from domain experts in formats that could help data scientists build NLP models.” (Park et al., 2021, p. 586) 我们开发了 Ziva,这是一种提供概念创建和五种理由启发的工具,可以从领域专家那里以可以帮助数据科学家构建 NLP 模型的格式收集领域知识。
“We conducted a case study using Ziva to elicit domain knowledge then presented the output to data scientists in an interview study.” (Park et al., 2021, p. 586) 我们使用 Ziva 进行了案例研究以获取领域知识,然后在访谈研究中向数据科学家展示了结果。
“We also investigated the experience of domain experts using Ziva. We believe that our analysis could inform the design of knowledge elicitation methods for domain experts.” (Park et al., 2021, p. 586) 我们还调查了领域专家使用 Ziva 的体验。我们相信我们的分析可以为领域专家的知识启发方法的设计提供信息。
“Domain experts also feature prominently in latter stages of data science projects such as model evaluation and communication of results [59].” (Park et al., 2021, p. 586) 领域专家在数据科学项目的后期阶段也很突出,例如模型评估和结果交流 [59]。
“Ziva interface is inspired by NLP text annotation tools [54, 60]. We take this design further to acquire domain knowledge for model development and data scientists.” (Park et al., 2021, p. 586) Ziva 界面的灵感来自 NLP 文本注释工具 [54、60]。我们进一步采用这种设计,为模型开发和数据科学家获取领域知识。
“More specifically, we found that the tool should scaffold domain experts to efficiently elicit domain knowledge within short amount of time (R1). Next, a tool should help data scientists to extract basic domain concepts (R2). Lastly, data scientists indicated that they often learn from domain experts’ rationale, especially how they justify a decision or label. Hence, the tool needs to facilitate label justification sharing (R3).” (Park et al., 2021, p. 588) 🔤更具体地说,我们发现该工具应该支持领域专家在短时间内有效地引出领域知识 (R1)。接下来,一个工具应该帮助数据科学家提取基本的领域概念 (R2)。最后,数据科学家表示,他们经常从领域专家的理论基础中学习,尤其是他们如何证明决策或标签的合理性。因此,该工具需要促进标签理由共享 (R3)。🔤
“Ziva extracts such a representative sample of m instances from a large training set of N text instances by the simple method of transforming the original text into ’tf-idf’ space, clustering the result using an algorithm such as k-means (setting k = m), and, for each cluster, returning the text instance closest to the cluster center.” (Park et al., 2021, p. 588) 🔤Ziva通过将原始文本转换到’tf-idf’空间的简单方法从N个文本实例的大型训练集中提取这样一个具有m个实例的代表性样本,使用k-means等算法对结果进行聚类(设置k = m),并且对于每个集群,返回离集群中心最近的文本实例。🔤