Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., … Wen, J.-R. (2023, November 24). A Survey of Large Language Models. arXiv.
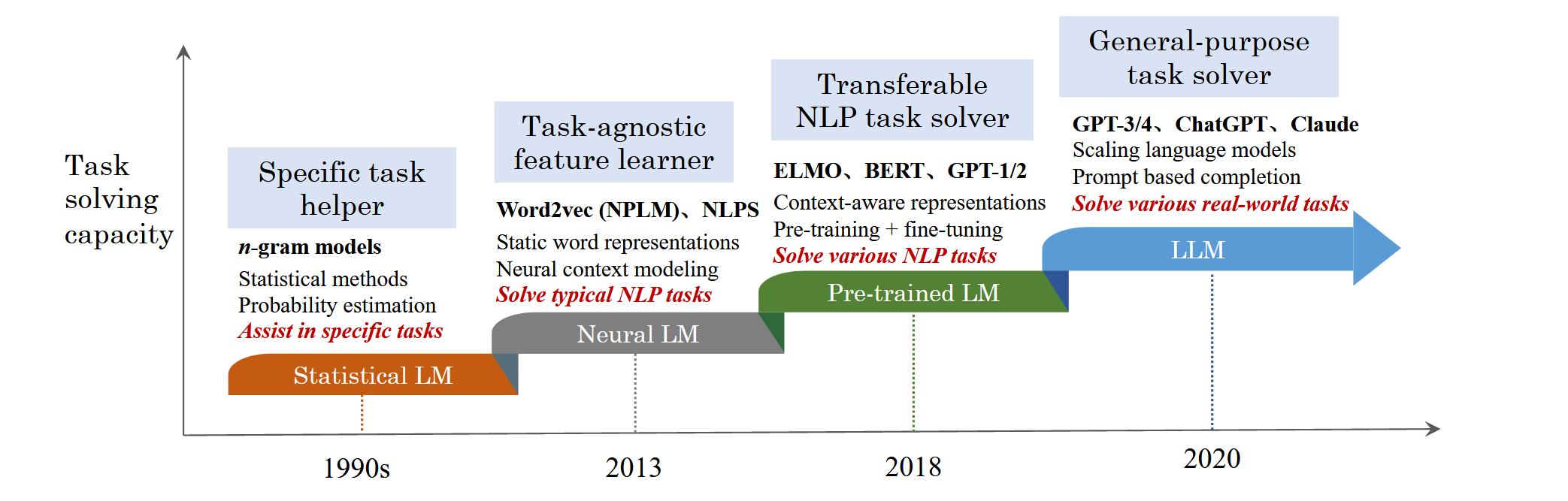
“Since the researchers have found that model scaling can lead to an improved model capacity, they further investigate the scaling effect by increasing the parameter scale to an even larger size.” (Zhao et al., 2023, p. 1) 由于研究人员发现模型缩放可以提高模型容量,因此他们通过将参数比例增加到更大的尺寸来进一步研究缩放效果。
“Interestingly, when the parameter scale exceeds a certain level, these enlarged language models not only achieve a significant performance improvement, but also exhibit some special abilities (e.g., incontext learning) that are not present in small-scale language models (e.g., BERT).” (Zhao et al., 2023, p. 1) 有趣的是,当参数规模超过一定水平时,这些扩大的语言模型不仅实现了显着的性能提升,而且还表现出了一些小规模语言模型(例如 BERT)中不存在的特殊能力(例如上下文学习) 。
“Statistical language models (SLM). SLMs [6–9] are developed based on statistical learning methods that rose in the 1990s. The basic idea is to build the word prediction model based on the Markov assumption, e.g., predicting the next word based on the most recent context. The SLMs with a fixed context length n are also called n-gram language models, e.g., bigram and trigram language models.” (Zhao et al., 2023, p. 1) 统计语言模型 (SLM)。SLMs[6\u20129]是基于1990年代兴起的统计学习方法开发的。其基本思想是基于马尔可夫假设构建单词预测模型,例如,根据最近的上下文预测下一个单词。具有固定上下文长度 n 的 SLM 也称为 n-gram 语言模型,例如二元组和三元组语言模型。
“Neural language models (NLM). NLMs [1, 17, 18] characterize the probability of word sequences by neural networks, e.g., multi-layer perceptron (MLP) and recurrent neural networks (RNNs). As a remarkable contribution, the work in [1] introduced the concept of distributed representation of words and built the word prediction function conditioned on the aggregated context features (i.e., the distributed word vectors).” (Zhao et al., 2023, p. 1) 神经语言模型(NLM)。 NLM [1,17,18]通过神经网络(例如多层感知器(MLP)和循环神经网络(RNN))来表征单词序列的概率。作为一项显着的贡献,[1]中的工作引入了单词的分布式表示的概念,并建立了以聚合上下文特征(即分布式单词向量)为条件的单词预测函数。
“Furthermore, word2vec [19, 20] was proposed to build a simplified shallow neural network for learning distributed word representations, which were demonstrated to be very effective across a variety of NLP tasks.” (Zhao et al., 2023, p. 2) 此外,word2vec [19, 20] 被提议构建一个简化的浅层神经网络来学习分布式单词表示,事实证明该网络在各种 NLP 任务中非常有效。
“Pre-trained language models (PLM). As an early attempt, ELMo [21] was proposed to capture context-aware word representations by first pre-training a bidirectional LSTM (biLSTM) network (instead of learning fixed word representations) and then fine-tuning the biLSTM network according to specific downstream tasks.” (Zhao et al., 2023, p. 2) 预训练语言模型 (PLM)。作为早期的尝试,ELMo[21]被提出通过首先预训练双向LSTM(biLSTM)网络(而不是学习固定的词表示),然后根据特定的下游任务微调biLSTM网络来捕获上下文感知的词表示。
“This study has inspired a large number of follow-up work, which sets the “pre-training and fine-tuning” learning paradigm.” (Zhao et al., 2023, p. 2) 这项研究启发了大量的后续工作,它设定了“预训练和微调”的学习范式。
“In this paradigm, it often requires fine-tuning the PLM for adapting to different downstream tasks.” (Zhao et al., 2023, p. 2) 在这种范式中,通常需要对 PLM 进行微调,以适应不同的下游任务。
“GPT-3 can solve few-shot tasks through in-context learning, whereas GPT-2 cannot do well.” (Zhao et al., 2023, p. 3) GPT-3 可以通过上下文学习解决少量任务,而 GPT-2 则不能做得很好。
“Early language models mainly aim to model and generate text data, while latest language models (e.g., GPT-4) focus on complex task solving. From language modeling to task solving, it is an important leap in scientific thinking, which is the key to understand the development of language models in the research history.” (Zhao et al., 2023, p. 3) 早期的语言模型主要旨在建模和生成文本数据,而最新的语言模型(例如 GPT-4)则专注于复杂的任务解决。从语言建模到任务解决,是科学思维的一次重要飞跃,是理解语言模型在研究史上发展的关键。
“To summarize, in the evolution process, the task scope that can be solved by language models have been greatly extended, and the task performance attained by language models have been significantly enhanced.” (Zhao et al., 2023, p. 3) 综上所述,在演化过程中,语言模型能够解决的任务范围得到了极大的扩展,语言模型所达到的任务性能也得到了显着的增强。
“First, LLMs display some surprising emergent abilities that may not be observed in previous smaller PLMs. These abilities are key to the performance of language models on complex tasks, making AI algorithms unprecedently powerful and effective.” (Zhao et al., 2023, p. 3) 首先,LLM展示了一些令人惊讶的新兴能力,这些能力在以前的小型 PLM 中可能无法观察到。这些能力是语言模型在复杂任务上表现的关键,使人工智能算法变得前所未有的强大和有效。
“Second, LLMs would revolutionize the way that humans develop and use AI algorithms.” (Zhao et al., 2023, p. 3) 其次,LLM将彻底改变人类开发和使用人工智能算法的方式。
“Third, the development of LLMs no longer draws a clear distinction between research and engineering. The training of LLMs requires extensive practical experiences in large-scale data processing and distributed parallel training.” (Zhao et al., 2023, p. 3) 第三,LLM的发展不再明确区分研究和工程。LLM的训练需要在大规模数据处理和分布式并行训练方面有丰富的实践经验。
“In the field of NLP, LLMs can serve as a general-purpose language task solver (to some extent), and the research paradigm has been shifting towards the use of LLMs.” (Zhao et al., 2023, p. 3) 在NLP领域,LLM可以(在某种程度上)充当通用语言任务求解器,并且研究范式已经转向使用LLM。
“Due to the huge demand of computation resources, it is very costly to carry out repetitive, ablating studies for investigating the effect of various strategies for training LLMs. Indeed, LLMs are mainly trained by industry, where many important training details (e.g., data collection and cleaning) are not revealed to the public.” (Zhao et al., 2023, p. 3) 由于计算资源的巨大需求,进行重复的消融研究以研究各种训练LLM策略的效果是非常昂贵的。事实上,LLM主要由行业培训,其中许多重要的培训细节(例如,数据收集和清理)没有向公众透露。
“this survey conducts a literature review of the recent advances in LLMs from four major aspects, including pre-training (how to pretrain a capable LLM), adaptation (how to effectively adapt pre-trained LLMs for better use), utilization (how to use LLMs for solving various downstream tasks) and capability evaluation (how to evaluate the abilities of LLMs and existing empirical findings).” (Zhao et al., 2023, p. 4) 本综述从预训练(如何预训练一个有能力的LLM)、适应(如何有效地调整预训练LLM以使其更好地使用)、利用(如何使用LLM解决各种下游任务)和能力评估(如何评估LLM的能力和现有实证结果)四个主要方面对LLM的最新进展进行文献综述。
“Formulation of Scaling Laws for LLMs. Currently, LLMs are mainly built upon the Transformer architecture [22], where multi-head attention layers are stacked in a very deep neural network.” (Zhao et al., 2023, p. 4) LLM的缩放定律的制定。 目前,LLM主要建立在Transformer架构[22]之上,其中多头注意力层堆叠在一个非常深的神经网络中。
“a follow-up study [58] from OpenAI has shown that the language modeling loss can be decomposed into two parts, namely irreducible loss (the entropy of the true data distribution) and reducible loss (an estimate of the KL divergence between the true and model distributions).” (Zhao et al., 2023, p. 4) OpenAI的后续研究[58]表明,语言建模损失可以分解为两部分,即不可约损失(真实数据分布的熵)和可约损失(真实分布和模型分布之间的KL差异估计)。
“Predictable scaling. In practice, scaling law can be used to instruct the training of LLMs, and it has been proven feasible to reliably estimate the performance of larger models based on that of smaller models, called predictable scaling [46].” (Zhao et al., 2023, p. 5) 可预测的扩展。在实践中,标度律可用于指导LLM的训练,并且已经证明可以基于较小模型的性能可靠地估计较大模型的性能,称为可预测标度[46]。
“Intuitively, a model with a smaller language modeling loss tends to yield a better performance on downstream tasks, since language modeling loss can be considered as a general measure of the overall model capacity.” (Zhao et al., 2023, p. 5) 直观上,语言建模损失较小的模型往往会在下游任务上产生更好的性能,因为语言建模损失可以被视为整体模型能力的一般度量。
“Despite that, readers should be aware that a direct decrease in language modeling loss does not always indicate an improvement of model performance on downstream tasks. Specially, the phenomenon of inverse scaling would occur for some tasks, where task performance surprisingly becomes worse as the language modeling loss decreases [62].” (Zhao et al., 2023, p. 5) 尽管如此,读者应该意识到,语言建模损失的直接减少并不总是意味着下游任务的模型性能有所提高。特别是,某些任务会出现逆缩放现象,随着语言建模损失的减少,任务性能会出人意料地变差[62]。
“In the literature [31], emergent abilities of LLMs are formally defined as “the abilities that are not present in small models but arise in large models”, which is one of the most prominent features that distinguish LLMs from previous PLMs.” (Zhao et al., 2023, p. 5) 在文献[31]中,LLM的涌现能力被正式定义为“在小模型中不存在但在大模型中出现的能力”,这是LLM与以前的PLM区别开来的最突出的特征之一。
“It further introduces a notable characteristic when emergent abilities occur [31]: performance rises significantly above random when the scale reaches a certain level.” (Zhao et al., 2023, p. 5) 当出现紧急能力时,它进一步引入了一个显着的特征[31]:当规模达到一定水平时,性能会显着高于随机。
“In-context learning. The in-context learning (ICL) ability is formally introduced by GPT-3 [55]: assuming that the language model has been provided with a natural language instruction and/or several task demonstrations, it can generate the expected output for the test instances by completing the word sequence of input text, without requiring additional training or gradient update” (Zhao et al., 2023, p. 5) 情境学习。上下文学习(ICL)能力由 GPT-3 [55] 正式引入:假设语言模型已提供自然语言指令和/或多个任务演示,它可以生成测试实例的预期输出通过完成输入文本的单词序列,无需额外的训练或梯度更新
“Instruction following. By fine-tuning with a mixture of multi-task datasets formatted via natural language descriptions (called instruction tuning), LLMs are shown to perform well on unseen tasks that are also described in the form of instructions [28, 66, 67].” (Zhao et al., 2023, p. 5) 指令如下。通过使用通过自然语言描述格式化的多任务数据集的混合进行微调(称为指令调优),LLM被证明在看不见的任务上表现良好,这些任务也以指令的形式描述[28,66,67]。
“Scaling. As discussed in previous parts, there exists an evident scaling effect in Transformer language models: larger model/data sizes and more training compute typically lead to an improved model capacity [30, 34].” (Zhao et al., 2023, p. 6) 缩放。如前几部分所述,Transformer 语言模型中存在明显的缩放效应:更大的模型/数据大小和更多的训练计算通常会导致模型容量的提高 [30, 34]。
“Training. Due to the huge model size, it is very challenging to successfully train a capable LLM. Distributed training algorithms are needed to learn the network parameters of LLMs, in which various parallel strategies are often jointly utilized. To support distributed training, several optimization frameworks have been released to facilitate the implementation and deployment of parallel algorithms, such as DeepSpeed [74] and Megatron-LM [75–77].” (Zhao et al., 2023, p. 6) 训练。由于模型规模巨大,成功训练一个有能力的LLM是非常具有挑战性的。需要分布式训练算法来学习LLM的网络参数,其中经常同时使用各种并行策略。为了支持分布式训练,已经发布了几个优化框架来促进并行算法的实现和部署,例如 DeepSpeed [74] 和 Megatron-LM [75\u201277]。
“After being pre-trained on large-scale corpora, LLMs are endowed with potential abilities as general-purpose task solvers. These abilities might not be explicitly exhibited when LLMs perform some specific tasks.” (Zhao et al., 2023, p. 6) 在对大规模语料库进行预训练后,LLM 被赋予了作为通用任务解决者的潜在能力。当 LLM 执行某些特定任务时,这些能力可能不会显式表现出来。
“Furthermore, we can perform instruction tuning on LLMs with task descriptions expressed in natural language, for improving the generalizability of LLMs on unseen tasks.” (Zhao et al., 2023, p. 6) 此外,我们可以对 LLM 进行指令调优,用自然语言表达任务描述,以提高 LLM 在看不见的任务上的泛化性。
“Alignment tuning. Since LLMs are trained to capture the data characteristics of pre-training corpora (including both high-quality and low-quality data), they are likely to generate toxic, biased, or even harmful content for humans. It is necessary to align LLMs with human values, e.g., helpful, honest, and harmless.” (Zhao et al., 2023, p. 6) 对齐调整。由于 LLM 被训练为捕获预训练语料库的数据特征(包括高质量和低质量数据),因此它们可能会对人类产生有毒、有偏见甚至有害的内容。有必要使 LLM 与人类价值观保持一致,例如,乐于助人、诚实和无害。
“It incorporates human in the training loop with elaborately designed labeling strategies. ChatGPT is indeed developed on a similar technique to InstructGPT, which shows a strong alignment capacity in producing high-quality, harmless responses, e.g., rejecting to answer insulting questions.” (Zhao et al., 2023, p. 7) 它将人类纳入训练循环中,并采用精心设计的标签策略。 ChatGPT 确实是基于与 InstructGPT 类似的技术开发的,它在产生高质量、无害的响应(例如拒绝回答侮辱性问题)方面表现出强大的对齐能力。
“The basic principle underlying GPT models is to compress the world knowledge into the decoder-only Transformer model by language modeling, such that it can recover (or memorize) the semantics of world knowledge and serve as a general-purpose task solver. Two key points to the success are (I) training decoder-only Transformer language models that can accurately predict the next word and (II) scaling up the size of language models.” (Zhao et al., 2023, p. 7) GPT模型的基本原理是通过语言建模将世界知识压缩为仅解码器的Transformer模型,使其能够恢复(或记忆)世界知识的语义并作为通用任务求解器。成功的两个关键点是(一)训练仅解码器的 Transformer 语言模型,使其能够准确预测下一个单词;(二)扩大语言模型的规模。
“n the GPT-3’s paper, it formally introduced the concept of in-context learning (ICL)17, which utilizes LLMs in a fewshot or zero-shot way. ICL can teach (or instruct) LLMs to understand the tasks in the form of natural language text.” (Zhao et al., 2023, p. 9) 在 GPT-3 的论文中,它正式引入了上下文学习 (ICL)17 的概念,它以 few-shot 或零样本的方式利用 LLM。ICL 可以教授(或指导)LLM 以自然语言文本的形式理解任务。
“Overall, OpenAI has explored two major approaches to further improving the GPT-3 model, i.e., training on code data and alignment with human preference, which are detailed as follows.” (Zhao et al., 2023, p. 10) 总体而言,OpenAI探索了两种主要方法来进一步改进GPT-3模型,即代码数据训练和与人类偏好一致,具体如下。
“Actually, the GPT-3.5 models are developed based on a code-based GPT model (i.e., code-davinci-002), which indicates that training on code data is a very useful practice to improve the model capacity of GPT models, especially the reasoning ability.” (Zhao et al., 2023, p. 10) 实际上,GPT-3.5模型是基于基于代码的GPT模型(即code-davinci-002)开发的,这表明对代码数据进行训练对于提高GPT模型的模型能力是非常有用的实践,尤其是推理能力。
“OpenAI describes their approach to alignment research in a technical article [130], which has summarized three promising directions: “training AI systems to use human feedback, to assist human evaluation and to do alignment research”.” (Zhao et al., 2023, p. 10) OpenAI在一篇技术文章[130]中描述了他们的对齐研究方法,该文章总结了三个有前途的方向:“训练人工智能系统使用人类反馈,协助人类评估和进行对齐研究”。
“As another important aspect, GPT4 has been developed on a well-established deep learning infrastructure with improved optimization methods. They introduced a new mechanism called predictable scaling that can accurately predict the final performance with a small proportion of compute during model training.” (Zhao et al., 2023, p. 10) 作为另一个重要方面,GPT4 是在完善的深度学习基础设施上开发的,并改进了优化方法。他们引入了一种称为可预测缩放的新机制,该机制可以在模型训练期间以一小部分计算准确预测最终性能。
“From the perspective of engineering, OpenAI has adopted an iterative deployment strategy [134] to develop the models and products by following a five-stage development and deployment life-cycle, which aims to effectively reduce the potential risks of using the models.” (Zhao et al., 2023, p. 11) 从工程的角度来看,OpenAI采用迭代部署策略[134],遵循五个阶段的开发和部署生命周期来开发模型和产品,旨在有效降低使用模型的潜在风险。
“Among them, FlanT5 (11B version) can serve as a premier model for research on instruction tuning, since it explores the instruction tuning from three aspects [69]: increasing the number of tasks, scaling the model size, and fine-tuning with chain-ofthought prompting data.” (Zhao et al., 2023, p. 11) 其中,FlanT5(11B版本)可以从三个方面探索指令调优[69],因为它从增加任务数量、扩展模型大小和利用思维链提示数据进行微调三个方面探索指令调优,因此可以作为指令调优的首要模型。
“As for multilingual tasks, mT0 (13B version) might be a good candidate model, which has been fine-tuned on multilingual tasks with multilingual prompts.” (Zhao et al., 2023, p. 11) 对于多语言任务,mT0(13B版本)可能是一个很好的候选模型,它已经针对具有多语言提示的多语言任务进行了微调。
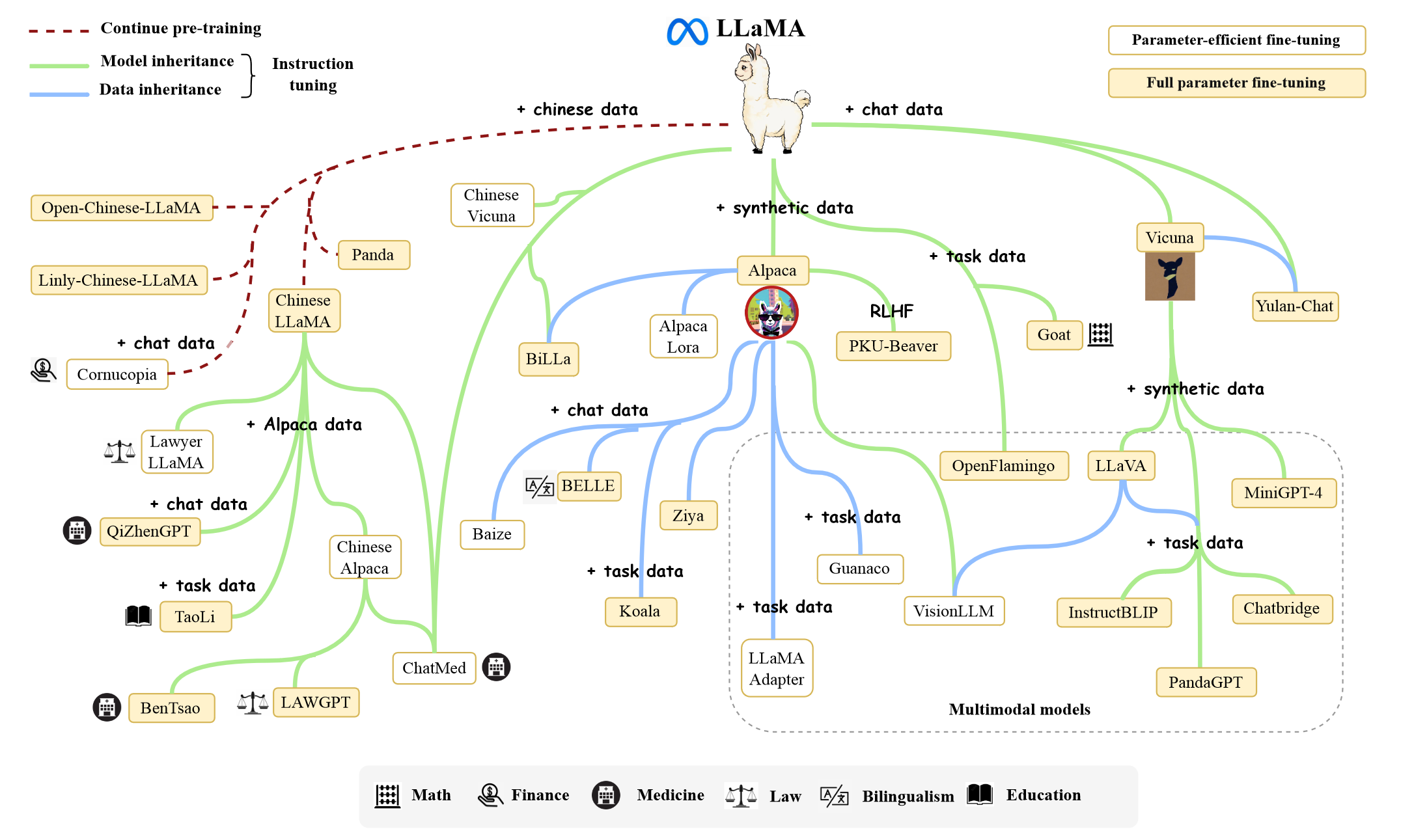
“Due to the excellent performance and availability of the LLaMA model family, many multimodal models incorporate them as the base language models, to achieve strong language understanding and generation abilities.” (Zhao et al., 2023, p. 12) 由于LLaMA模型家族优异的性能和可用性,许多多模态模型将其作为基础语言模型,以实现强大的语言理解和生成能力。
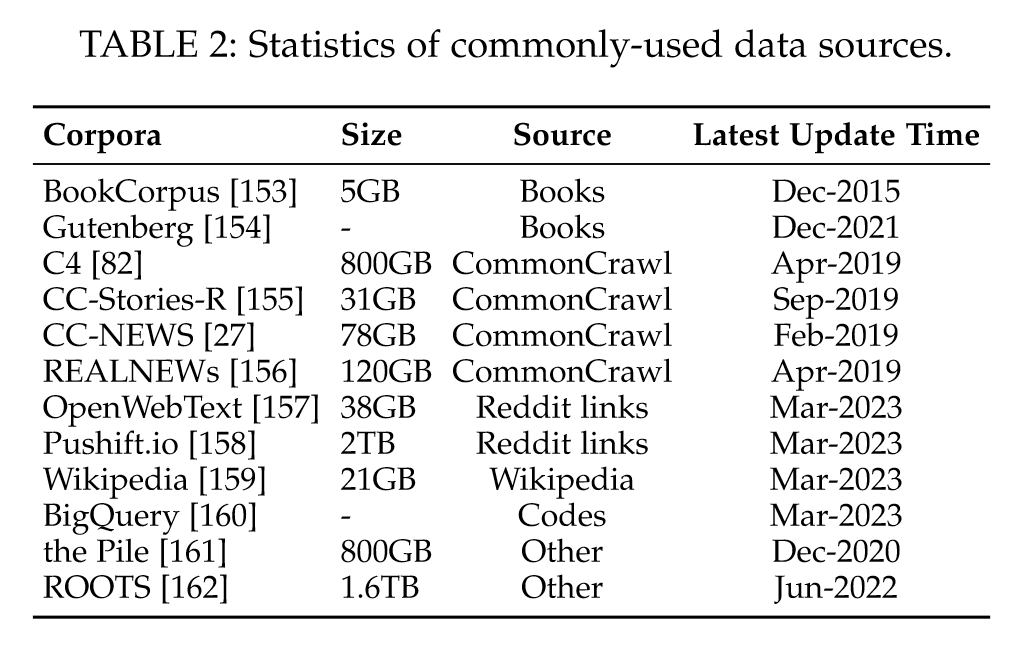
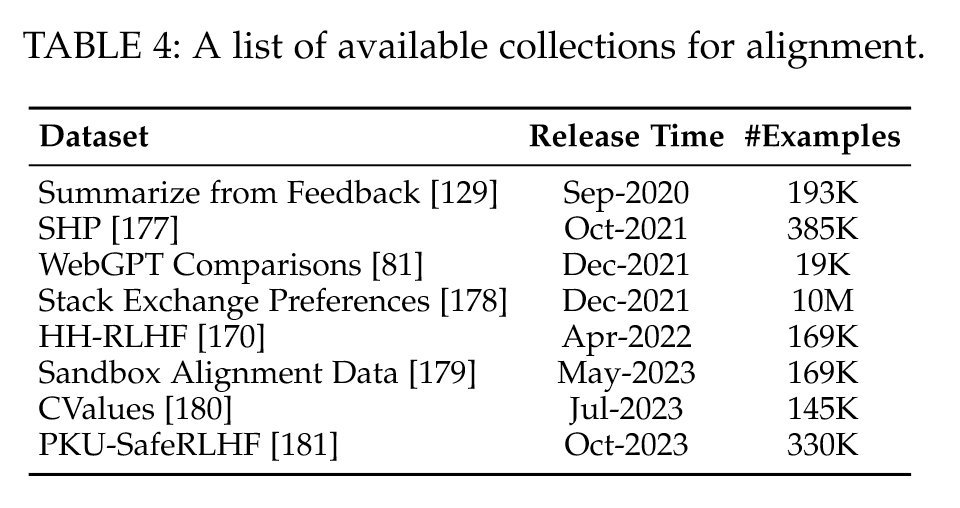
“Based on their content types, we categorize these corpora into six groups: Books, CommonCrawl, Reddit links, Wikipedia, Code, and others.” (Zhao et al., 2023, p. 13) 根据它们的内容类型,我们将这些语料库分为六组:书籍、CommonCrawl、Reddit 链接、维基百科、代码等。
“The Colossal Clean Crawled Corpus (C4) includes five variants21, namely en (806G), en.noclean (6T), realnewslike (36G), webtextlike (17G), and multilingual (38T). The en version has been utilized for pre-training T5 [82], LaMDA [68], Gopher [64], and UL2 [89].” (Zhao et al., 2023, p. 13) Colossal Clean Crawled Corpus (C4) 包括五个变体21,即 en (806G)、en.noclean (6T)、realnewslike (36G)、webtextlike (17G) 和 multilingual (38T)。 en 版本已用于预训练 T5 [82]、LaMDA [68]、Gopher [64] 和 UL2 [89]。
“In practice, it commonly requires a mixture of different data sources for pre-training LLMs (see Figure 6), instead of a single corpus. Therefore, existing studies commonly mix several ready-made datasets (e.g., C4, OpenWebText, and the Pile), and then perform further processing to obtain the pre-training corpus.” (Zhao et al., 2023, p. 14) 在实践中,它通常需要混合使用不同的数据源来预训练 LLM(参见图 6),而不是单个语料库。因此,现有的研究通常将几个现成的数据集(例如 C4、OpenWebText 和 Pile)混合在一起,然后进行进一步处理以获得预训练语料库。
“LLaMA [57] extracts training data from various sources, including CommonCrawl, C4 [82], Github, Wikipedia, books, ArXiv, and StackExchange. The training data size for LLaMA (6B) and LLaMA (13B) is 1.0T tokens, while 1.4T tokens are used for LLaMA (32B) and LLaMA (65B).” (Zhao et al., 2023, p. 14) LLaMA [57] 从各种来源提取训练数据,包括 CommonCrawl、C4 [82]、Github、维基百科、书籍、ArXiv 和 StackExchange。 LLaMA (6B) 和 LLaMA (13B) 的训练数据大小为 1.0T 令牌,而 LLaMA (32B) 和 LLaMA (65B) 使用 1.4T 令牌。
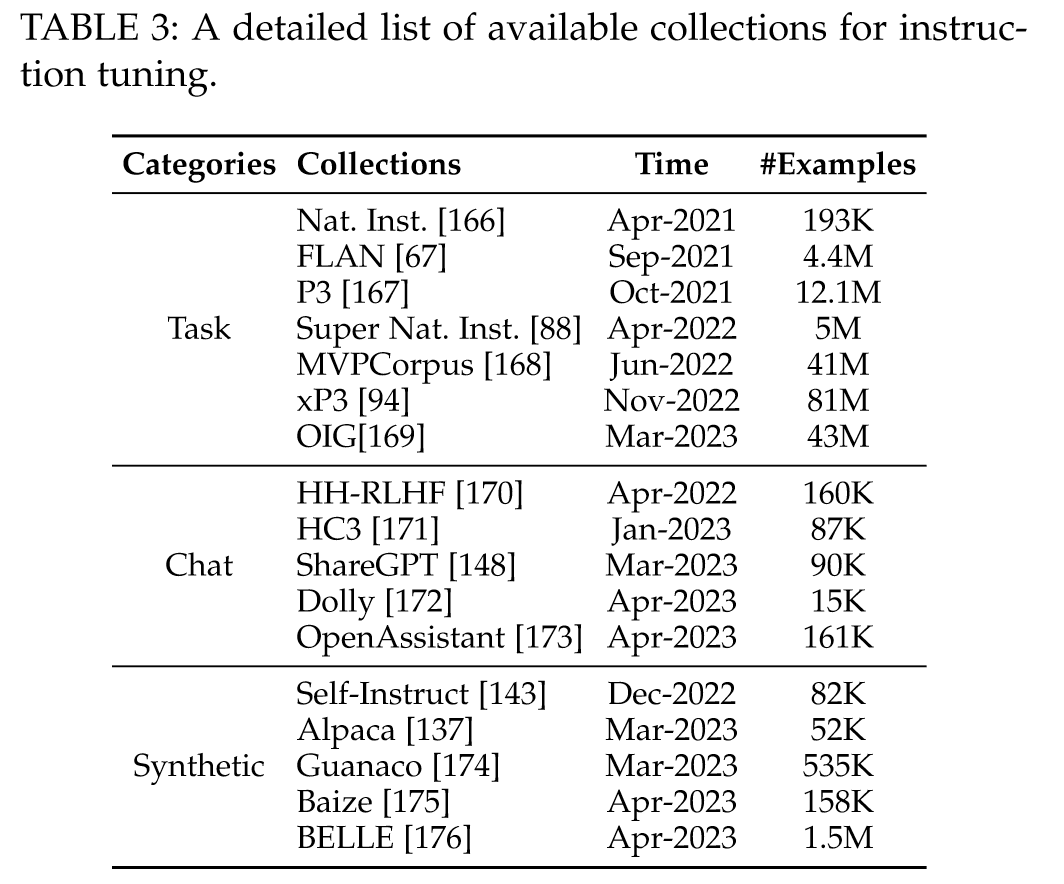
“After pre-training, it requires further fine-tuning LLMs to enhance the model capacity, which often involve two major steps, namely instruction tuning (supervised fine-tuning) and alignment tuning.” (Zhao et al., 2023, p. 14) 预训练后,需要进一步微调LLM以增强模型能力,这通常涉及两个主要步骤,即指令调优(监督微调)和对齐调优。
“After pre-training, instruction tuning (a.k.a., supervised finetuning) is an important method to enhance or unlock specific abilities of LLMs (e.g., instruction following).” (Zhao et al., 2023, p. 14) 预训练后,指令调整(又名监督微调)是增强或解锁 LLM 特定能力(例如指令遵循)的重要方法。
“we introduce several widely used datasets for instruction tuning, and categorize them into three main types based on the construction method of formatted instruction instances, namely NLP task datasets, daily chat datasets and synthetic datasets. We” (Zhao et al., 2023, p. 14) 我们介绍了几种广泛使用的指令调优数据集,并根据格式化指令实例的构造方法将其分为三种主要类型,即NLP任务数据集、日常聊天数据集和合成数据集。我们
“NLP Task Datasets. This kind of datasets are formatted based on collected NLP task datasets (e.g., text classification and summarization) with corresponding natural language task descriptions. In this category, P3 [182] and FLAN [67, 183] are two widely used datasets for instruction tuning.” (Zhao et al., 2023, p. 14) NLP 任务数据集。此类数据集基于收集的 NLP 任务数据集(例如文本分类和摘要)以及相应的自然语言任务描述进行格式化。在这一类别中,P3 [182] 和 FLAN [67, 183] 是两个广泛使用的指令调优数据集。
“Daily Chat Datasets. This kind of datasets are constructed based on real user conversations where queries are posed by humans and responses are mainly generated by human labelers or LLMs (e.g., ChatGPT, GPT-4). The conversation types include open-ended generation, question answering, brainstorming, and chatting. In this category, ShareGPT [148], OpenAssistant [173] and Dolly [172] are three commonly used datasets for LLM fine-tuning.” (Zhao et al., 2023, p. 15) 每日聊天数据集。此类数据集是基于真实用户对话构建的,其中查询由人类提出,响应主要由人类标记者或 LLM 生成(例如 ChatGPT、GPT-4)。对话类型包括开放式生成、问答、头脑风暴和聊天。在这一类别中,ShareGPT [148]、OpenAssistant [173] 和 Dolly [172] 是 LLM 微调的三个常用数据集。
“Synthetic Datasets. This kind of datasets are typically constructed by instructing LLMs, based on pre-defined guidance rules or methods. In this category, Self-Instruct52K [143], Alpaca [142] and Baize [175] are three commonly used synthetic datasets for LLMs” (Zhao et al., 2023, p. 15) 合成数据集。这类数据集通常是通过指导LLM来构建的,基于预定义的指导规则或方法。在这一类别中,Self-Instruct52K [143]、Alpaca [142] 和 Baize [175] 是 LLM 中常用的三个合成数据集
“SHP [177] focuses on the helpfulness of responses. It comprises 385K collective human preferences over responses to questions/instructions across 18 diverse subject areas, spanning topics from cooking to legal advice. Each instance is a Reddit post containing a question or instruction and a pair of top-level comments, one of which is deemed as more preferable by Reddit users and the other one is deemed as less helpful. Different from HH-RLHF [170], the data in SHP consists of naturally occurring and humanwritten responses.” (Zhao et al., 2023, p. 15) SHP[177]侧重于响应的有用性。它包括 385K 对 18 个不同主题领域的问题/指令的回答的集体人类偏好,涵盖从烹饪到法律建议的主题。每个实例都是一个 Reddit 帖子,其中包含一个问题或说明以及一对顶级评论,其中一个被 Reddit 用户认为更可取,另一个被认为不太有用。与HH-RLHF[170]不同,SHP中的数据由自然发生和人工书写的响应组成。
“Sandbox Alignment Data [179] is an alignment dataset containing feedback from LLMs rather than human. It comes from a virtual interaction environment called SANDBOX, where the model simulates social interactions with other models and revise responses according to the feedback from other models. The dataset contains 169K instances, and each instance consists of a societal query, several responses, and corresponding ratings from other models.” (Zhao et al., 2023, p. 15) 沙盒对齐数据[179]是一个对齐数据集,包含来自LLM而不是人类的反馈。它来自一个名为 SANDBOX 的虚拟交互环境,该模型模拟与其他模型的社交交互,并根据其他模型的反馈修改响应。该数据集包含 169K 个实例,每个实例由一个社会查询、多个响应和其他模型的相应评级组成。
“DeepSpeed [74] is a deep learning optimization library (compatible with PyTorch) developed by Microsoft, which has been used to train a number of LLMs, such as MTNLG [113] and BLOOM [78]. It provides the support of various optimization techniques for distributed training, such as memory optimization (ZeRO technique, gradient checkpointing), and pipeline parallelism.” (Zhao et al., 2023, p. 16) DeepSpeed [74]是微软开发的深度学习优化库(与PyTorch兼容),已用于训练许多LLM,例如MTNLG [113]和BLOOM [78]。它为分布式训练提供各种优化技术的支持,例如内存优化(ZeRO技术、梯度检查点)和管道并行性。
“DeepSpeed-MII [194] is also a memory efficient Python library developed by DeepSpeed [74]. It aims to democratize LLMs inference by prioritizing high throughput, low latency, and cost-effectiveness. DeepSpeed-MII achieves accelerated text generation inference by leveraging four essential technologies: blocked KV caching, continuous batching, dynamic SplitFuse, and high-performance CUDA Kernels. It currently supports over 13,000 models across three popular model architectures, such as LLaMA [57], Mistral [195], and OPT [90].” (Zhao et al., 2023, p. 16) DeepSpeed-MII [194] 也是 DeepSpeed [74] 开发的一个内存效率高的 Python 库。它旨在通过优先考虑高吞吐量、低延迟和成本效益来实现 LLM 推理的民主化。DeepSpeed-MII 通过利用 4 项基本技术实现加速文本生成推理:阻塞 KV 缓存、连续批处理、动态 SplitFuse 和高性能 CUDA 内核。它目前支持三种流行模型架构的 13,000 多个模型,例如 LLaMA [57]、Mistral [195] 和 OPT [90]。
“DeepSpeed-Chat [196] is a fast, cost-effective, and easy-to-use system framework that enables the integration of the complete RLHF process during model training. It is featured by three major functionalities: (1) it simplifies the training and inference process for ChatGPT-like models, enabling using a simple script to implement multiple training or inference steps; (2) it replicates the training mode of InstructGPT [66] and provides a complete pipeline for three training steps (i.e., SFT, reward model fine-tuning, and RLHF); (3) it integrates the training engine and inference engine of Deepspeed into a unified hybrid engine (Deepspeed HE) for RLHF training, which enables seamless switch between training and inference modes, and leveraging various optimizations from DeepSpeed Inference.” (Zhao et al., 2023, p. 16) DeepSpeed-Chat [196] 是一种快速、经济高效且易于使用的系统框架,可以在模型训练期间集成完整的 RLHF 流程。它具有三大功能:(1)简化了类ChatGPT模型的训练和推理过程,可以使用简单的脚本实现多个训练或推理步骤; (2)它复制了InstructGPT[66]的训练模式,并为三个训练步骤(即SFT、奖励模型微调和RLHF)提供了完整的管道; (3)它将Deepspeed的训练引擎和推理引擎集成为统一的混合引擎(Deepspeed HE),用于RLHF训练,实现训练和推理模式之间的无缝切换,并利用DeepSpeed Inference的各种优化。
“Since online conversational data often involves discussions among multiple participants, an effective processing way is to transform a conversation into a tree structure, where the utterance is linked to the one it responds to.” (Zhao et al., 2023, p. 17) 由于在线对话数据通常涉及多个参与者之间的讨论,因此一种有效的处理方法是将对话转换为树结构,其中话语与其响应的话语相关联。
“In order to enhance the understanding of scientific knowledge for LLMs [35, 203], it is useful to incorporate a scientific corpus for model pre-training [35, 203]. By pretraining on a vast amount of scientific text, LLMs can achieve impressive performance in scientific and reasoning tasks [204]. To construct the scientific corpus, existing efforts mainly collect arXiv papers, scientific textbooks, math webpages, and other related scientific resources.” (Zhao et al., 2023, p. 18) 为了增强LLM对科学知识的理解[35,203],结合科学语料库进行模型预训练是有用的[35,203]。通过对大量科学文本进行预训练,LLM可以在科学和推理任务中取得令人印象深刻的表现[204]。为了构建科学语料库,现有的工作主要收集arXiv论文、科学教科书、数学网页和其他相关科学资源。
“The generated programs can successfully pass expert-designed unit-test cases [105] or solve competitive programming questions [114].” (Zhao et al., 2023, p. 18) 生成的程序可以成功通过专家设计的单元测试用例[105]或解决竞争性编程问题[114]。
“A recent study [47] also speculates that training on code might be a source of complex reasoning abilities (e.g., chain-of-thought ability [33]).” (Zhao et al., 2023, p. 18) 最近的一项研究 [47] 还推测,代码训练可能是复杂推理能力的来源(例如,思维链能力 [33])。
“After collecting a large amount of text data, it is essential to preprocess the data for constructing the pre-training corpus, especially removing noisy, redundant, irrelevant, and potentially toxic data [56, 64, 212], which may largely affect the capacity and performance of LLMs.” (Zhao et al., 2023, p. 18) 在收集了大量的文本数据后,必须对数据进行预处理以构建预训练语料库,特别是去除嘈杂、冗余、不相关和潜在有毒的数据[56,64,212],这些数据可能会在很大程度上影响LLM的能力和性能。
“Quality Filtering. To remove low-quality data from the collected corpus, existing work generally adopts two approaches: (1) classifier-based, and (2) heuristic-based. The former approach trains a selection classifier based on highquality texts and leverages it to identify and filter out lowquality data.” (Zhao et al., 2023, p. 18) 质量过滤。为了从收集的语料库中去除低质量数据,现有工作通常采用两种方法:(1)基于分类器,(2)基于启发式。前一种方法基于高质量文本训练选择分类器,并利用它来识别和过滤掉低质量数据。
“However, several studies [64, 112] find that a classifier-based approach may result in the unintentional removal of high-quality texts in dialectal, colloquial, and sociolectal languages, which potentially leads to bias in the pre-training corpus and diminishes the corpus diversity.” (Zhao et al., 2023, p. 18) 然而,一些研究 [64, 112] 发现,基于分类器的方法可能会导致无意中删除方言、口语和社会语言中的高质量文本,这可能会导致预训练语料库中的偏差并减少语料库多样性。
“Language based filtering. If a LLM would be mainly used in the tasks of certain languages, the text in other languages can be filtered.” (Zhao et al., 2023, p. 18) 基于语言的过滤。如果LLM主要用于某些语言的任务,则可以过滤其他语言的文本。
“Metric based filtering. Evaluation metrics about the generated texts, e.g., perplexity, can be employed to detect and remove unnatural sentences.” (Zhao et al., 2023, p. 18) 基于指标的过滤。关于生成文本的评估指标(例如困惑度)可用于检测和删除不自然的句子。
“Statistic based filtering. Statistical features of a corpus, e.g., the punctuation distribution, symbol-to-word ratio, and sentence length, can be utilized to measure the text quality and filter the low-quality data.” (Zhao et al., 2023, p. 18) 基于统计的过滤。语料库的统计特征,例如标点分布、符号与单词的比率、句子长度,可以用来衡量文本质量并过滤低质量数据。
“Keyword based filtering. Based on specific keyword set, the noisy or unuseful elements in the text, such as HTML tags, hyperlinks, boilerplates, and offensive words, can be identified and removed.” (Zhao et al., 2023, p. 18) 基于关键字的过滤。根据特定的关键字集,可以识别并删除文本中的噪音或无用元素,例如 HTML 标签、超链接、样板文件和攻击性词语。
“Existing work [214] has found that duplicate data in a corpus would reduce the diversity of language models, which may cause the training process to become unstable and thus affect the model performance.” (Zhao et al., 2023, p. 18) 现有工作[214]发现语料库中的重复数据会降低语言模型的多样性,这可能导致训练过程变得不稳定,从而影响模型性能。
“Specially, de-duplication can be performed at different granularities, including sentence-level, document-level, and dataset-level de-duplication. First, low-quality sentences that contain repeated words and phrases should be removed, as they may introduce repetitive patterns in language modeling [215]. At the document level, existing studies mostly rely on the overlap ratio of surface features (e.g., words and n-grams overlap) between documents to detect and remove duplicate documents containing similar contents [57, 64, 78, 216].” (Zhao et al., 2023, p. 18) 特别地,重复数据删除可以在不同的粒度上进行,包括句子级、文档级和数据集级重复数据删除。首先,应删除包含重复单词和短语的低质量句子,因为它们可能会在语言建模中引入重复模式[215]。在文档层面,现有研究主要依靠文档之间表面特征的重叠率(例如单词和n-gram重叠)来检测和删除包含相似内容的重复文档[57,64,78,216]。
“The majority of pre-training text data is obtained from web sources, including user-generated content involving sensitive or personal information, which may increase the risk of privacy breaches [218].” (Zhao et al., 2023, p. 18) 大多数预训练文本数据是从网络来源获得的,包括用户生成的涉及敏感或个人信息的内容,这可能会增加隐私泄露的风险[218]。
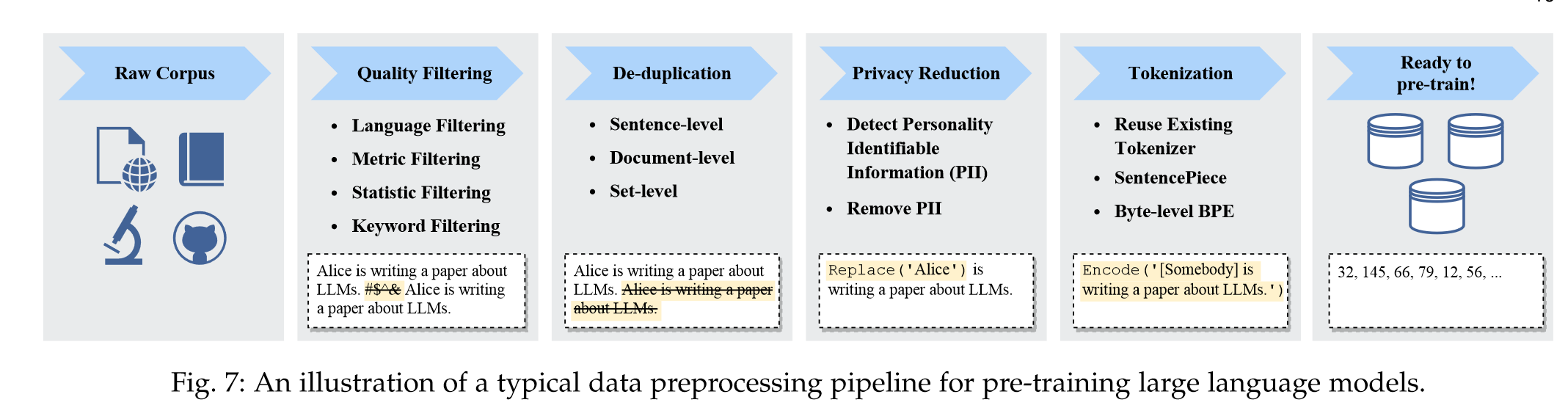
“Tokenization. Tokenization is also a crucial step for data preprocessing. It aims to segment raw text into sequences of individual tokens, which are subsequently used as the inputs of LLMs.” (Zhao et al., 2023, p. 19) 代币化。标记化也是数据预处理的关键步骤。它旨在将原始文本分割成单个标记的序列,这些标记随后用作 LLM 的输入。
“Recently, subword tokenizers have been widely used in Transformer based language models, typically including BytePair Encoding tokenization, WordPiece tokenization and Unigram tokenization.” (Zhao et al., 2023, p. 19) 最近,子词分词器已广泛应用于基于 Transformer 的语言模型中,通常包括 BytePair Encoding 分词器、WordPiece 分词器和 Unigram 分词器。
“For example, LLaMA trains the BPE tokenizer based on a pre-training corpus mainly consisting of English texts, and the derived vocabulary might be less capable in processing non-English data, e.g., taking longer inference latency to generate Chinese texts.” (Zhao et al., 2023, p. 19) 例如,LLaMA 基于主要由英语文本组成的预训练语料库来训练 BPE 分词器,而派生词汇在处理非英语数据方面可能较差,例如,需要较长的推理延迟才能生成中文文本。
“By comparing the performance of models trained on the filtered and unfiltered corpus, they have reached the similar conclusion that pre-training LLMs on cleaned data can improve the model performance. More specifically, the duplication of data may result in “double descent” (referring to the phenomenon of performance initially deteriorating and subsequently improving) [214, 228], or even overwhelm the training process [214].” (Zhao et al., 2023, p. 20) 通过比较在过滤和未过滤的语料库上训练的模型的性能,他们得出了类似的结论,即在清理后的数据上预训练 LLM 可以提高模型性能。更具体地说,数据的重复可能会导致“双重下降”(指性能最初恶化然后提高的现象)[214, 228],甚至压垮训练过程[214]。
“Therefore, as suggested in [56, 64, 78, 212], it is essential to utilize preprocessing methods like quality filtering, toxic filtering and deduplication to carefully clean the pre-training corpus (as illustrated in Section 4.1.2), to improve stability of the training process and avoid affecting the model performance.” (Zhao et al., 2023, p. 20) 因此,正如[56,64,78,212]中所建议的,有必要利用质量过滤、有毒过滤和重复数据删除等预处理方法来仔细清理预训练语料库(如第4.1.2节所示),以提高训练过程的稳定性,避免影响模型性能。
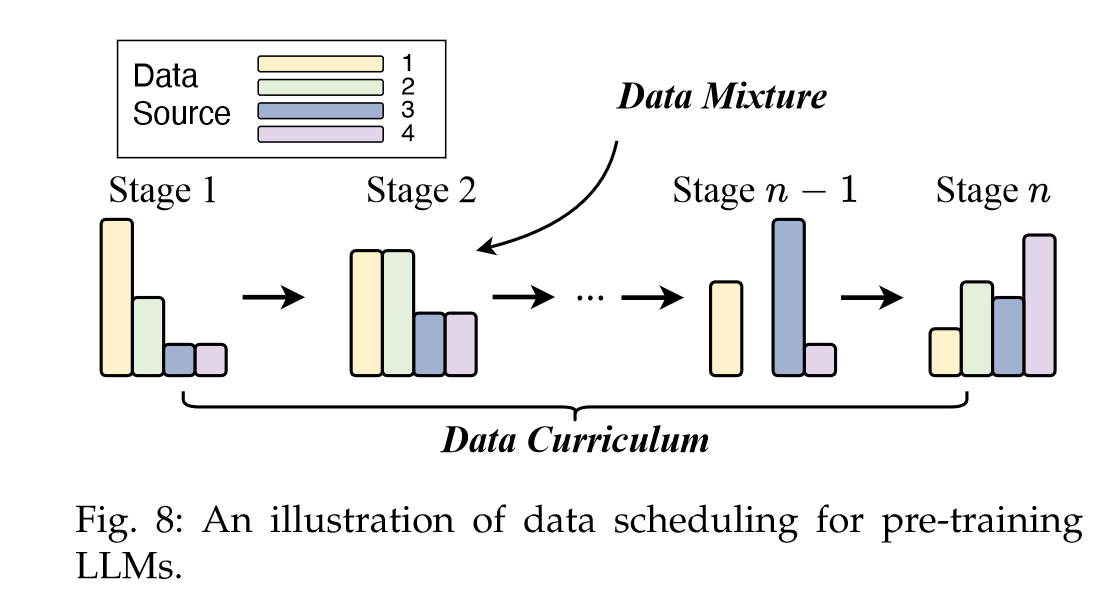
“After data preprocessing, it is essential to design suitable strategies to schedule these multi-source data for pretraining a capable LLM. Generally, two key aspects should be paid close attention for data scheduling: the proportion of each data source (data mixture), and the order in which each data source is scheduled for training (data curriculum).” (Zhao et al., 2023, p. 20) 在数据预处理之后,必须设计合适的策略来调度这些多源数据,以预训练一个有能力的 LLM。一般来说,数据调度需要重点关注两个关键方面:每个数据源的占比(数据混合),以及每个数据源调度训练的顺序(数据课程)。
“In practice, data mixture is often determined empirically, and we summarize several common strategies for finding an effective data mixture as follows:” (Zhao et al., 2023, p. 20) 在实践中,数据混合通常是根据经验确定的,我们总结了几种寻找有效数据混合的常见策略如下:
“Increasing the diversity of data sources. Recent studies have empirically shown that training on excessive data about a certain domain would degrade the generalization capability of LLMs on other domains [35, 64]. In contrast, increasing the data source heterogeneity (e.g., including diverse data sources) is critical for improving the downstream performance of LLMs [212, 229, 230].” (Zhao et al., 2023, p. 20) 增加数据源的多样性。最近的经验研究表明,对某个领域的过多数据进行训练会降低LLM在其他领域的泛化能力[35,64]。相比之下,增加数据源的异质性(例如,包括不同的数据源)对于提高LLM的下游性能至关重要[212,229,230]。
“Optimizing data mixtures. In addition to manually setting the data mixtures, several studies have proposed to optimize the data mixtures for improving the model pretraining [59, 231]. Given the target downstream tasks, one can select pre-training data with either higher proximity in the feature space [231] or those that provide positive influences on downstream task performance [232].” (Zhao et al., 2023, p. 20) 优化数据混合。除了手动设置数据混合之外,一些研究还提出优化数据混合以改进模型预训练[59, 231]。给定目标下游任务,我们可以选择在特征空间[231]中具有更高接近度的预训练数据,或者对下游任务性能产生积极影响的预训练数据[232]。
“Specializing the targeted abilities. The model capacities of LLMs heavily rely on data selection and mixture, and one can boost the proportions of specific data sources to enhance certain model abilities [64, 212].” (Zhao et al., 2023, p. 20) 专门化目标能力。LLM的模型能力很大程度上依赖于数据选择和混合,可以提高特定数据源的比例来增强某些模型的能力[64,212]。
“To enhance specific skills such as mathematics and coding in LLMs, or to develop specialized LLMs, a practical way is to employ a multi-stage training approach, e.g., general and skill-specific data can be scheduled at two consecutive stages.” (Zhao et al., 2023, p. 21) 为了提高LLM中的数学和编码等特定技能,或开发专门的LLM,一种实用的方法是采用多阶段训练方法,例如,一般和特定技能的数据可以安排在两个连续的阶段。
“After preparing the data mixture, it is important to schedule the order that specific data is presented to LLMs for pre-training. It has been shown that, in some cases, to learn a certain skill, learning in a skillset sequence (e.g., basic skills → target skill) outperforms direct learning from a corpus focused solely on the target skill [234, 235].” (Zhao et al., 2023, p. 21) 在准备好数据混合之后,重要的是要安排将特定数据呈现给 LLM 进行预训练的顺序。研究表明,在某些情况下,要学习某种技能,技能组合序列(例如,基本技能→目标技能)的学习优于仅针对目标技能的语料库中的直接学习[234,235]。
“Based on CodeLLaMA, Llemma is continually trained on mixtures of scientific papers, web data containing mathematical text and code (2T general tokens → 500B code-heavy tokens → 50∼200B math-heavy tokens).” (Zhao et al., 2023, p. 21) 基于 CodeLLaMA,Llemma 不断接受科学论文、包含数学文本和代码的网络数据的混合训练(2T 通用标记 → 500B 代码密集型标记 → 50∼200B 数学密集型标记)。
“Data collection. It is suggested to include diverse data sources in the pre-training data.” (Zhao et al., 2023, p. 21) 数据采集。建议在预训练数据中包含不同的数据源。
“Data cleaning. After data collection, it is crucial to clean the raw corpus to enhance its quality as possible. First, deduplication is commonly used in existing work [99, 141, 229]. Second, low-quality text, toxic content, and data with privacy concerns should be removed at different granularities (e.g., document, passage or sentence). In practice, both heuristic and classifier-based methods can be employed for quality and toxicity filtering (e.g., CCNet [241], fastText [242], and Data-Juicer [243]). Third, with the cleaned data, one can further unify or specify the format for pretraining data, and perform the tokenization by training the tokenizer on the filtered and deduplicated corpus with libraries like SentencePiece [226].” (Zhao et al., 2023, p. 21) 数据清理。数据收集后,清理原始语料库以尽可能提高其质量至关重要。首先,重复数据删除在现有工作中普遍使用[99,141,229]。其次,应以不同的粒度(例如文档、段落或句子)删除低质量文本、有毒内容和涉及隐私问题的数据。在实践中,启发式方法和基于分类器的方法都可以用于质量和毒性过滤(例如,CCNet [241]、fastText [242] 和 Data-Juicer [243])。第三,利用清理后的数据,我们可以进一步统一或指定预训练数据的格式,并通过使用 SentencePiece [226] 等库在过滤和去重的语料库上训练标记器来执行标记化。
“Data scheduling. With the preprocessed data, the next step is to determine the data mixture and the specific order of data for pre-training LLMs.” (Zhao et al., 2023, p. 21) 数据调度。有了预处理后的数据,下一步就是确定预训练 LLM 的数据混合和数据的具体顺序。
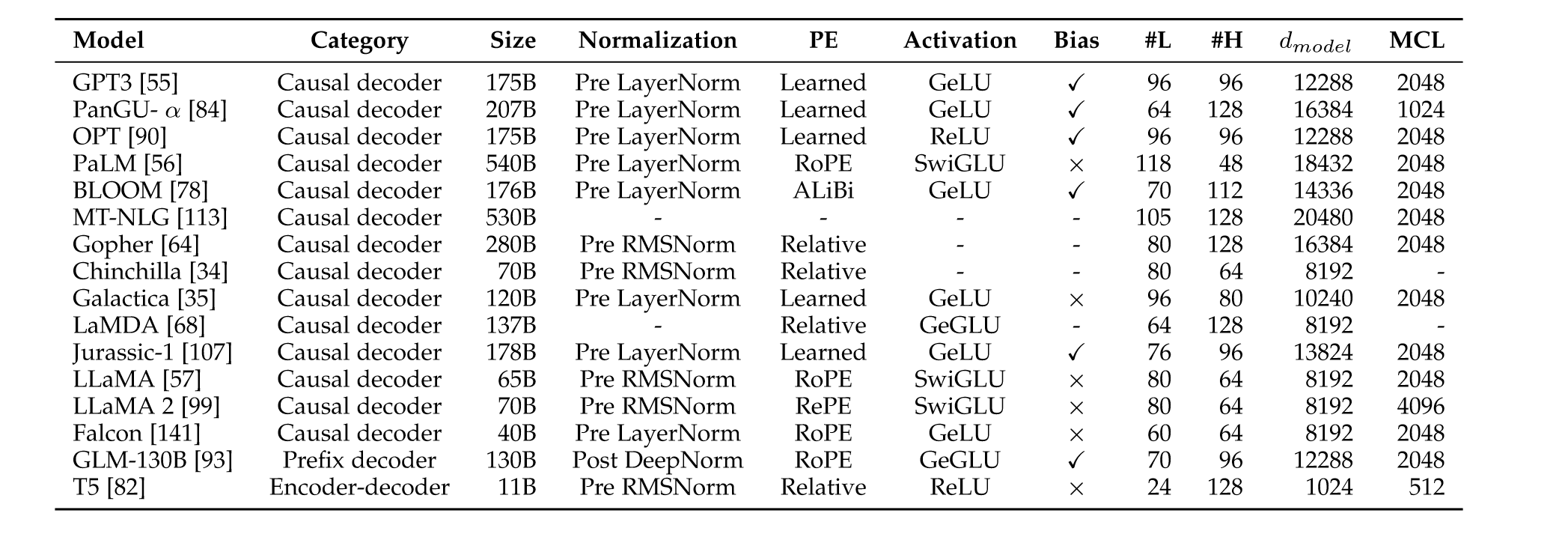
“In general, the mainstream architectures of existing LLMs can be roughly categorized into three major types, namely encoder-decoder, causal decoder, and prefix decoder, as shown in Figure 9.” (Zhao et al., 2023, p. 22) 总的来说,现有LLM的主流架构可以大致分为三大类,即编码器-解码器、因果解码器和前缀解码器,如图9所示。
“Prefix Decoder Architecture. The prefix decoder architecture (a.k.a., non-causal decoder [244]) revises the masking mechanism of causal decoders, to enable performing bidirectional attention over the prefix tokens [245] and unidirectional attention only on generated tokens.” (Zhao et al., 2023, p. 23) 前缀解码器架构。前缀解码器架构(又名非因果解码器[244])修改了因果解码器的屏蔽机制,以实现对前缀标记[245]执行双向注意,并仅对生成的标记执行单向注意。
“Recently, several advanced normalization techniques have been proposed as alternatives to LayerNorm, e.g., RMSNorm, and DeepNorm.” (Zhao et al., 2023, p. 23) 最近,已经提出了几种先进的归一化技术作为 LayerNorm 的替代方案,例如 RMSNorm 和 DeepNorm。
“RMSNorm. To improve the training speed of LayerNorm (LN), RMSNorm [257] is proposed by re-scaling the activations with only the root mean square (RMS) of the summed activations, instead of the mean and variance. Related research has demonstrated its superiority in training speed and performance on Transformer [266].” (Zhao et al., 2023, p. 23) RMS 范数。为了提高 LayerNorm (LN) 的训练速度,RMSNorm [257] 提出通过仅使用总激活的均方根 (RMS) 而不是均值和方差来重新缩放激活。相关研究证明了其在 Transformer 上训练速度和性能的优越性[266]。
“Post-LN. Post-LN is used in the vanilla Transformer [22], which is placed between residual blocks. However, existing work has found that the training of Transformers with post-LN tends to be instable due to the large gradients near the output layer [267].” (Zhao et al., 2023, p. 23) LN 后。后LN用于原版变压器[22],它被放置在残余块之间。然而,现有的研究发现,由于输出层附近的梯度很大,使用后LN的Transformer训练往往不稳定[267]。
“Pre-LN. Different from post-LN, pre-LN [268] is applied before each sub-layer, and an additional LN is placed before the final prediction. Compared with post-LN, the Transformers with pre-LN are more stable in training. However, it performs worse than the variants with post-LN [269]. Despite the decreasing performance, most LLMs still adopt pre-LN due to the training stability.” (Zhao et al., 2023, p. 23) 预 LN。与后 LN 不同,pre-LN [268] 在每个子层之前应用,并在最终预测之前放置一个额外的 LN。与后LN相比,前LN的Transformer在训练中更加稳定。然而,其表现不如LN后变异型[269]。尽管性能下降,但由于训练稳定性,大多数 LLM 仍然采用 pre-LN。
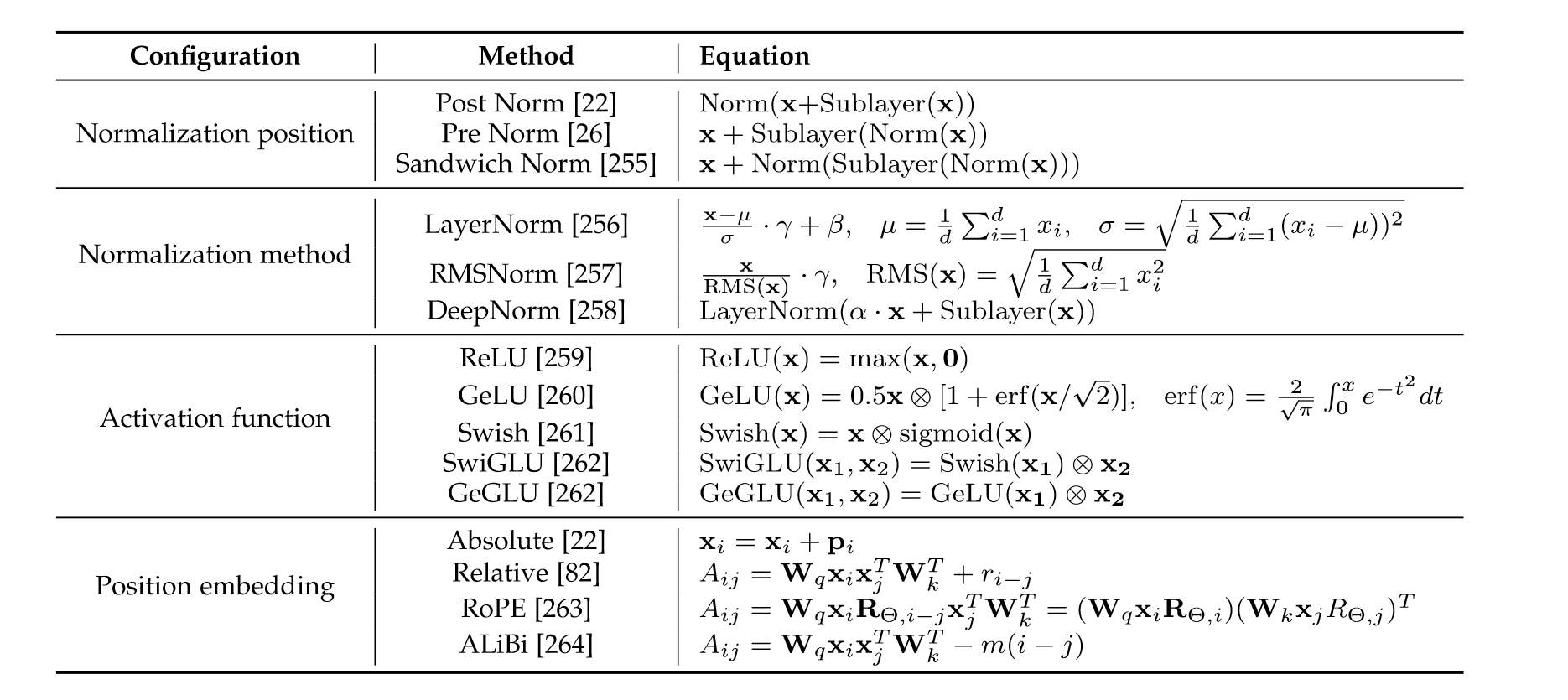
“In existing LLMs, GeLU activations [270] are widely used. Specially, in the latest LLMs (e.g., PaLM and LaMDA), variants of GLU activation [262, 271] have also been utilized, especially the SwiGLU and GeGLU variants, which often achieve better performance in practice [266]. However, compared with GeLU, they require extra parameters (about 50%) in the feed-forward networks [272].” (Zhao et al., 2023, p. 24) 在现有的LLM中,GeLU激活[270]被广泛使用。特别是在最新的LLM(例如PaLM和LaMDA)中,GLU激活的变体[262,271]也被使用,特别是SwiGLU和GeGLU变体,它们在实践中通常具有更好的性能[266]。然而,与GeLU相比,它们在前馈网络中需要额外的参数(约50%)[272]。
“Due to the excellent performance and the long-term decay property, RoPE is widely adopted in the latest LLMs, e.g., PaLM [56] and LLaMA [57].” (Zhao et al., 2023, p. 24) 由于其优异的性能和长期衰减特性,RoPE在最新的LLM中被广泛采用,例如PaLM [56]和LLaMA [57]。
“Sparse attention. A crucial challenge of full attention is the quadratic computational complexity, which becomes a burden when dealing with long sequences.” (Zhao et al., 2023, p. 25) 注意力稀疏。充分注意的一个关键挑战是二次计算复杂性,这在处理长序列时成为负担。
“Different from most existing approximate attention methods that trade-off model quality to improve the computing efficiency, FlashAttention [283] proposes to optimize the speed and memory consumption of attention modules on GPUs from an IO-aware perspective.” (Zhao et al., 2023, p. 25) 与大多数现有的权衡模型质量以提高计算效率的近似注意力方法不同,FlashAttention[283]提出从IO感知的角度优化GPU上注意力模块的速度和内存消耗。
“It has been observed when LLM are deployed on servers, GPU memory is largely occupied by cached attention key and value tensors (called KV cache). The major reason is that the input lengths are often varied, leading to fragmentation and over-reservation issues. Inspired by the classic paging technique in operating systems, PagedAttention has been proposed to improve the memory efficiency and throughput of deployed LLMs [285]. In detail, PagedAttention partitions each sequence into subsequences, and the corresponding KV caches of these subsequences are allocated into non-contiguous physical blocks. The paging technique increases the GPU utilization and enables efficient memory sharing in parallel sampling.” (Zhao et al., 2023, p. 25) 据观察,当 LLM 部署在服务器上时,GPU 内存主要被缓存的注意力键和值张量(称为 KV 缓存)占用。主要原因是输入长度经常变化,导致碎片和过度保留问题。受操作系统中经典分页技术的启发,PagedAttention被提出用于提高已部署LLM的内存效率和吞吐量[285]。具体来说,PagedAttention 将每个序列划分为子序列,并将这些子序列的相应 KV 缓存分配到非连续的物理块中。分页技术可提高 GPU 利用率,并在并行采样中实现高效的内存共享。
“For stronger generalization and training stability, it is suggested to choose the pre RMSNorm for layer normalization, and SwiGLU or GeGLU as the activation function. In addition, LN may not be used immediately after embedding layers, which is likely to incur performance degradation. As for position embeddings, RoPE or ALiBi is a better choice since it performs better on long sequences.” (Zhao et al., 2023, p. 25) 为了更强的泛化性和训练稳定性,建议选择pre RMSNorm进行层归一化,并选择SwiGLU或GeGLU作为激活函数。此外,LN 可能不会在嵌入层后立即使用,这可能会导致性能下降。至于位置嵌入,RoPE 或 ALiBi 是更好的选择,因为它在长序列上表现更好。
“An important variant of LM is the prefix language modeling task, which is designed for pre-training models with the prefix decoder architecture. The tokens within a randomly selected prefix would not be used in computing the loss of prefix language modeling. With the same amount of tokens seen during pretraining, prefix language modeling performs slightly worse than language modeling, since fewer tokens in the sequence are involved for model pre-training [29].” (Zhao et al., 2023, p. 25) LM 的一个重要变体是前缀语言建模任务,它是为具有前缀解码器架构的预训练模型而设计的。随机选择的前缀内的标记不会用于计算前缀语言建模的损失。在预训练期间看到的标记数量相同的情况下,前缀语言建模的表现比语言建模稍差,因为模型预训练涉及的序列中的标记较少[29]。

“To enhance the long context modeling abilities, there are generally two feasible directions, namely scaling position embeddings and adapting context window” (Zhao et al., 2023, p. 26) 为了增强长上下文建模能力,通常有两个可行的方向,即缩放位置嵌入和自适应上下文窗口
“However, as one of the mainstream position embedding methods, RoPE exhibits limited extrapolation ability in empirical studies [240].” (Zhao et al., 2023, p. 26) 然而,作为主流位置嵌入方法之一,RoPE在实证研究中表现出有限的外推能力[240]。
“Specially, some recent study has shown that the quality is more important than the lengths of training text in long context models [288]. However, a recent study has highlighted that the fine-tuning approach tends to be inherently slow when adapting LLMs for long texts [240].” (Zhao et al., 2023, p. 26) 特别是,最近的一些研究表明,在长上下文模型中,质量比训练文本的长度更重要[288]。然而,最近的一项研究强调,在将LLM改编为长文本时,微调方法往往固有地很慢[240]。
“Adapting Context Window. Since Transformer-based LLMs have limited context windows, they can not directly integrate or utilize the entire information of the long sequences exceeding the context window.” (Zhao et al., 2023, p. 27) 适应上下文窗口。由于基于 Transformer 的 LLM 的上下文窗口有限,因此它们无法直接集成或利用超过上下文窗口的长序列的全部信息。
“Parallel context window. Inspired by fusion-indecoder [294], parallel context window methods [295, 296] adopt a divide-and-conquer strategy to process input text. Specially, it divides the input text into multiple segments, each independently encoded with shared position embeddings. In the generation stage, the attention masks are modified to make that subsequent tokens can access to previous tokens in each segment. Nevertheless, this method cannot distinguish the order of different segments, constraining the model capacity on certain tasks.” (Zhao et al., 2023, p. 27) 并行上下文窗口。受融合解码器[294]的启发,并行上下文窗口方法[295, 296]采用分治策略来处理输入文本。特别地,它将输入文本分为多个片段,每个片段都使用共享位置嵌入进行独立编码。在生成阶段,修改注意力掩码以使后续令牌可以访问每个片段中的先前令牌。然而,该方法无法区分不同片段的顺序,限制了模型在某些任务上的能力。
“As another alternative decoding strategy, samplingbased methods are proposed to randomly select the next token based on the probability distribution to enhance the randomness and diversity during generation:” (Zhao et al., 2023, p. 27) 作为另一种替代解码策略,提出了基于采样的方法,根据概率分布随机选择下一个令牌,以增强生成过程中的随机性和多样性:
“Beam search. Beam search [309] retains the sentences with the n (beam size) highest probabilities at each step during the decoding process, and finally selects the generated response with the top probability. Typically, the beam size is configured within the range of 3 to 6.” (Zhao et al., 2023, p. 27) 光束搜索。波束搜索[309]在解码过程中,在每一步中保留具有n(波束大小)最高概率的句子,最后选择具有最高概率的生成响应。通常,光束尺寸配置在 3 到 6 的范围内。
“Besides, some researchers [312] propose to penalize the generation of previously generated tokens or n-grams to alleviate the issue of repetitive generation.” (Zhao et al., 2023, p. 28) 此外,一些研究人员[312]建议对先前生成的 token 或 n-gram 的生成进行惩罚,以缓解重复生成的问题。
“Top-p sampling. Since top-k sampling does not consider the overall possibility distribution, a constant value of k may be not be suitable for different contexts. Therefore, top-p sampling (a.k.a., nucleus sampling) is proposed by sampling from the smallest set having a cumulative probability above (or equal to) p [308]. In practice, the smallest set can be constructed by gradually adding tokens from the vocabulary sorted in descending order of generative probability, until their cumulative value exceeds p.” (Zhao et al., 2023, p. 28) Top-p 采样。由于top-k采样不考虑总体可能性分布,因此k的恒定值可能不适合不同的上下文。因此,top-p 采样(又名核采样)是通过从累积概率高于(或等于)p [308]的最小集合进行采样而提出的。在实践中,可以通过逐渐添加按生成概率降序排序的词汇表中的标记来构造最小集合,直到它们的累积值超过p。
“Since it has been found that large models tend to assign higher probability to important tokens compared to small models, contrastive decoding [318] utilizes a larger LM (e.g., OPT13B) and a smaller LM (e.g., OPT-125M) to measure their log-likelihood differences.” (Zhao et al., 2023, p. 28) 由于已经发现与小模型相比,大型模型倾向于为重要标记分配更高的概率,因此对比解码[318]利用较大的 LM(例如 OPT13B)和较小的 LM(例如 OPT-125M)来测量它们的日志- 可能性差异。
“Overall, the decoding process of LLMs can be divided into two stages for overhead analysis: (1) the prefill stage, which computes the hidden states of the input sequence, and (2) the incremental decoding stage, which generates a token and updates hidden states in an auto-regressive manner [321].” (Zhao et al., 2023, p. 28) 总的来说,LLM的解码过程可以分为两个阶段进行开销分析:(1)预填充阶段,计算输入序列的隐藏状态,(2)增量解码阶段,生成令牌并更新隐藏状态以自回归方式状态[321]。
“GPT-3 [55] employs beam search with a beam size of 4 and a length penalty of 0.6 for all generation tasks.” (Zhao et al., 2023, p. 29) GPT-3 [55] 对所有生成任务采用波束搜索,波束大小为 4,长度惩罚为 0.6。
“Alpaca [142] utilizes sampling-based strategies with top-k (k = 50), top-p (p = 0.9), and temperature of 0.7 for open-ended generation.” (Zhao et al., 2023, p. 29) Alpaca [142] 利用基于采样的策略,采用 top-k (k = 50)、top-p (p = 0.9) 和温度 0.7 进行开放式生成。
“LLaMA [57] applies diverse decoding strategies tailored to specific tasks. For instance, it employs the greedy search for question answering tasks while utilizes a sampling strategy with the temperature settings of 0.1 (pass@1) and 0.8 (pass@100) for code generation.” (Zhao et al., 2023, p. 29) LLaMA [57] 应用针对特定任务定制的多种解码策略。例如,它采用贪婪搜索来完成问答任务,同时采用温度设置为0.1(pass\@1)和0.8(pass\@100)的采样策略来生成代码。
“By pre-training with the LM objective, it seems that causal decoder architecture can achieve a superior zeroshot and few-shot generalization capacity. Existing research has shown that without multi-task fine-tuning, the causal decoder has better zero-shot performance than other architectures [29].” (Zhao et al., 2023, p. 29) 通过使用 LM 目标进行预训练,因果解码器架构似乎可以实现卓越的零样本和少样本泛化能力。现有研究表明,在没有多任务微调的情况下,因果解码器比其他架构具有更好的零样本性能[29]。
“For LLMs such as GPT-3 and PaLM, they have introduced a new strategy that dynamically increases the batch size during training, ultimately reaching a million scale. Specifically, the batch size of GPT-3 is gradually increasing from 32K to 3.2M tokens.” (Zhao et al., 2023, p. 30) 对于 GPT-3 和 PaLM 等 LLM,他们引入了一种新策略,可以在训练过程中动态增加批量大小,最终达到百万规模。具体来说,GPT-3的批量大小从32K逐渐增加到320万个代币。
“Learning Rate. Existing LLMs usually adopt a similar learning rate schedule with the warm-up and decay strategies during pre-training. Specifically, in the initial 0.1% to 0.5% of the training steps, a linear warm-up schedule is employed for gradually increasing the learning rate to the maximum value that ranges from approximately 5 × 10−5 to 1 × 10−4 (e.g., 6 × 10−5 for GPT-3). Then, a cosine decay strategy is adopted in the subsequent steps, gradually reducing the learning rate to approximately 10% of its maximum value, until the convergence of the training loss.” (Zhao et al., 2023, p. 30) 学习率。现有的 LLM 通常采用与预训练期间的热身和衰减策略类似的学习率时间表。具体来说,在最初的 0.1% 到 0.5% 的训练步骤中,采用线性预热计划将学习率逐渐提高到最大值,范围从大约 5 × 10−5 到 1 × 10−4(例如,GPT-3 为 6 × 10−5)。然后,在后续步骤中采用余弦衰减策略,逐渐将学习率降低到其最大值的10%左右,直到训练损失收敛。
“Optimizer. The Adam optimizer [328] and AdamW optimizer [329] are widely utilized for training LLMs (e.g., GPT3), which are based on adaptive estimates of lower-order moments for first-order gradient-based optimization.” (Zhao et al., 2023, p. 30) 优化器。 Adam 优化器 [328] 和 AdamW 优化器 [329] 被广泛用于训练 LLM(例如 GPT3),它们基于低阶矩的自适应估计,用于基于一阶梯度的优化。
“Meanwhile, the Adafactor optimizer [330] has also been utilized in training LLMs (e.g., PaLM and T5), which is a variant of the Adam optimizer specially designed for conserving GPU memory during training.” (Zhao et al., 2023, p. 30) 同时,Adafactor优化器[330]也被用于训练LLM(例如PaLM和T5),它是Adam优化器的变体,专门为在训练期间节省GPU内存而设计。
“Stabilizing the Training. During the pre-training of LLMs, it often suffers from the training instability issue, which may cause the model collapse. To address this issue, weight decay and gradient clipping have been widely utilized, where existing studies [55, 78, 90, 93, 113] commonly set the threshold of gradient clipping to 1.0 and weight decay rate to 0.1.” (Zhao et al., 2023, p. 30) 稳定训练。 LLM在预训练过程中,经常会遇到训练不稳定的问题,导致模型崩溃。为了解决这个问题,权重衰减和梯度裁剪被广泛使用,现有研究[55,78,90,93,113]通常将梯度裁剪的阈值设置为1.0,权重衰减率设置为0.1。
“To mitigate this problem, PaLM [56] and OPT [90] use a simple strategy that restarts the training process from an earlier checkpoint before the occurrence of the spike and skips over the data that may have caused the problem.” (Zhao et al., 2023, p. 30) 为了缓解这个问题,PaLM [56] 和 OPT [90] 使用一种简单的策略,从尖峰发生之前的较早检查点重新启动训练过程,并跳过可能导致问题的数据。
“3D Parallelism. 3D parallelism is actually a combination of three commonly used parallel training techniques, namely data parallelism, pipeline parallelism [331, 332], and tensor parallelism [75]24” (Zhao et al., 2023, p. 30) 3D 并行性。 3D并行实际上是三种常用并行训练技术的组合,即数据并行、管道并行[331, 332]和张量并行[75]24
“Data parallelism. Data parallelism is one of the most fundamental approaches to improving the training throughput. It replicates the model parameters and optimizer states across multiple GPUs and then distributes the whole training corpus into these GPUs. In this way, each GPU only needs to process the assigned data for it, and performs the forward and backward propagation to obtain the gradients. The computed gradients on different GPUs will be further aggregated to obtain the gradients of the entire batch for updating the models in all GPUs. I” (Zhao et al., 2023, p. 30) 数据并行性。数据并行是提高训练吞吐量的最基本方法之一。它跨多个 GPU 复制模型参数和优化器状态,然后将整个训练语料库分配到这些 GPU 中。这样,每个GPU只需要为其处理分配的数据,并进行前向和后向传播即可获得梯度。不同GPU上计算的梯度将被进一步聚合以获得整个批次的梯度,用于更新所有GPU中的模型。我
“Pipeline parallelism. Pipeline parallelism aims to distribute the different layers of a LLM into multiple GPUs. Especially, in the case of a Transformer model, pipeline parallelism loads consecutive layers onto the same GPU, to reduce the cost of transmitting the computed hidden states or gradients between GPUs. However, a naive implementation of pipeline parallelism may result in a lower GPU utilization rate as each GPU has to wait for the previous one to complete the computation, leading to the unnecessary cost of bubbles overhead [331].” (Zhao et al., 2023, p. 30) 流水线并行性。流水线并行性旨在将 LLM 的不同层分布到多个 GPU 中。特别是,在 Transformer 模型的情况水线并行性将连续层加载到同一个 GPU 上,以降低在 GPU 之间传输计算的隐藏状态或梯度的成本。然而,流水线并行性的幼稚实现可能会导致较低的GPU利用率,因为每个GPU都必须等待前一个GPU完成计算,从而导致不必要的气泡开销成本[331]。
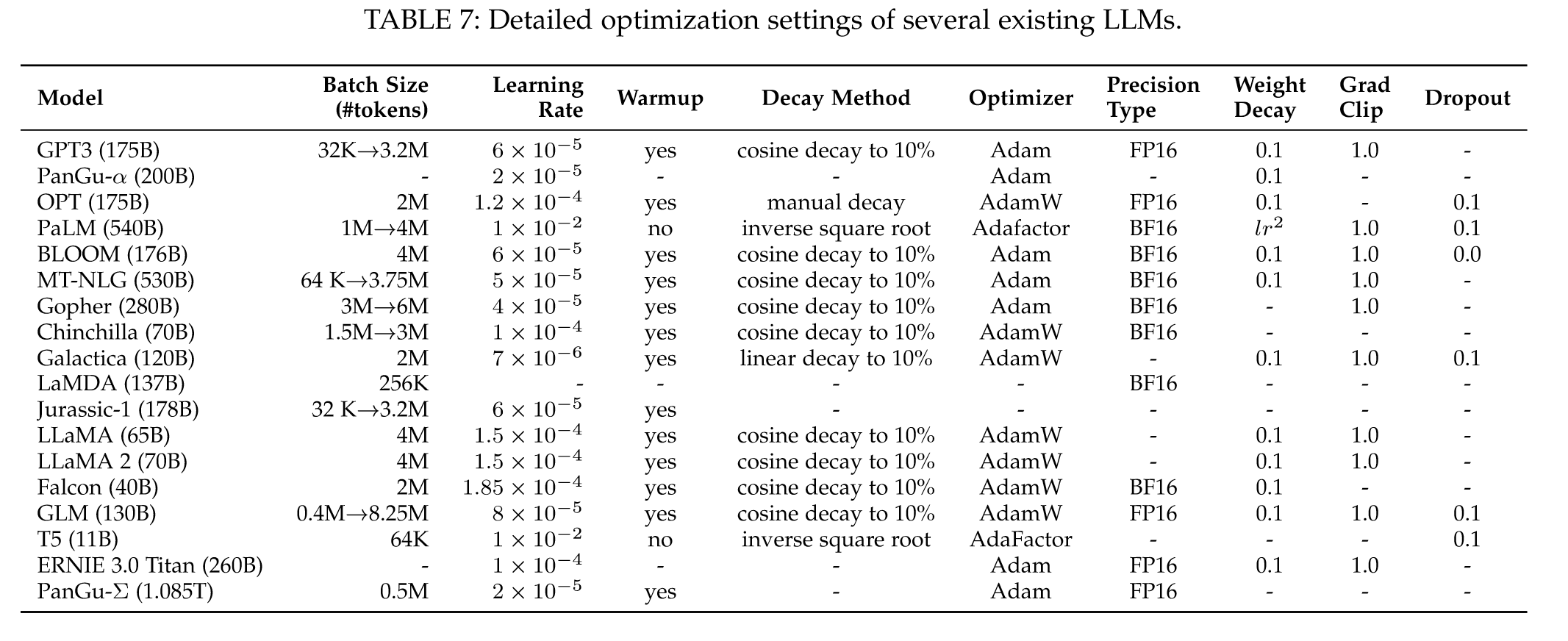
“Unlike pipeline parallelism, tensor parallelism focuses on decomposing the tensors (the parameter matrices) of LLMs. For a matrix multiplication operation Y = XA in the LLM, the parameter matrix A can be split into two submatrices, A1 and A2, by column, which can be expressed as Y = [XA1, XA2]. By placing matrices A1 and A2 on different GPUs, the matrix multiplication operation would be invoked at two GPUs in parallel, and the final result can be obtained by combining the outputs from the two GPUs through across-GPU communication.” (Zhao et al., 2023, p. 31) 与流水线并行不同,张量并行侧重于分解 LLM 的张量(参数矩阵)。对于 LLM 中的矩阵乘法运算 Y = XA,参数矩阵 A 可以按列拆分为两个子矩阵 A1 和 A2,可以表示为 Y = [XA1, XA2]。通过将矩阵 A1 和 A2 放置在不同的 GPU 上,可以在两个 GPU 上并行调用矩阵乘法运算,通过跨 GPU 通信组合两个 GPU 的输出,可以得到最终结果。
“To resolve it, the ZeRO technique aims to retain only a fraction of data on each GPU, while the rest data can be retrieved from other GPUs when required. Specifically, ZeRO provides three solutions, depending on how the three parts of the data are stored, namely optimizer state partitioning, gradient partitioning, and parameter partitioning.” (Zhao et al., 2023, p. 31) 为了解决这个问题,ZeRO 技术旨在在每个 GPU 上只保留一小部分数据,而其余数据可以在需要时从其他 GPU 中检索。具体来说,ZeRO 根据数据的三个部分的存储方式,提供了三种解决方案,即优化器状态分区、梯度分区和参数分区。
“In previous PLMs (e.g., BERT [23]), 32-bit floating-point numbers, also known as FP32, have been predominantly used for pre-training.” (Zhao et al., 2023, p. 31) 在以前的PLM(例如BERT [23])中,32位浮点数(也称为FP32)主要用于预训练。
“Additionally, as popular NVIDIA GPUs (e.g., A100) have twice the amount of FP16 computation units as FP32, the computational efficiency of FP16 can be further improved.” (Zhao et al., 2023, p. 31) 此外,由于流行的NVIDIA GPU(例如A100)的FP16计算单元数量是FP32的两倍,因此FP16的计算效率可以进一步提高。
“In this section, we introduce two major approaches to adapting pre-trained LLMs, namely instruction tuning and alignment tuning. The former approach mainly aims to enhance (or unlock) the abilities of LLMs, while the latter approach aims to align the behaviors of LLMs with human values or preferences.” (Zhao et al., 2023, p. 32) 在本节中,我们将介绍两种主要的方法来调整预训练的 LLM,即指令调优和对齐调优。前一种方法主要旨在增强(或解锁)LLM的能力,而后一种方法旨在使LLM的行为与人类价值观或偏好保持一致。
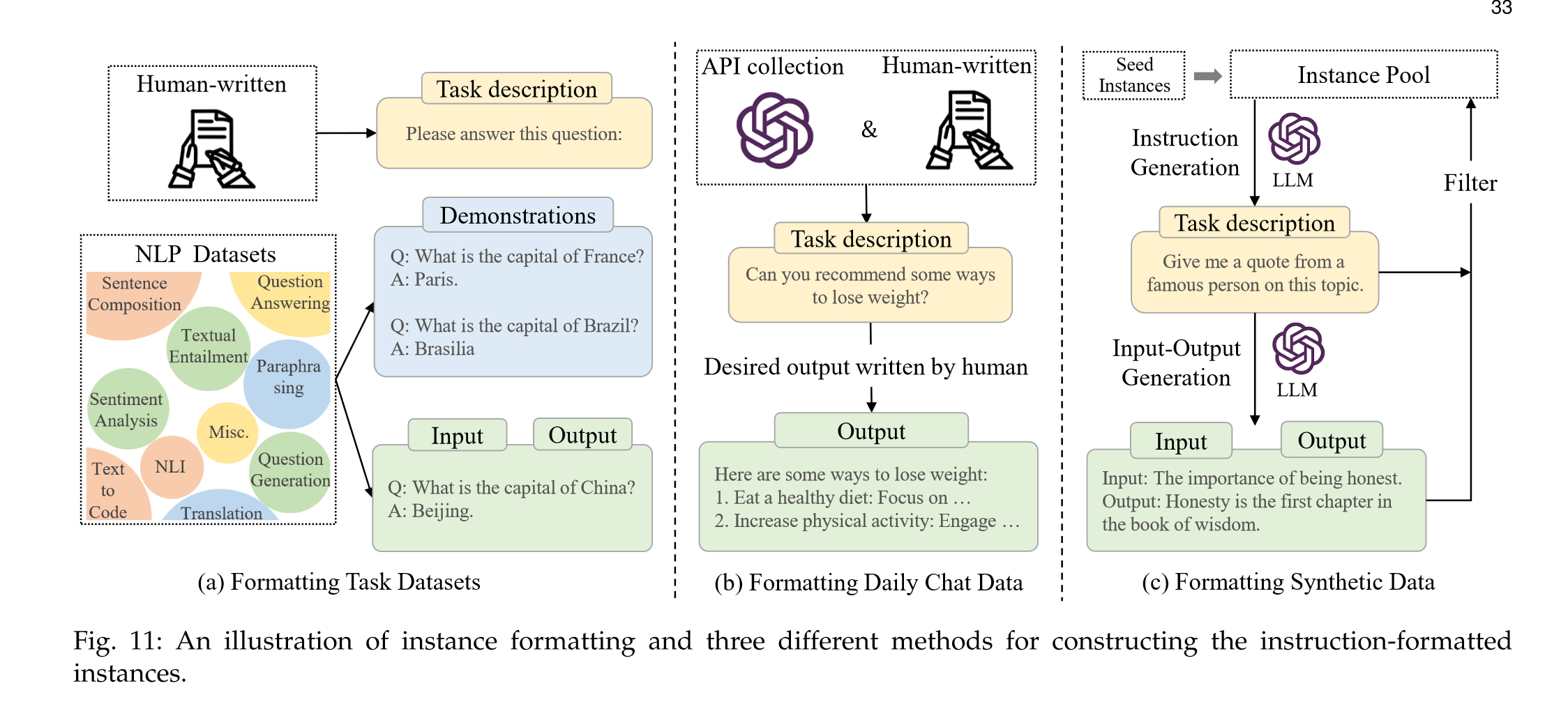
“Formatting NLP Task Datasets. Before instruction tuning was proposed, several early studies [168, 343, 344] collected the instances from a diverse range of traditional NLP tasks (e.g., text summarization, text classification, and translation) to create supervised multi-task training datasets. As a major source of instruction tuning instances, it is convenient to format these multi-task training datasets with natural language task descriptions.” (Zhao et al., 2023, p. 32) 格式化 NLP 任务数据集。在提出指令调优之前,一些早期研究[168,343,344]从各种传统的NLP任务(例如,文本摘要,文本分类和翻译)中收集实例,以创建监督的多任务训练数据集。作为指令调优实例的主要来源,使用自然语言任务描述来格式化这些多任务训练数据集非常方便。
“In particular, it has been shown that instructions are the crucial factor in task generalization ability for LLMs [67]: by fine-tuning the model on labeled datasets with the task descriptions removed, it results in a dramatic drop in model performance.” (Zhao et al., 2023, p. 32) 特别是,已经表明指令是LLM任务泛化能力的关键因素[67]:通过在删除任务描述的情况下对标记数据集的模型进行微调,会导致模型性能急剧下降。
“Formatting Daily Chat Data. Despite that a large number of training instances have been formatted with instructions, they mainly come from public NLP datasets, either lacking instruction diversity or mismatching with real human needs [66]. To overcome this issue, InstructGPT [66] proposes to take the queries that real users have submitted to the OpenAI API as the task descriptions.” (Zhao et al., 2023, p. 32) 格式化每日聊天数据。尽管有大量的训练实例被格式化为指令,但它们主要来自公共的NLP数据集,要么缺乏指令多样性,要么与人类的真实需求不匹配[66]。为了克服这个问题,InstructGPT [66] 建议将真实用户提交给 OpenAI API 的查询作为任务描述。
“Formatting Synthetic Data. To reduce the burden of human annotation or manual collection, several semi-automated approaches [143] have been proposed for constructing instances by feeding existing instances into LLMs to synthesize diverse task descriptions and instances.” (Zhao et al., 2023, p. 32) 格式化合成数据。为了减轻人工注释或手动收集的负担,已经提出了几种半自动化方法[143],通过将现有实例输入LLM来合成不同的任务描述和实例来构建实例。
“Scaling the instructions. It has been widely shown that scaling the number of tasks can largely enhance the generalization ability of LLMs [28, 67, 88]. With the increasing of the task number, the model performance initially shows a continuous growth pattern, while the gain becomes negligible when it reaches a certain level [69, 88]. A plausible speculation is that a certain number of representative tasks can provide relatively sufficient knowledge and adding more tasks may not bring additional gains [69].” (Zhao et al., 2023, p. 33) 缩放指令。研究表明,扩展任务数量可以在很大程度上增强LLM的泛化能力[28,67,88]。随着任务数的增加,模型性能最初呈现连续增长模式,而当达到一定水平时,增益变得可以忽略不计[69,88]。一个合理的推测是,一定数量的代表性任务可以提供相对足够的知识,增加更多的任务可能不会带来额外的收益[69]。
“Typically, we can add task descriptions and optional demonstrations to the inputoutput pairs of existing datasets, where the task description is the most key part for LLMs to understand the task [88].” (Zhao et al., 2023, p. 33) 通常,我们可以在现有数据集的输入输出对中添加任务描述和可选演示,其中任务描述是LLM理解任务的最关键部分[88]。
“To reduce human efforts, we can either reuse existing formatted datasets (Table 3) or automatically construct the instructions using existing LLMs [143].” (Zhao et al., 2023, p. 33) 为了减少人力,我们可以重用现有的格式化数据集(表3),或者使用现有的LLM自动构建指令[143]。
“Unlike pre-training, instruction tuning is often more efficient since only a moderate number of instances are used for training.” (Zhao et al., 2023, p. 34) 与预训练不同,指令调整通常更有效,因为只有适量的实例用于训练。
“Balancing the Data Distribution. Since instruction tuning involves a mixture of different tasks, it is important to balance the proportion of different tasks during finetuning. A widely used method is the examples-proportional mixing strategy [82], i.e., combining all the datasets and sampling each instance equally from the mixed datasets.” (Zhao et al., 2023, p. 34) 平衡数据分布。由于指令调优涉及不同任务的混合,因此在微调过程中平衡不同任务的比例非常重要。一种广泛使用的方法是示例比例混合策略[82],即将所有数据集组合在一起,并从混合数据集中平均采样每个实例。
“Therefore, it is often suggested to use a mixture of existing instruction datasets to achieve a balanced improvement in different capacities, including NLP task data (e.g., FLAN v2 [292]), chat data (e.g., ShareGPT [148]), and synthetic data (e.g., GPT4-Alpaca [354]).” (Zhao et al., 2023, p. 34) 因此,通常建议混合使用现有的指令数据集来实现不同能力的平衡改进,包括NLP任务数据(例如,FLAN v2 [292])、聊天数据(例如,ShareGPT [148])和合成数据(例如,GPT4-Alpaca [354])。
“Combining Instruction Tuning and Pre-Training. To make the tuning process more effective and stable, OPT-IML [95] incorporates pre-training data during instruction tuning, which can be regarded as regularization for model tuning.” (Zhao et al., 2023, p. 34) 结合指令调整和预培训。为了使调优过程更加有效和稳定,OPT-IML[95]在指令调优过程中加入了预训练数据,可以看作是模型调优的正则化。
“Multi-stage Instruction Tuning. For instruction tuning, there are two kinds of important instruction data, namely task-formatted instructions and daily chat instructions. Generally, the former has a significantly larger volume than the latter. It is important to balance the training with the two kinds of instruction data.” (Zhao et al., 2023, p. 34) 多级指令调优。对于指令调优,有两种重要的指令数据,即任务格式化的指令和日常聊天指令。一般来说,前者的体积明显大于后者。在训练与两种指令数据之间取得平衡是很重要的。
“Establishing self-identification for LLM. To deploy LLMs for real-world applications, it is necessary to establish its identity and make LLMs aware of these identity information, such as name, developer and affiliation.” (Zhao et al., 2023, p. 34) 建立LLM的自我认同。为了为实际应用程序部署 LLM,有必要建立其身份,并使 LLM 了解这些身份信息,例如名称、开发人员和隶属关系。
“Performance Improvement. Despite being tuned on a moderate number of instances, instruction tuning has become an important way to improve or unlock the abilities of LLMs [69].” (Zhao et al., 2023, p. 34) 性能改进。尽管在适度数量的实例上进行了调优,但指令调优已成为提高或解锁LLM能力的重要方法[69]。
“In practice, instruction tuning offers a general approach to enhancing the abilities of existing language models [69] (including small-sized PLMs). Also, it is much less costly than pretraining, since the amount of instruction data required by LLMs is significantly smaller than pre-training data.” (Zhao et al., 2023, p. 35) 在实践中,指令调优提供了一种增强现有语言模型能力的通用方法[69](包括小型PLM)。此外,它比预训练的成本要低得多,因为 LLM 所需的指令数据量明显小于预训练数据。
“Task Generalization. Instruction tuning encourages the model to understand natural language instructions for task completion. It endows LLMs with the ability (often considered as an emergent ability) to follow human instructions [31] to perform specific tasks without demonstrations, even on unseen tasks [69].” (Zhao et al., 2023, p. 35) 任务泛化。指令调优鼓励模型理解自然语言指令以完成任务。它赋予LLMs遵循人类指令的能力(通常被认为是一种紧急能力)[31],无需演示即可执行特定任务,即使是在看不见的任务上[69]。
“Also, instruction tuning has been shown to be useful in alleviating several weaknesses of LLMs (e.g., repetitive generation or complementing the input without accomplishing a certain task) [66, 69], leading to a superior capacity to solve real-world tasks for LLMs. Furthermore, LLMs trained with instruction tuning can generalize to related tasks across languages.” (Zhao et al., 2023, p. 35) 此外,指令调优已被证明有助于缓解LLM的几个弱点(例如,重复生成或补充输入而不完成特定任务)[66,69],从而为LLM解决现实世界的任务提供了卓越的能力。此外,通过指令调优训练的 LLM 可以泛化到跨语言的相关任务。
“Instruction tuning is an effective approach to adapting existing general LLMs to be domain-specific experts.” (Zhao et al., 2023, p. 35) 指令调优是一种有效的方法,可以使现有的通用LLM适应为特定领域的专家。
“Task-specific instructions. For the first type of instructions, we adopt the most commonly-used multi-task instruction dataset, FLAN-T5 [69], which contains 1,836 tasks and over 15M instructions by combining four data mixtures from prior work.” (Zhao et al., 2023, p. 35) 特定于任务的说明。对于第一类指令,我们采用了最常用的多任务指令数据集FLAN-T5 [69],该数据集包含1,836个任务和超过15M条指令,结合了前期工作的四个数据组合。
“Enhancing the instruction complexity. As discussed in existing work [346], enhancing the complexity of instructions can improve the model capacity of LLMs in following complex instructions, e.g., including more task demands or requiring more reasoning steps.” (Zhao et al., 2023, p. 36) 提高指令的复杂性。正如现有工作[346]所讨论的,增强指令的复杂性可以提高LLM在遵循复杂指令时的模型能力,例如,包括更多的任务需求或需要更多的推理步骤。
“Increasing the topic diversity. In addition to the complexity, improving the topic diversity of the instruction dataset can help elicit different abilities of LLMs on diverse tasks in real world [347].” (Zhao et al., 2023, p. 36) 增加主题的多样性。除了复杂性之外,提高指令数据集的主题多样性还有助于激发LLM在现实世界中不同任务上的不同能力[347]。
“Scaling the instruction number. In addition to the above aspects, the number of instructions is also an important factor that may affect the model performance.” (Zhao et al., 2023, p. 36) 缩放指令编号。除了上述方面外,指令数量也是可能影响模型性能的重要因素。
“Balancing the instruction difficulty. As the synthetic instructions tend to contain too easy or too hard ones, it is likely to result in training instability or even overfitting for LLMs. To explore the potential effects, we leverage the perplexity score of LLMs to estimate the difficulty of instructions and remove too easy or too hard instructions.” (Zhao et al., 2023, p. 36) 平衡教学难度。由于合成指令往往包含太简单或太难的指令,这可能会导致 LLM 的训练不稳定甚至过度拟合。为了探索潜在的影响,我们利用LLM的困惑度评分来估计指令的难度,并删除太简单或太难的指令。
“For LLMs, the language modeling objective pre-trains the model parameters by word prediction while lacking the consideration of human values or preferences. To avert these unexpected behaviors, human alignment has been proposed to make LLMs act in line with human expectations [66, 367].” (Zhao et al., 2023, p. 38) 对于LLM,语言建模目标通过词预测对模型参数进行预训练,而缺乏对人类价值观或偏好的考虑。为了避免这些意外行为,有人提出人类对齐,使LLM的行为符合人类的期望[66,367]。
“However, unlike the original pre-training and adaptation tuning (e.g., instruction tuning), such an alignment requires considering very different criteria (e.g., helpfulness, honesty, and harmlessness). It has been shown that alignment might harm the general abilities of LLMs to some extent, which is called alignment tax in related literature [368].” (Zhao et al., 2023, p. 38) 然而,与最初的预训练和适应调整(例如,指令调整)不同,这种调整需要考虑非常不同的标准(例如,帮助性、诚实性和无害性)。研究表明,对齐可能会在一定程度上损害LLM的一般能力,这在相关文献中被称为对齐税[368]。
“During the pre-training stage, LLMs are trained using the language modeling objective on a large-scale corpus. However, it cannot take into account the subjective and qualitative evaluations of LLM outputs by humans (called human feedback in this survey).” (Zhao et al., 2023, p. 38) 在预训练阶段,LLM 使用语言建模目标在大规模语料库上进行训练。但是,它不能考虑人类对 LLM 输出的主观和定性评估(在本调查中称为人类反馈)。
“Human Labeler Selection. In existing work, the dominant method for generating human feedback data is human annotation [66, 116, 367].” (Zhao et al., 2023, p. 38) 人工贴标机选择。在现有工作中,生成人类反馈数据的主要方法是人类注释[66,116,367]。
“Even then, several studies [367] have found that there still exists a mismatch between the intentions of researchers and human labelers, which may lead to low-quality human feedback and cause LLMs to produce unexpected output.” (Zhao et al., 2023, p. 38) 即便如此,一些研究[367]发现研究人员和人类标签者的意图之间仍然存在不匹配,这可能会导致低质量的人类反馈并导致法学硕士产生意想不到的输出。
“To address this issue, InstructGPT [66] further conducts a screening process to filter labelers by assessing the agreement between human labelers and researchers. Specifically, researchers first label a small amount of data and then measure the agreement between themselves and human labelers. The labelers with the highest agreement will be selected to proceed with the subsequent annotation work. In some other work [370], “super raters” are used to ensure the high quality of human feedback. Researchers evaluate the performance of human labelers and select a group of well-performing human labelers (e.g., high agreement) as super raters.” (Zhao et al., 2023, p. 38) 为了解决这个问题,InstructGPT [66]通过评估人类贴标者和研究人员之间的协议,进一步进行筛选过程来过滤贴标者。具体来说,研究人员首先标记少量数据,然后测量自己与人类标记者之间的一致性。将选择一致性最高的标注者来进行后续标注工作。在其他一些工作中[370],“超级评估者”被用来确保人类反馈的高质量。研究人员评估人类贴标者的表现,并选择一组表现良好的人类贴标者(例如高度一致性)作为超级评估者。
“Ranking-based approach. In early work [367], human labelers often evaluate model-generated outputs in a coarsegrained manner (i.e., only selecting the best) without taking into account more fine-grained alignment criteria.” (Zhao et al., 2023, p. 39) 基于排名的方法。在早期工作中[367],人类标记者通常以粗粒度的方式评估模型生成的输出(即仅选择最佳的),而不考虑更细粒度的对齐标准。
“To address this issue, subsequent studies [116] introduce the Elo rating system to derive the preference ranking by comparing candidate outputs. The ranking of outputs serves as the training signal that guides the model to prefer certain outputs over others, thus inducing outputs that are more reliable and safer.” (Zhao et al., 2023, p. 39) 为了解决这个问题,后续研究[116]引入了Elo评级系统,通过比较候选输出来得出偏好排名。输出的排名充当训练信号,引导模型优先选择某些输出而不是其他输出,从而产生更可靠、更安全的输出。
“Question-based approach. Further, human labelers can provide more detailed feedback by answering certain questions designed by researchers [81], covering the alignment criteria as well as additional constraints for LLMs.” (Zhao et al., 2023, p. 39) 基于问题的方法。此外,人类贴标签者可以通过回答研究人员设计的某些问题来提供更详细的反馈[81],涵盖对齐标准以及法学硕士的额外限制。
“Rule-based approach. Many studies also develop rulebased methods to provide more detailed human feedback.” (Zhao et al., 2023, p. 39) 基于规则的方法。许多研究还开发了基于规则的方法来提供更详细的人类反馈。
“Furthermore, GPT-4 [46] utilizes a set of zero-shot classifiers (based on GPT-4 itself) as rule-based reward models, which can automatically determine whether the model-generated outputs violate a set of human-written rules.” (Zhao et al., 2023, p. 39) 此外,GPT-4[46]利用一组零样本分类器(基于GPT-4本身)作为基于规则的奖励模型,它可以自动确定模型生成的输出是否违反一组人类编写的规则。
“RLHF employs reinforcement learning (RL) algorithms (e.g., Proximal Policy Optimization (PPO) [128]) to adapt LLMs to human feedback by learning a reward model. Such an approach incorporates humans in the training loop for developing well-aligned LLMs, as exemplified by InstructGPT [66].” (Zhao et al., 2023, p. 39) RLHF 采用强化学习 (RL) 算法(例如,近端策略优化 (PPO) [128]),通过学习奖励模型来使 LLM 适应人类反馈。这种方法将人类纳入培训循环中,以开发协调一致的法学硕士,如 InstructGPT [66] 所示。
“RLHF System. The RLHF system mainly comprises three key components: a pre-trained LM to be aligned, a reward model learning from human feedback, and a RL algorithm training the LM.” (Zhao et al., 2023, p. 39) RLHF 系统。 RLHF 系统主要包含三个关键组件:要对齐的预训练 LM、从人类反馈中学习的奖励模型以及训练 LM 的 RL 算法。
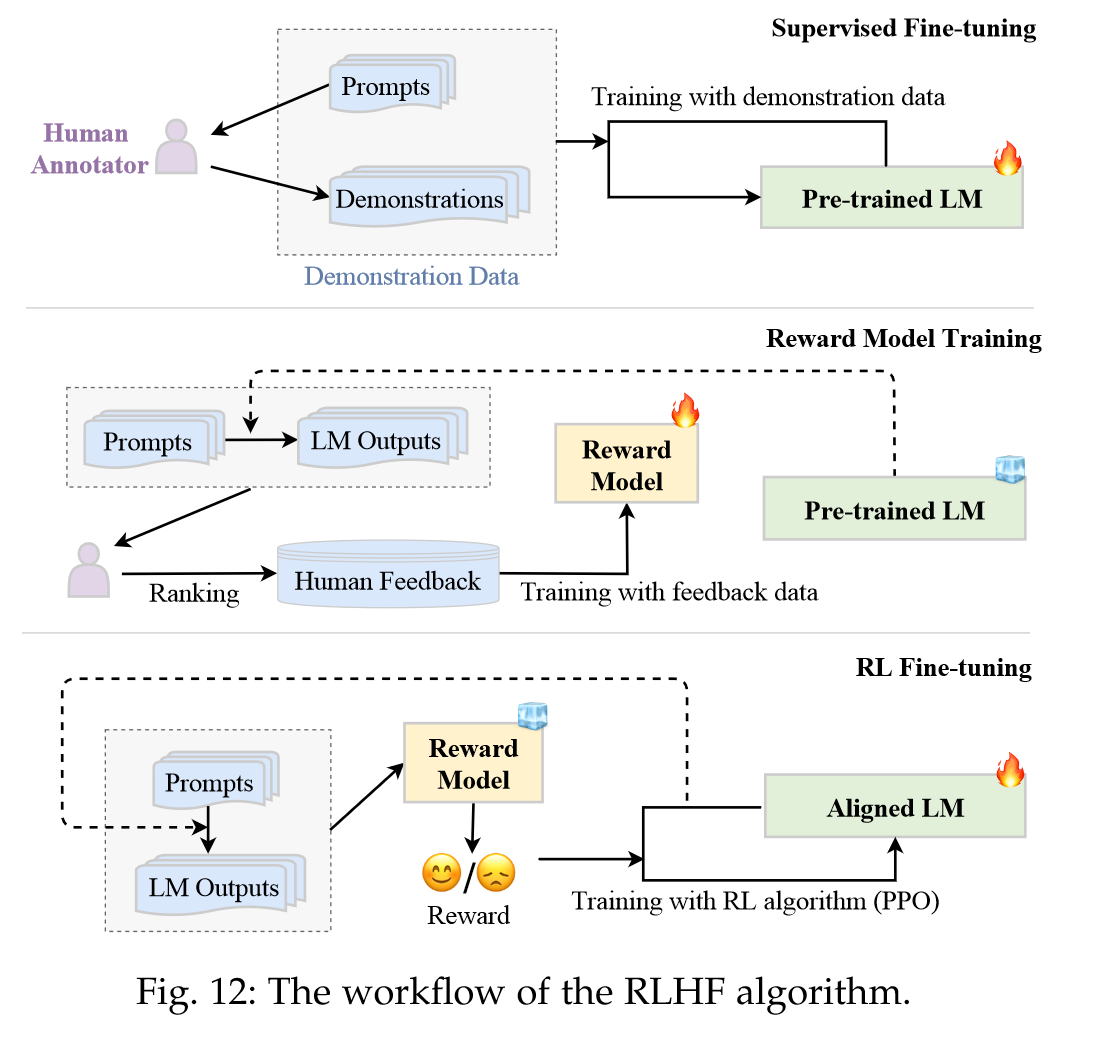
“Supervised fine-tuning. To make the LM initially perform desired behaviors, it usually needs to collect a supervised dataset containing input prompts (instruction) and desired outputs for fine-tuning the LM.” (Zhao et al., 2023, p. 39) 监督微调。为了使 LM 最初执行所需的行为,通常需要收集一个监督数据集,其中包含输入提示(指令)和用于微调 LM 的所需输出。
“Reward model training. The second step is to train the RM using human feedback data.” (Zhao et al., 2023, p. 39) 奖励模型训练。第二步是使用人类反馈数据训练 RM。
“The annotation process can be conducted in multiple forms, and a common approach is to annotate by ranking the generated candidate texts, which can reduce the inconsistency among annotators.” (Zhao et al., 2023, p. 40) 标注过程可以通过多种形式进行,常见的做法是通过对生成的候选文本进行排序来进行标注,这样可以减少标注者之间的不一致。
“RL fine-tuning. At this step, aligning (i.e., fine-tuning) the LM is formalized as an RL problem. In this setting, the pre-trained LM acts as the policy that takes as input a prompt and returns an output text, the action space of it is the vocabulary, the state is the currently generated token sequence, and the reward is provided by the RM.” (Zhao et al., 2023, p. 40) RL 微调。在此步骤中,对齐(即微调)LM 被形式化为 RL 问题。在此设置中,预训练的 LM 作为策略,以提示作为输入并返回输出文本,其动作空间是词汇表,状态是当前生成的令牌序列,奖励由R M。
“In LLaMa 2 [99], pretrained chat model checkpoints are used to initialize the reward model, they argue that such an approach can effectively reduce the information mismatch between the model to be aligned and the reward model by sharing the same pre-training knowledge.” (Zhao et al., 2023, p. 40) 在LLaMa 2 [99]中,预训练的聊天模型检查点被用来初始化奖励模型,他们认为这种方法可以通过共享相同的预训练知识来有效减少待对齐模型和奖励模型之间的信息不匹配。
“Effective RL training. As the RL training process tends to be unstable and hyper-parameter sensitive, it is suggested that the language model should be well supervised finetuned before RL training, so as to reaching a good model capacity.” (Zhao et al., 2023, p. 40) 有效的强化学习训练。由于强化学习训练过程往往不稳定且超参数敏感,建议在强化学习训练之前对语言模型进行良好的监督微调,以达到良好的模型能力。
“As a practical trick, we can deploy the reward model on a separate server, and invoke the corresponding API to work with the LLM on its own server. In addition, as RLHF requires the LLM to generate multiple candidate outputs, instead of calling the sample decoding procedure for multiple times, it is more efficient to utilize the beam search decoding algorithm26.” (Zhao et al., 2023, p. 41) 作为一个实用的技巧,我们可以将奖励模型部署在单独的服务器上,并调用相应的 API 来与自己服务器上的 LLM 一起工作。此外,由于 RLHF 需要 LLM 生成多个候选输出,因此使用波束搜索解码算法比多次调用样本解码过程更有效。
“In existing literature of RLHF [376], the supervision signals for RL training can be generally classified into two distinct categories: outcomesupervision signals and process-supervision signals.” (Zhao et al., 2023, p. 41) 在 RLHF [376] 的现有文献中,RL 训练的监督信号通常可以分为两个不同的类别:结果监督信号和过程监督信号。
“The basic idea of non-RL alignment approaches is to directly fine-tune LLMs with supervised learning on high-quality alignment dataset. It basically assumes that response feedback or golden rules to avert unsafe behaviors have been injected or included in the specially curated alignment dataset, so that LLMs can directly learn aligned behaviors from these demonstration data via suitable fine-tuning strategies.” (Zhao et al., 2023, p. 41) 非强化学习对齐方法的基本思想是通过高质量对齐数据集的监督学习来直接微调 LLM。它基本上假设避免不安全行为的响应反馈或黄金规则已被注入或包含在专门策划的对齐数据集中,以便法学硕士可以通过适当的微调策略直接从这些演示数据中学习对齐行为。
“Reward model based approaches. The reward model in RLHF has been trained to measure the alignment degree on the responses of LLMs. It is straightforward to leverage existing reward models to select high-quality responses as alignment data for subsequent fine-tuning.” (Zhao et al., 2023, p. 41) 基于奖励模型的方法。 RLHF 中的奖励模型经过训练可以衡量法学硕士响应的一致性程度。利用现有的奖励模型来选择高质量的响应作为后续微调的对齐数据非常简单。
“As valuable resources for aligning LLMs, several reward models have been released, including DeBERTa” (Zhao et al., 2023, p. 41) 作为调整法学硕士的宝贵资源,已经发布了多种奖励模型,包括 DeBERTa
“42 base/large/xxlarge from OpenAssistant27, Moss-7B from Fudan28, and Flan-T5-xl from Stanford29.” (Zhao et al., 2023, p. 42) 来自 OpenAssistant27 的 42 base/large/xxlarge、来自 Fudan28 的 Moss-7B 和来自斯坦福29 的 Flan-T5-xl。
“LLM based generative approaches. Reward models help to select aligned data from model responses. However, training reward models itself necessitates substantial highquality human-labeled data, which is typically expensive and in short supply.” (Zhao et al., 2023, p. 42) 基于法学硕士的生成方法。奖励模型有助于从模型响应中选择一致的数据。然而,训练奖励模型本身需要大量高质量的人工标记数据,而这些数据通常价格昂贵且供应短缺。
“LLM based interactive approaches. Most existing approaches train LLMs in isolation, where LLMs are not present in actual environments to improve themselves through external feedback signals.” (Zhao et al., 2023, p. 42) 基于法学硕士的互动方法。大多数现有方法都是孤立地训练法学硕士,而法学硕士并不存在于实际环境中,无法通过外部反馈信号来提高自己。
“Supervised Alignment Tuning. After obtaining alignment data, it is also key to design suitable fine-tuning strategies for direct alignment. A straightforward approach is to optimize LLMs using the conventional sequence-to-sequence objective based on the alignment data.” (Zhao et al., 2023, p. 42) 监督对准调整。获得比对数据后,设计合适的直接比对微调策略也是关键。一种直接的方法是使用基于比对数据的传统序列到序列目标来优化 LLM。
“Auxiliary optimization objectives. Besides the primary cross-entropy loss, several studies propose auxiliary training loss to enhance the learning from the alignment data. First, since the responses of each instruction can be scored by the reward model, the ranking loss can be used to train the model to preserve the ranking order of these responses.” (Zhao et al., 2023, p. 42) 辅助优化目标。除了主要的交叉熵损失之外,一些研究还提出了辅助训练损失来增强对对齐数据的学习。首先,由于奖励模型可以对每条指令的响应进行评分,因此可以使用排名损失来训练模型以保留这些响应的排名顺序。
“At early exploration, instruction data was mainly collected from NLP tasks [67], while it has been now extended to more diverse supervision data that pairs input and output texts (e.g., the utterances of open-ended dialogues). Training with such paired texts is also called supervised finetuning (SFT) in the context of LLMs [66].” (Zhao et al., 2023, p. 42) 在早期探索中,指令数据主要从 NLP 任务中收集[67],而现在已扩展到将输入和输出文本配对的更多样化的监督数据(例如开放式对话的话语)。在法学硕士[66]的背景下,使用这种配对文本进行训练也称为监督微调(SFT)。
“Overall, RLHF and SFT can be considered as two different training approaches to optimizing the above decision making process for LLMs. Specially, RLHF firstly learns the reward model, and then employs it to improve the LLM with RL training (e.g., PPO). As a comparison, SFT adopts a teacher-forcing approach, which directly optimizes the likelihood of a demonstration output. Such a token-level training way essentially does behavior cloning (a special algorithm of imitation learning [393]): it utilizes the expert’s action (i.e., the target token at each step) as the supervision label and directly learns to imitate the demonstrations from experts without specifying a reward model as in typical RL algorithms. To learn the desired policies, SFT adopts a “local” optimization way (i.e., tokenlevel loss) based on demonstration data, while RLHF takes a “global” optimization way (i.e., text-level loss) by involving human preference.” (Zhao et al., 2023, p. 43) 总体而言,RLHF 和 SFT 可以被视为优化上述 LLM 决策过程的两种不同的培训方法。特别地,RLHF首先学习奖励模型,然后用它来通过RL训练来改进LLM(例如,PPO)。相比之下,SFT 采用教师强制的方法,直接优化演示输出的可能性。这种令牌级别的训练方式本质上是行为克隆(模仿学习的一种特殊算法[393]):它利用专家的动作(即每一步的目标令牌)作为监督标签,直接学习模仿来自专家无需像典型的 RL 算法那样指定奖励模型。为了学习所需的策略,SFT 采用基于演示数据的“局部”优化方式(即令牌级损失),而 RLHF 采用涉及人类偏好的“全局”优化方式(即文本级损失)。
“It has been widely recognized that SFT mainly unlocks the abilities but not inject new abilities into LLMs. Thus, it might become problematic when one tries to stimulate the non-endogenous abilities of LLMs via SFT.” (Zhao et al., 2023, p. 43) 人们普遍认为,SFT主要是解锁LLM的能力,而不是为LLM注入新的能力。因此,当试图通过 SFT 激发法学硕士的非内生能力时,可能会出现问题。
“As a concrete scenario, it would potentially advocate the hallucination behaviors when demonstration data is beyond the knowledge or ability scope of LLMs, e.g., training a LLM to answer questions about its unknown facts.” (Zhao et al., 2023, p. 43) 作为一个具体场景,当演示数据超出法学硕士的知识或能力范围时,它可能会提倡幻觉行为,例如训练法学硕士回答有关其未知事实的问题。
“First, since human annotators mainly provide preference annotations for RLHF, it can largely alleviate the discrepancies of annotators as that in SFT. Secondly, preference annotation is much easier than writing the demonstration data, and annotators can even judge the quality of more superior generations than those they create, making it possible to explore a broader state space beyond what can be demonstrated by human annotators. Another key point is that RLHF essentially encourages LLMs to learn correct policies by contrasting the self-generated responses (discriminating between good and bad responses). It no longer forces the model to imitate external demonstration data, and thus can mitigate the hallucination issues with SFT as discussed above31.” (Zhao et al., 2023, p. 43) 首先,由于人类注释者主要为 RLHF 提供偏好注释,因此它可以在很大程度上缓解注释者与 SFT 中的差异。其次,偏好注释比编写演示数据要容易得多,注释者甚至可以判断比他们创建的更优秀的世代的质量,从而可以探索超出人类注释者可以演示的更广泛的状态空间。另一个关键点是,RLHF 实质上鼓励法学硕士通过对比自我生成的响应(区分好响应和坏响应)来学习正确的策略。它不再强制模型模仿外部演示数据,因此可以减轻上面讨论的 SFT 的幻觉问题31。
“In RLHF, it seems to be also important that reward models should be aware of the knowledge or ability of a LLM to be aligned.” (Zhao et al., 2023, p. 43) 在 RLHF 中,奖励模型应该意识到 LLM 的知识或能力要保持一致,这一点似乎也很重要。
“Adapter Tuning. Adapter tuning incorporates small neural network modules (called adapter) into the Transformer models [398]. To implement the adapter module, a bottleneck architecture has been proposed in [398, 399], which first compresses the original feature vector into a smaller dimension (followed by a nonlinear transformation) and then recovers it to the original dimension.” (Zhao et al., 2023, p. 44) 适配器调整。适配器调整将小型神经网络模块(称为适配器)合并到 Transformer 模型中 [398]。为了实现适配器模块,[398, 399]中提出了一种瓶颈架构,它首先将原始特征向量压缩到较小的维度(随后进行非线性变换),然后将其恢复到原始维度。
“Prefix Tuning. Prefix tuning [396] prepends a sequence of prefixes, which are a set of trainable continuous vectors, to each Transformer layer in language models. These prefix vectors are task-specific, which can be considered as virtual token embeddings.” (Zhao et al., 2023, p. 44) 前缀调整。前缀调整[396]将一系列前缀(一组可训练的连续向量)添加到语言模型中的每个 Transformer 层。这些前缀向量是特定于任务的,可以被视为虚拟令牌嵌入。
“Prompt Tuning. Different from prefix tuning, prompt tuning [397, 402] mainly focuses on incorporating trainable prompt vectors at the input layer32. Based on the discrete prompting methods [404, 405], it augments the input text by including a group of soft prompt tokens (either in a free form [402] or a prefix form [397]), and then takes the prompt-augmented input to solve specific downstream tasks.” (Zhao et al., 2023, p. 44) 及时调整。与前缀调整不同,提示调整[397, 402]主要侧重于在输入层合并可训练的提示向量32。基于离散提示方法[404, 405],它通过包含一组软提示标记(自由形式[402]或前缀形式[397])来增强输入文本,然后采用提示增强输入来解决特定的下游任务。
“Low-Rank Adaptation (LoRA). LoRA [145] imposes the low-rank constraint for approximating the update matrix at each dense layer, so as to reduce the trainable parameters for adapting to downstream tasks.” (Zhao et al., 2023, p. 44) 低阶适应(LoRA)。 LoRA[145]在每个密集层施加低秩约束来近似更新矩阵,以减少适应下游任务的可训练参数。
“Further, an empirical study [399] has been conducted to examine the effect of different tuning methods on language models. They compare four efficient tuning methods including serial adapter tuning [398], parallel adapter tuning [400, 410], and LoRA [145], on three open-source LLMs, namely GPT-J (6B), BLOOM (7.1B) and LLaMA (7B), for evaluation. Based on the experimental results on six math reasoning datasets, they show that these efficient-tuning methods under-perform the reference baseline GPT-3.5 on difficult tasks, while achieving a comparable performance on simple tasks. Overall, LoRA performs relatively well among these comparison methods, using significantly fewer trainable parameters.” (Zhao et al., 2023, p. 45) 此外,还进行了一项实证研究[399]来检验不同调优方法对语言模型的影响。他们在三个开源 LLM(即 GPT-J (6B)、BLOOM (7.1B) 和LLaMA (7B),用于评估。基于六个数学推理数据集的实验结果,他们表明这些高效调整方法在困难任务上的表现低于参考基线 GPT-3.5,而在简单任务上却达到了相当的性能。总体而言,LoRA 在这些比较方法中表现相对较好,使用的可训练参数明显较少。
“In neural network compression, quantization often refers to the mapping process from floating-point numbers to integers [412], especially the 8-bit integer quantization (i.e., INT8 quantization).” (Zhao et al., 2023, p. 45) 在神经网络压缩中,量化通常指从浮点数到整数的映射过程[412],特别是8位整数量化(即INT8量化)。
“There are generally two major model quantization approaches, namely quantization-aware training (QAT) (requiring additional full model retraining) and post-training quantization (PTQ) (requires no model retraining).” (Zhao et al., 2023, p. 45) 通常有两种主要的模型量化方法,即量化感知训练(QAT)(需要额外的完整模型重新训练)和训练后量化(PTQ)(不需要模型重新训练)。
“Mixed-precision decomposition. As observed in [413], extreme large values occur in hidden activations (called the emergence of outliers) when the model size reaches 6.7B parameters or above. Interestingly, these outliers are mainly distributed in some specific feature dimensions at Transformer layers. Based on this finding, a vector-wise quantization approach, called LLM.int8(), has been proposed in [413], which separates the feature dimensions with outliers and the rest dimensions in matrix multiplication. Then, the calculations for the two parts are performed with 16bit floating numbers and 8-bit integers, respectively, so as to recover these outliers in a high precision.” (Zhao et al., 2023, p. 45) 混合精度分解。正如[413]中观察到的,当模型大小达到 6.7B 参数或以上时,隐藏激活中会出现极大的值(称为异常值的出现)。有趣的是,这些异常值主要分布在 Transformer 层的一些特定特征维度上。基于这一发现,[413]中提出了一种称为 LLM.int8() 的向量量化方法,该方法将具有异常值的特征维度与矩阵乘法中的其余维度分开。然后,分别用16位浮点数和8位整数进行这两部分的计算,从而高精度地恢复这些异常值。
“Fine-grained quantization. For Transformer models, weights and activations are usually represented in the form of tensors. A straightforward approach is to use coarse-grained quantization parameters for the whole tensor (i.e., per-tensor quantization) [414].” (Zhao et al., 2023, p. 46) 细粒度量化。对于 Transformer 模型,权重和激活通常以张量的形式表示。一种直接的方法是对整个张量使用粗粒度量化参数(即每个张量量化)[414]。
“Efficient fine-tuning enhanced quantization. For posttraining quantization, direct low-bit quantization (e.g., INT4 quantization) often results in large performance degradation. To overcome this challenge, QLoRA [419] incorporates additional small tunable adapters (16-bit precision) into the quantized models, to achieve an efficient, high-precision model fine-tuning. It combines the merits of LoRA (See Section 5.3.1) and quantization methods.” (Zhao et al., 2023, p. 46) 高效微调增强量化。对于训练后量化,直接低位量化(例如 INT4 量化)通常会导致性能大幅下降。为了克服这一挑战,QLoRA[419]将额外的小型可调适配器(16位精度)合并到量化模型中,以实现高效、高精度的模型微调。它结合了 LoRA(参见第 5.3.1 节)和量化方法的优点。
“INT8 weight quantization can often yield very good results on LLMs, while the performance of lower precision weight quantization depends on specific methods [414, 416, 417, 421].” (Zhao et al., 2023, p. 46) INT8权重量化通常可以在LLM上产生非常好的结果,而较低精度权重量化的性能取决于特定方法[414,416,417,421]。
“Activations are more difficult to be quantized than weights [413, 414, 421]. It has been found that large outliers would occur for Transformer language models having” (Zhao et al., 2023, p. 46) 激活比权重更难量化[413,414,421]。研究发现,具有以下特征的 Transformer 语言模型会出现较大的异常值
“47 size of 6.7B or above [413].” (Zhao et al., 2023, p. 47) 47尺寸为6.7B或以上[413]。
“Quantized LLMs. Compared with original models, quantized language models take a smaller memory footprint, and likely have a faster inference speed [93, 413, 427].” (Zhao et al., 2023, p. 47) 与原始模型相比,量化语言模型占用的内存更小,并且可能具有更快的推理速度[93,413,427]。
“After pre-training or adaptation tuning, a major approach to using LLMs is to design suitable prompting strategies for solving various tasks.” (Zhao et al., 2023, p. 47) 经过预训练或适应性调整后,使用LLM的一个主要方法是设计合适的提示策略来解决各种任务。
“In existing literature, task-specific prompts can be effectively learned through manual creation and automatic optimization. A representative prompting method is in-context learning [50, 55], which formulates the task description and/or demonstrations in the form of natural language text. In addition, chain-of-thought prompting [33] can be employed to enhance in-context learning by involving a series of intermediate reasoning steps in prompts.” (Zhao et al., 2023, p. 47) 在现有文献中,可以通过手动创建和自动优化来有效学习特定任务的提示。一种代表性的提示方法是上下文学习[50, 55],它以自然语言文本的形式制定任务描述和/或演示。此外,思想链提示[33]可以通过在提示中涉及一系列中间推理步骤来增强情境学习。
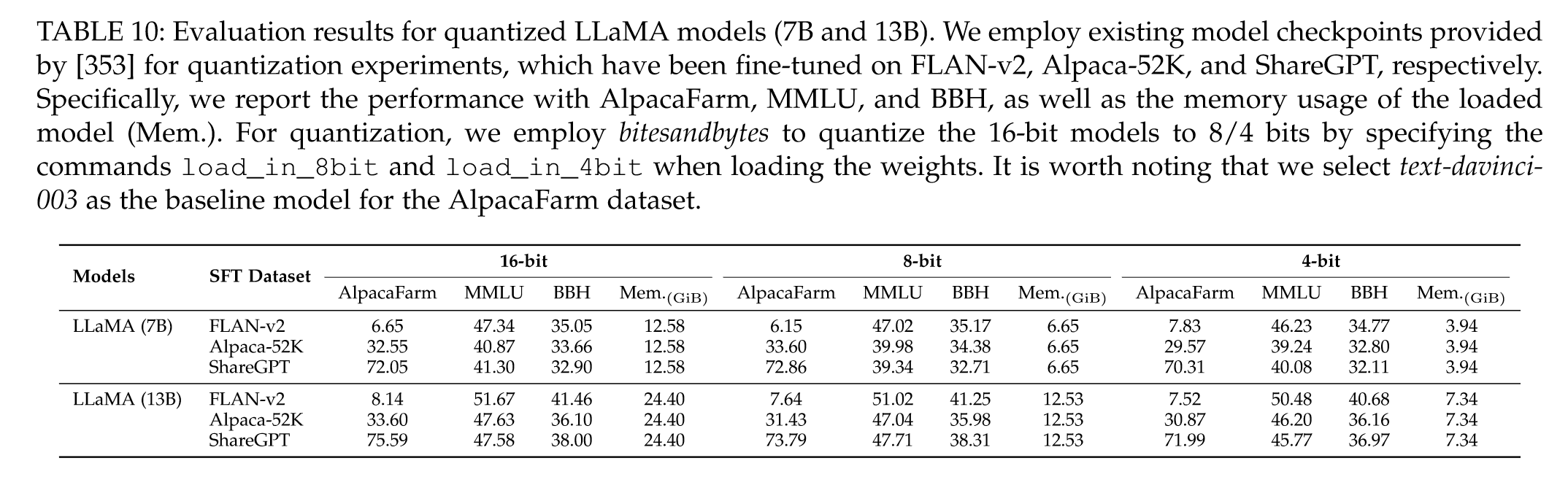
“The process of manually creating a suitable prompt is also called prompt engineering [452, 453]. A well-designed prompt is very helpful to elicit the abilities of LLMs for accomplishing specific tasks.” (Zhao et al., 2023, p. 48) 手动创建合适提示的过程也称为提示工程[452,453]。精心设计的提示对于激发 LLM 完成特定任务的能力非常有帮助。
“Key Ingredients. Typically, there are four key ingredients that depict the functionality of a prompt for eliciting the abilities of LLMs to complete the tasks, including task description, input data, contextual information, and prompt style.” (Zhao et al., 2023, p. 48) 关键成分。通常,有四个关键要素描述了提示的功能,以激发 LLM 完成任务的能力,包括任务描述、输入数据、上下文信息和提示样式。
“Task description. A task description is typically a specific instruction that LLMs are expected to follow. In general, one should clearly describe the task goal in natural language.” (Zhao et al., 2023, p. 48) 任务描述。任务描述通常是 LLM 应遵循的特定指令。一般来说,应该用自然语言清楚地描述任务目标。
“Input data. In common cases, it is straightforward to describe input data (e.g., an instance to be responded by LLMs) in natural language. For special input data, such as knowledge graph and table, it is necessary to apply an appropriate and convenient way to make them readable for LLMs.” (Zhao et al., 2023, p. 48) 输入数据。在一般情况下,用自然语言描述输入数据(例如,由 LLM 响应的实例)是直截了当的。对于特殊的输入数据,如知识图谱和表格,需要应用适当且方便的方式使其对LLM具有可读性。
“Prompt style. For different LLMs, it is important to design a suitable prompt style for eliciting their abilities to solve specific tasks. Overall, one should express the prompt as a clear question or detailed instruction that can be well understood and answered. In some cases, it is also useful to add the prefix or suffix to better guide LLMs.” (Zhao et al., 2023, p. 49) 提示样式。对于不同的LLM,设计一个合适的提示风格来激发他们解决特定任务的能力是很重要的。总的来说,应该将提示表达为可以很好地理解和回答的明确问题或详细说明。在某些情况下,添加前缀或后缀以更好地指导 LLM 也很有用。
“Expressing the task goal clearly. Task descriptions should not be ambiguous or unclear, which likely lead to in- accurate or inappropriate responses.” (Zhao et al., 2023, p. 49) 清楚地表达任务目标。任务描述不应模棱两可或不明确,这可能会导致不准确或不适当的响应。
“Decomposing into easy, detailed sub-tasks. To solve com- plex tasks, it is important to decompose the difficult task into several more easier, detailed sub-tasks for helping LLMs accomplish the goal step by step, which is closely re- lated to the planning technique in Section 6.4” (Zhao et al., 2023, p. 49) 分解为简单、详细的子任务。为了解决复合任务,重要的是将困难的任务分解为几个更简单、更详细的子任务,以帮助LLM逐步完成目标,这与第6.4节中的规划技术密切相关
“Providing few-shot demonstrations. As discussed in Section 6.2, LLMs can benefit from in-context learning for solving complex tasks, where the prompts contain a small number of task examples of the desired input-output pairs, i.e., few-shot demonstrations.” (Zhao et al., 2023, p. 49) 提供小镜头演示。如第 6.2 节所述,LLM 可以从上下文学习中受益,以解决复杂的任务,其中提示包含所需输入输出对的少量任务示例,即少量演示。
“As a general guideline, most existing LLMs perform a task better in English, thus it is useful to employ English instructions to solve difficult tasks based on machine translation.” (Zhao et al., 2023, p. 49) 作为一般准则,大多数现有的 LLM 在英语中执行任务效果更好,因此使用英语指令来解决基于机器翻译的困难任务是很有用的。
“Carefully designed prompts can boost the zero-shot or fewshot performance of ChatGPT. By comparing the results of using different prompts on the same task, we can see that using the carefully designed prompts can achieve better performance than the simpler ones.” (Zhao et al., 2023, p. 49) 精心设计的提示可以提高 ChatGPT 的零样本或少样本性能。通过比较在同一任务上使用不同提示的结果,我们可以看到,使用精心设计的提示可以比简单的提示获得更好的性能。
“More complex tasks can benefit more from careful prompt engineering on ChatGPT. In the WikiFact and Colored Objects tasks, the designed prompts have greatly improved the performance of ChatGPT, i.e., from 23.61 to 28.47 on WikiFact and from 53.20 to 66.75 on Colored Objects.” (Zhao et al., 2023, p. 49) 更复杂的任务可以从 ChatGPT 上仔细的提示工程中受益更多。在WikiFact和Colored Objects任务中,设计的提示大大提高了ChatGPT的性能,即在WikiFact上从23.61提高到28.47,在Colored Objects上从53.20提高到66.75。
“However, the performance of ChatGPT is still far from the referenced performance in these tasks, as LLMs cannot directly fit these tasks, which require specific domain knowledge and task adaptation [357, 462].” (Zhao et al., 2023, p. 51) 然而,ChatGPT在这些任务中的性能仍然远远低于参考性能,因为LLM无法直接适应这些任务,这需要特定的领域知识和任务适应[357,462]。
“Discrete Prompt Optimization. Discrete prompt is typically composed of a sequence of natural language tokens. Despite that the form is simple and flexible, optimizing prompts in discrete space is a challenging problem due to the combinatorial huge search space.” (Zhao et al., 2023, p. 51) 离散提示优化。离散提示通常由一系列自然语言标记组成。尽管表单简单灵活,但由于组合巨大的搜索空间,在离散空间中优化提示是一个具有挑战性的问题。
“Gradient-based approaches. This kind of approaches aims to optimize the prompt search process by maximizing the output likelihood via gradient update [405, 464–466].” (Zhao et al., 2023, p. 51) 基于梯度的方法。这种方法旨在通过梯度更新最大化输出似然来优化提示搜索过程[405,464–466]。
“RL-based approaches. Since discrete prompts are difficult to be learned through gradient back-propagation, a number of studies propose to formulate the discrete prompt optimization as a reinforcement learning (RL) problem and leverage RL algorithms for optimization [467, 468].” (Zhao et al., 2023, p. 51) 基于 RL 的方法。由于离散提示很难通过梯度反向传播来学习,许多研究建议将离散提示优化表述为强化学习(RL)问题,并利用RL算法进行优化[467,468]。
“Edit-based approaches. For the above methods, gradientbased and RL-based tuning can be extremely computationally demanding for ever larger models, and may not be feasible for API-based model calls (e.g., ChatGPT).” (Zhao et al., 2023, p. 51) 基于编辑的方法。对于上述方法,基于梯度和基于 RL 的调优对于更大的模型来说可能对计算要求极高,并且对于基于 API 的模型调用(例如 ChatGPT)可能不可行。
“LLM-based approaches. Due to the exceptional capacities of LLMs, an increasing number of studies directly leverage LLMs as prompt generator [471–473].” (Zhao et al., 2023, p. 51) 基于LLM的方法。由于LLM具有特殊的能力,越来越多的研究直接利用LLM作为提示生成器[471\u2012473]。
“Continuous Prompt Optimization. Different from discrete prompts, continuous prompts consist of a set of continuous embeddings, which can be directly optimized through the gradient update based on the loss of downstream tasks. Note that continuous prompt optimization has been mainly studied in PLMs, but draws limited attention in era of LLMs due to their massive magnitudes of parameters.” (Zhao et al., 2023, p. 51) 持续的提示优化。与离散提示不同,连续提示由一组连续嵌入组成,可以基于下游任务的损失,通过梯度更新直接进行优化。需要注意的是,连续提示优化主要在PLM中研究,但由于其参数量大,在LLM时代受到的关注有限。
“As a special prompting form, in-context learning (ICL) is first proposed along with GPT-3 [55], which has become a typical approach to utilizing LLMs.” (Zhao et al., 2023, p. 53) 作为一种特殊的提示形式,语境学习(ICL)首先与GPT-3一起被提出[55],GPT-3已成为利用LLM的典型方法。
“First, starting with a task description, a few examples are selected from the task dataset as demonstrations. Then, they are combined in a specific order to form natural language prompts with specially designed templates. Finally, the test instance is appended to the demonstration as the input for LLMs to generate the output. Based on task demonstrations, LLMs can recognize and perform a new task without explicit gradient update.” (Zhao et al., 2023, p. 53) 首先,从任务描述开始,从任务数据集中选择几个示例作为演示。然后,它们以特定顺序组合在一起,以使用专门设计的模板形成自然语言提示。最后,将测试实例附加到演示中,作为 LLM 生成输出的输入。基于任务演示,LLM 可以在没有显式梯度更新的情况下识别和执行新任务。
“Also, ICL has a close connection with instruction tuning (discussed in Section 5.1) in that both utilize natural language to format the task or instances. However, instruction tuning needs to fine-tune LLMs for adaptation, while ICL only prompts LLMs for utilization.” (Zhao et al., 2023, p. 53) 此外,ICL 与指令调优(在第 5.1 节中讨论)有着密切的联系,因为两者都利用自然语言来格式化任务或实例。然而,指令调优需要对 LLM 进行微调以进行适应,而 ICL 仅提示 LLM 进行使用。
“Demonstration Selection. The performance of ICL tends to have a large variance with different demonstration examples [428], so it is important to select a subset of examples that can effectively leverage the ICL capability of LLMs.” (Zhao et al., 2023, p. 53) 演示选择。ICL的性能往往与不同的演示样本有较大的差异[428],因此选择能够有效利用LLM的ICL能力的样本子集非常重要。
“Demonstration Format. After selecting task examples, the next step is to integrate and format them into a natural language prompt for LLMs.” (Zhao et al., 2023, p. 53) 演示格式。选择任务示例后,下一步是将它们集成并格式化为 LLM 的自然语言提示。
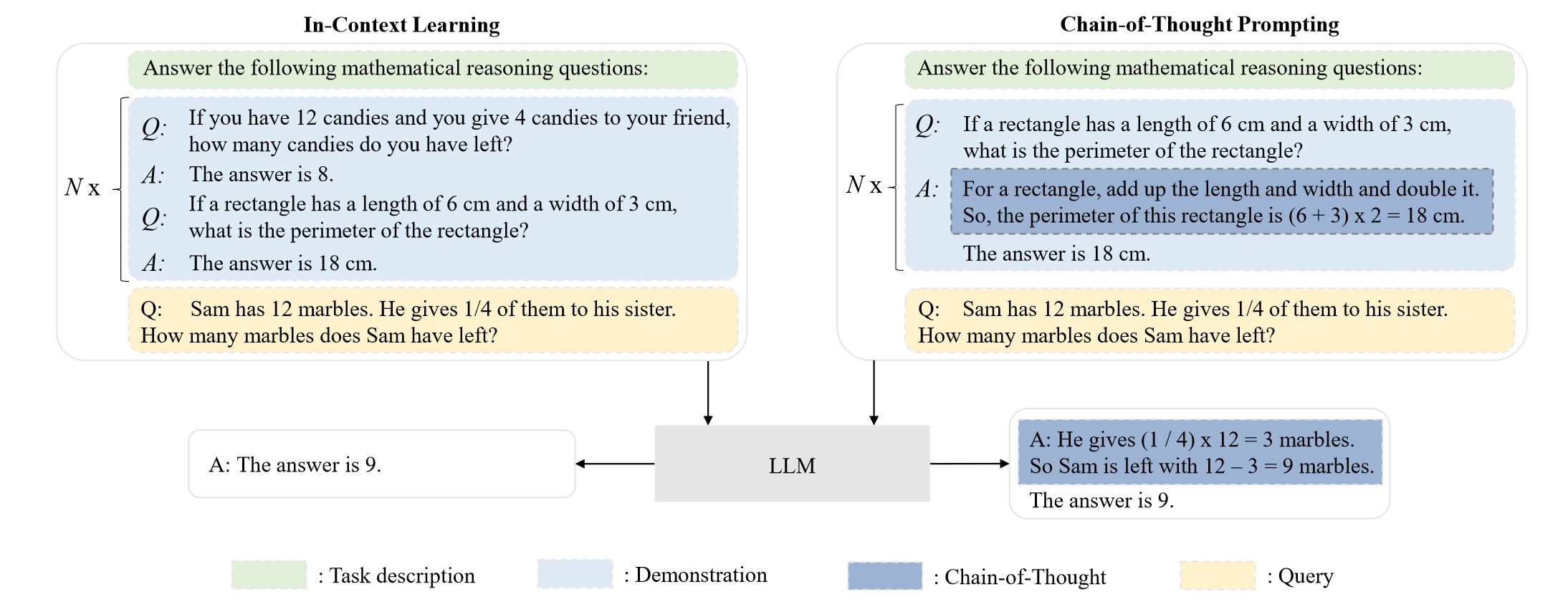
“Demonstration Order. LLMs are shown to sometimes suffer from the recency bias, i.e., they are prone to repeat answers that are near the end of demonstrations [479]. Thus, it is important to arrange demonstrations (i.e., task examples) in a reasonable order.” (Zhao et al., 2023, p. 54) 演示顺序。LLM有时被证明存在新近偏差,即他们容易在演示结束时重复答案[479]。因此,以合理的顺序安排演示(即任务示例)非常重要。
“For example, ICL can be theoretically explained as the product of pre-training on documents that exhibit long-range coherence [488].” (Zhao et al., 2023, p. 54) 例如,ICL在理论上可以解释为对表现出长程相干性的文档进行预训练的产物[488]。
“Task recognition. In the first way, LLMs recognize the task from demonstrations and utilize the prior knowledge obtained from pre-training to solve new test tasks.” (Zhao et al., 2023, p. 54) 任务识别。在第一种方式中,LLM 从演示中识别任务,并利用从预训练中获得的先验知识来解决新的测试任务。
“Task learning. In the second way, LLMs learn new tasks unseen in the pre-training stage only through demonstrations. Specially, task learning is analyzed mainly from the perspective of gradient descent and considered as implicit fine-tuning [65, 496].” (Zhao et al., 2023, p. 55) 任务学习。在第二种方式中,LLM 只能通过演示来学习在预训练阶段看不见的新任务。特别是,任务学习主要从梯度下降的角度进行分析,并被认为是隐式微调[65,496]。
“Chain-of-Thought (CoT) prompting [33, 502] is an improved prompting strategy to boost the performance of LLMs on complex reasoning tasks, such as arithmetic reasoning [503], commonsense reasoning [504], and symbolic reasoning [33]. Instead of simply constructing the prompts with inputoutput pairs like ICL, CoT prompting further incorporates intermediate reasoning steps, which serve as the bridge between inputs and outputs.” (Zhao et al., 2023, p. 55) 思维链(CoT)提示[33,502]是一种改进的提示策略,用于提高LLM在复杂推理任务上的表现,如算术推理[503]、常识推理[504]和符号推理[33]。CoT 提示不是像 ICL 那样简单地使用输入输出对构建提示,而是进一步结合中间推理步骤,这些步骤充当输入和输出之间的桥梁。
“CoT prompting is first proposed as an extension of ICL [33], which augments each demonstration ⟨input, output⟩ as ⟨input, CoT, output⟩. A CoT is a series of intermediate reasoning steps for connecting the input and output. With these augmented demonstrations, LLMs can follow them to generate CoTs and the answer for a new input.” (Zhao et al., 2023, p. 55) CoT提示首先被提出作为ICL的扩展[33],它增强了每个演示⟨输入、输出⟩作为⟨输入、CoT、输出⟩。CoT 是用于连接输入和输出的一系列中间推理步骤。通过这些增强的演示,LLM 可以遵循它们来生成 CoT 和新输入的答案。
“Better Prompt Design. Since CoT prompting relies on prompts to elicit the reasoning capabilities of LLMs, the design of prompts is critical to its performance. As a direct approach, it is shown that using diverse CoTs (i.e., multiple reasoning paths for each problem) can effectively enhance the performance [437].” (Zhao et al., 2023, p. 55) 更好的提示设计。由于 CoT 提示依赖于提示来引出 LLM 的推理能力,因此提示的设计对其性能至关重要。作为一种直接方法,研究表明,使用不同的CoT(即,每个问题的多个推理路径)可以有效地提高性能[437]。
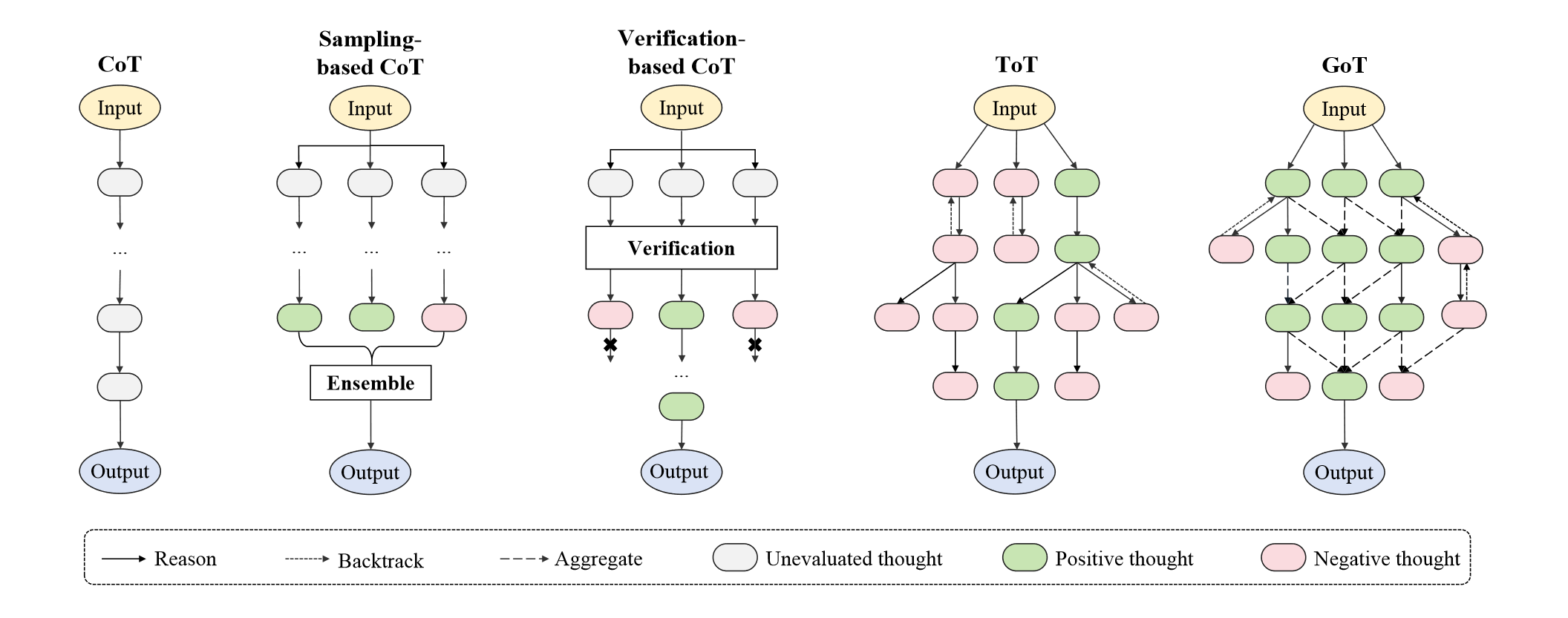
“As a representative solution, self-consistency [436] first generates several reasoning paths and then takes an ensemble over the corresponding answers, selecting the most consistent one through majority voting.” (Zhao et al., 2023, p. 56) 作为一个具有代表性的解决方案,自洽[436]首先生成几个推理路径,然后对相应的答案进行整合,通过多数投票选择最一致的答案。
“When CoT Prompting Works For LLMs? Since CoT reasoning is an emergent ability [31], it only has a positive effect on sufficiently large models (typically containing 10B or more parameters [33]) but not on small models.” (Zhao et al., 2023, p. 56) CoT 提示何时适用于 LLM?由于CoT推理是一种涌现能力[31],它只对足够大的模型(通常包含10B或更多参数[33])有积极影响,而对小模型没有积极影响。
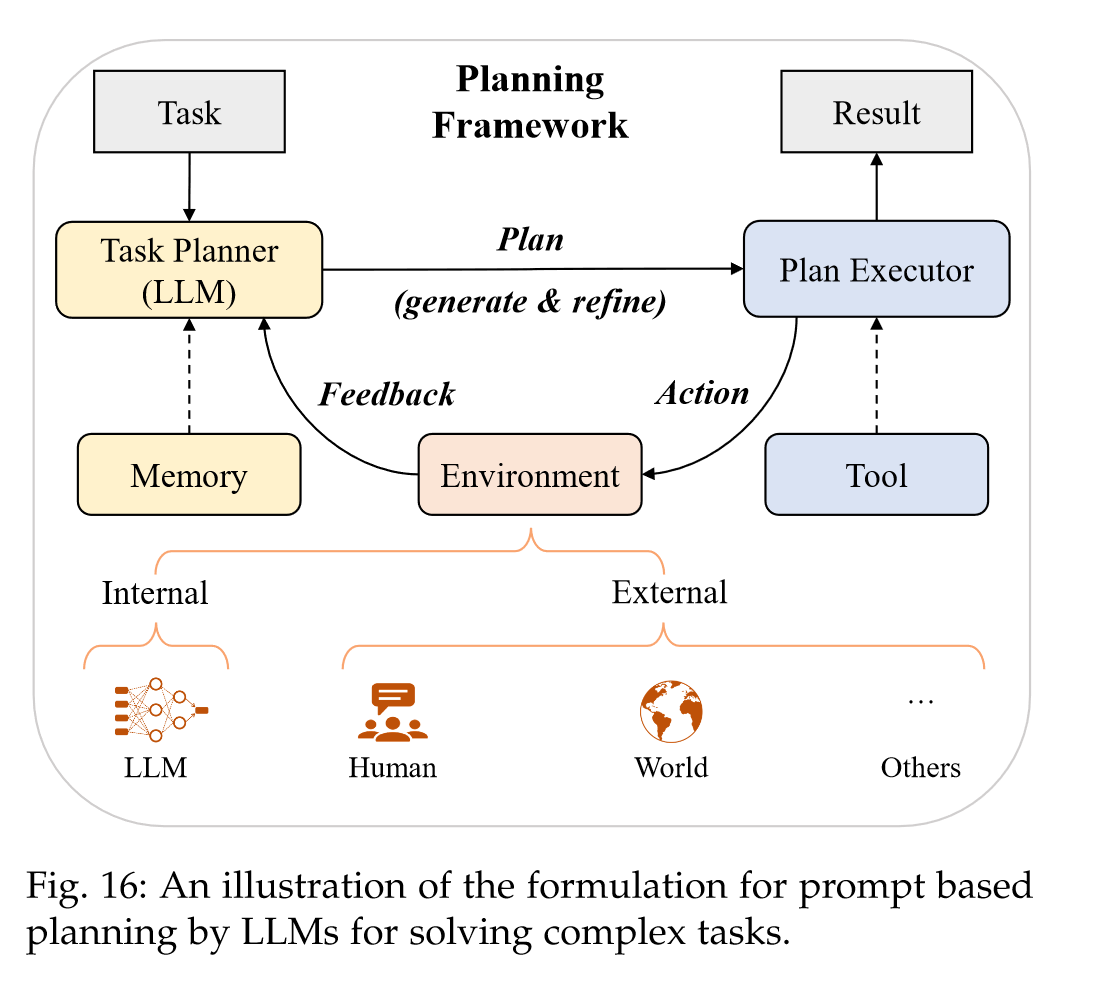
“since CoT prompting augments the standard prompting with intermediate reasoning steps, it is mainly effective for the tasks that require step-by-step reasoning [33], e.g., arithmetic reasoning, commonsense reasoning, and symbolic reasoning. Whereas, for other tasks that do not rely on complex reasoning, CoT prompting might lead to worse performance than standard prompting” (Zhao et al., 2023, p. 57) 由于CoT提示通过中间推理步骤增强了标准提示,因此它主要对需要分步推理的任务有效[33],例如算术推理、常识推理和符号推理。然而,对于不依赖于复杂推理的其他任务,CoT 提示可能会导致性能比标准提示差
“The source of CoT reasoning ability. Regarding the source of CoT reasoning capability, it is widely hypothesized that it can be attributed to training on code since models trained on it show a strong reasoning ability [47, 520, 521].” (Zhao et al., 2023, p. 57) CoT 推理能力的来源。关于CoT推理能力的来源,人们普遍认为它可以归因于代码训练,因为在其上训练的模型显示出很强的推理能力[47,520,521]。
“The effect of CoT prompting components. The major distinction between CoT prompting and standard prompting is the incorporation of reasoning paths prior to the final answer.” (Zhao et al., 2023, p. 57) CoT 提示组件的效果。CoT 提示和标准提示之间的主要区别在于在最终答案之前合并推理路径。
“Thus, some researchers investigate the effects of different components in the reasoning paths. Specifically, a recent study identifies three key components in CoT prompting, namely symbols (e.g., numerical quantities in arithmetic reasoning), patterns (e.g., equations in arithmetic reasoning), and text (i.e., the rest of tokens that are not symbols or patterns) [522].” (Zhao et al., 2023, p. 57) 因此,一些研究人员研究了推理路径中不同组件的影响。具体而言,最近的一项研究确定了CoT提示的三个关键组成部分,即符号(例如,算术推理中的数值量)、模式(例如,算术推理中的方程)和文本(即,其余不是符号或模式的标记)[522]。
“In this part, we mainly focus on three basic types of ability evaluation for LLMs, i.e., language generation, knowledge utilization, and complex reasoning” (Zhao et al., 2023, p. 59) 在这一部分中,我们主要关注LLM的三种基本能力评估类型,即语言生成、知识利用和复杂推理
“As an important topic in language generation, conditional text generation [48] focuses on generating texts satisfying specific task demands based on the given conditions, typically including machine translation [624], text summarization [548], and question answering [557].” (Zhao et al., 2023, p. 59) 条件文本生成[48]作为语言生成中的一个重要课题,侧重于根据给定条件生成满足特定任务需求的文本,通常包括机器翻译[624]、文本摘要[548]和问答[557]。
“To measure the quality of the generated text, automatic metrics (e.g., Accuracy, BLEU [625] and ROUGE [626]) and human ratings have been typically used for evaluating the performance.” (Zhao et al., 2023, p. 59) 为了衡量生成文本的质量,通常使用自动指标(例如,准确性,BLEU [625]和ROUGE [626])和人工评分来评估性能。
“Code Synthesis. In addition to generating high-quality natural language text, existing LLMs also show strong abilities to generate formal language, especially computer programs (i.e., code) that satisfy specific conditions, called code synthesis [635].” (Zhao et al., 2023, p. 59) 代码合成。除了生成高质量的自然语言文本外,现有的LLM还表现出强大的生成形式语言的能力,特别是满足特定条件的计算机程序(即代码),称为代码合成[635]。
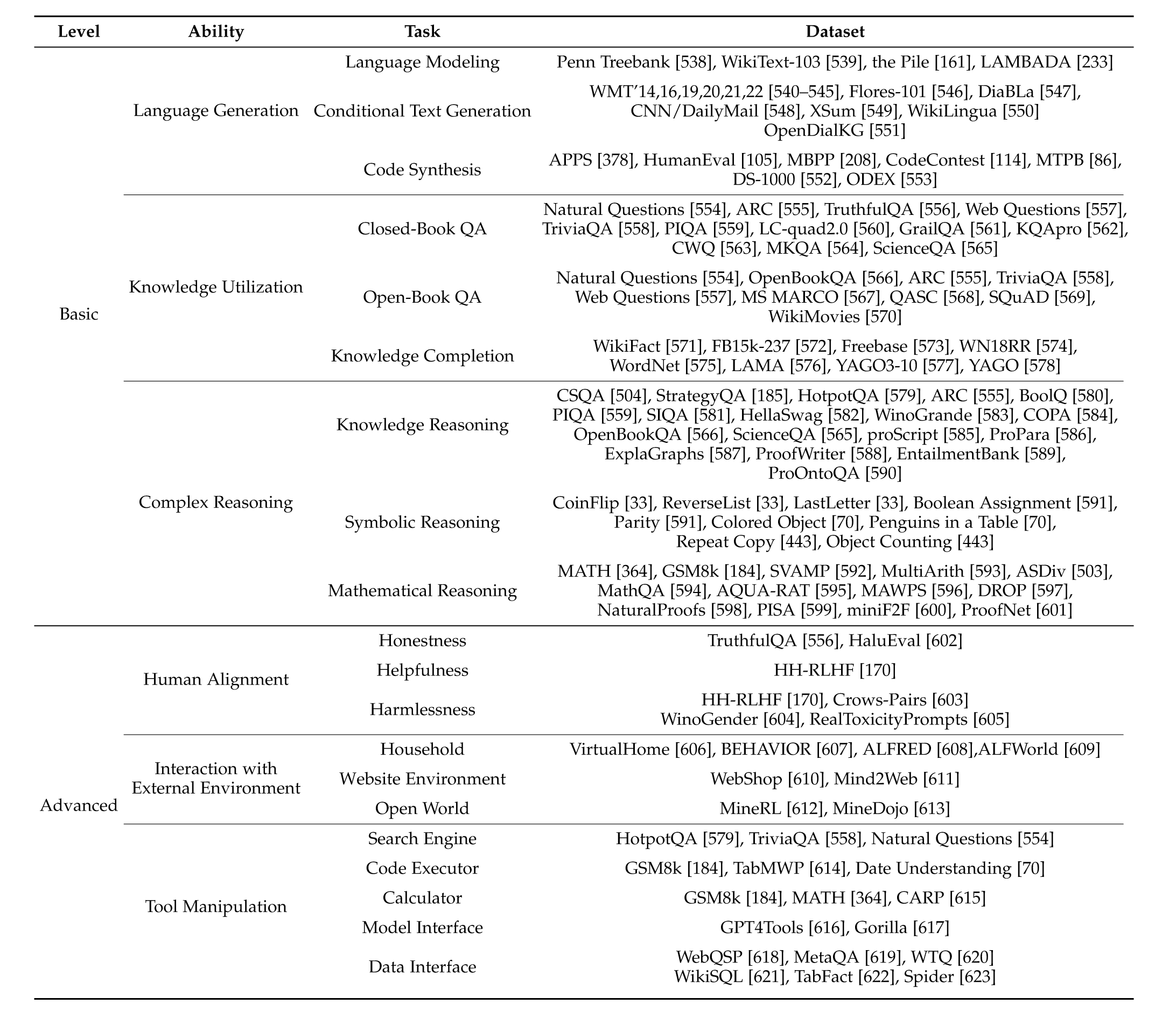
“LLMs have been capable of generating texts with a comparable quality to human-written texts, which however might be underestimated by automatic reference-based metrics. As an alternative evaluation approach, LLMs can serve as language generation evaluators to evaluate a single text, compare multiple candidates, and improve existing metrics. However, this evaluation approach still needs more inspections and examinations in real-world tasks.” (Zhao et al., 2023, p. 61) LLM 已经能够生成与人类编写文本质量相当的文本,然而,基于自动参考的指标可能会低估这些文本。作为一种替代评估方法,LLM 可以用作语言生成评估器,以评估单个文本、比较多个候选文本并改进现有指标。然而,这种评估方法仍然需要更多的检查和检查。
“Intuitively, domain knowledge should be critical for model specialization. However, it is not easy to inject such specialized knowledge into LLMs.” (Zhao et al., 2023, p. 61) 直观地说,领域知识对于模型专业化至关重要。然而,将这些专业知识注入LLM并不容易。
“As discussed in recent analyses [47, 648], when LLMs are trained to exhibit some specific ability that allows them to excel in some areas, they might struggle in others. Such an issue is related to catastrophic forgetting [649, 650] in training neural networks, which refers to the conflict phenomenon of integrating new and old knowledge. Similar cases also occur in human align- ment of LLMs, where “alignment tax” [66] (e.g., a potential loss in the in-context learning ability) has to be paid for aligning to human values and needs.” (Zhao et al., 2023, p. 61) 正如最近的分析[47,648]所讨论的,当LLM被训练表现出一些特定的能力,使他们能够在某些领域表现出色时,他们可能会在其他领域挣扎。这个问题与训练神经网络中的灾难性遗忘[649,650]有关,它指的是融合新旧知识的冲突现象。类似的情况也发生在LLM的人类对齐中,其中“对齐税”[66](例如,情境学习能力的潜在损失)必须为与人类价值观和需求保持一致而付出代价。
“LLMs may fall short in mastering generation tasks that require domain-specific knowledge or generating structured data. It is non-trivial to inject specialized knowledge into LLMs, meanwhile maintaining the original abilities of LLMs.” (Zhao et al., 2023, p. 61) LLM 可能无法掌握需要特定领域知识或生成结构化数据的生成任务。将专业知识注入LLMs,同时保持LLMs原有的能力,是一件不小事。
“LLMs are prone to generate untruthful information that either conflicts with the existing source or cannot be verified by the available source. Even the most powerful LLMs such as ChatGPT face great challenges in migrating the hallucinations of the generated texts. This issue can be partially alleviated by special approaches such as alignment tuning and tool utilization.” (Zhao et al., 2023, p. 62) LLM 容易生成不真实的信息,这些信息要么与现有来源冲突,要么无法通过可用来源进行验证。即使是最强大的 LLM,如 ChatGPT,在迁移生成文本的幻觉方面也面临着巨大的挑战。这个问题可以通过特殊方法(例如对齐调整和工具利用率)部分缓解。
“Knowledge recency. As another major challenge, LLMs would encounter difficulties when solving tasks that require 63 the latest knowledge beyond the training data.” (Zhao et al., 2023, p. 62) 知识新近度。作为另一个主要挑战,LLM 在解决需要 63 个训练数据之外的最新知识的任务时会遇到困难。
“The parametric knowledge of LLMs is hard to be updated in a timely manner. Augmenting LLMs with external knowledge sources is a practical approach to tackling the issue. However, how to effectively update knowledge within LLMs remains an open research problem.” (Zhao et al., 2023, p. 63) LLM的参数化知识很难及时更新。用外部知识资源增强LLM是解决这个问题的实用方法。然而,如何有效地更新LLM中的知识仍然是一个悬而未决的研究问题。
“LLMs may generate the correct answer following an invalid reasoning path, or produce a wrong answer after a correct reasoning process, leading to inconsistency between the derived answer and the reasoning process. The issue can be alleviated by fine-tuning LLMs with process-level feedback, using an ensemble of diverse reasoning paths, and refining the reasoning process with selfreflection or external feedback.” (Zhao et al., 2023, p. 64) LLM 可能会按照无效的推理路径生成正确答案,或者在正确的推理过程后产生错误的答案,从而导致推导的答案与推理过程不一致。这个问题可以通过使用过程级反馈来微调 LLM,使用不同的推理路径集合,并通过自我反思或外部反馈来完善推理过程来缓解。
“LLMs face difficulties in numerical computation, especially for the symbols that are seldom encountered during pre-training. In addition to using mathematical tools, tokenizing digits into individual tokens is also an effective design choice for improving the arithmetic ability of LLMs.” (Zhao et al., 2023, p. 64) LLM在数值计算方面面临困难,特别是对于在预训练中很少遇到的符号。除了使用数学工具外,将数字标记化为单个标记也是提高LLM算术能力的有效设计选择。
“It is desired that LLMs could well conform to human values and needs, i.e., human alignment, which is a key ability for the broad use of LLMs in real-world applications.” (Zhao et al., 2023, p. 65) 希望LLM能够很好地符合人类的价值观和需求,即人类的一致性,这是LLM在现实世界中广泛使用的关键能力。
“Despite the automatic evaluation with the above datasets, human evaluation is still a more direct way to effectively test the human alignment ability of LLMs.” (Zhao et al., 2023, p. 65) 尽管使用上述数据集进行自动评估,但人工评估仍然是有效测试LLM的人类对齐能力的更直接的方法。
“When solving complex problems, LLMs can turn to external tools if they determine it is necessary. By encapsulating available tools with API calls, existing work has involved a variety of external tools, e.g., search engine [81], calcula- tor [80], and compiler [443], to enhance the performance of LLMs on several specific tasks.” (Zhao et al., 2023, p. 65) 在解决复杂问题时,如果LLM认为有必要,他们可以求助于外部工具。通过将可用工具与API调用封装在一起,现有的工作涉及各种外部工具,例如搜索引擎[81]、微积分器[80]和编译器[443],以提高LLM在几个特定任务上的性能。
“• MMLU [364] is a versatile benchmark for large-scale evaluation of multi-task knowledge understanding, covering a wide range of knowledge domains from mathematics and computer science to humanities and social sciences. The difficulties of these tasks vary from basic to advanced. As shown in existing work, LLMs mostly outperform small models by a substantial margin on this benchmark [35, 56, 57, 69], which shows the scaling law in model size. More recently, GPT-4 achieves a remarkable record (86.4% in 5shot setting) in MMLU, which is significantly better than the previous state-of-the-art models [46].” (Zhao et al., 2023, p. 66) • MMLU [364] 是一个用于大规模评估多任务知识理解的多功能基准,涵盖了从数学和计算机科学到人文和社会科学的广泛知识领域。这些任务的难度从基础到高级不等。正如现有工作所示,LLM在该基准上的表现大多优于小型模型[35,56,57,69],这显示了模型大小的缩放规律。最近,GPT-4在MMLU中取得了令人瞩目的记录(5次设置为86.4%),这明显优于以前的最先进模型[46]。
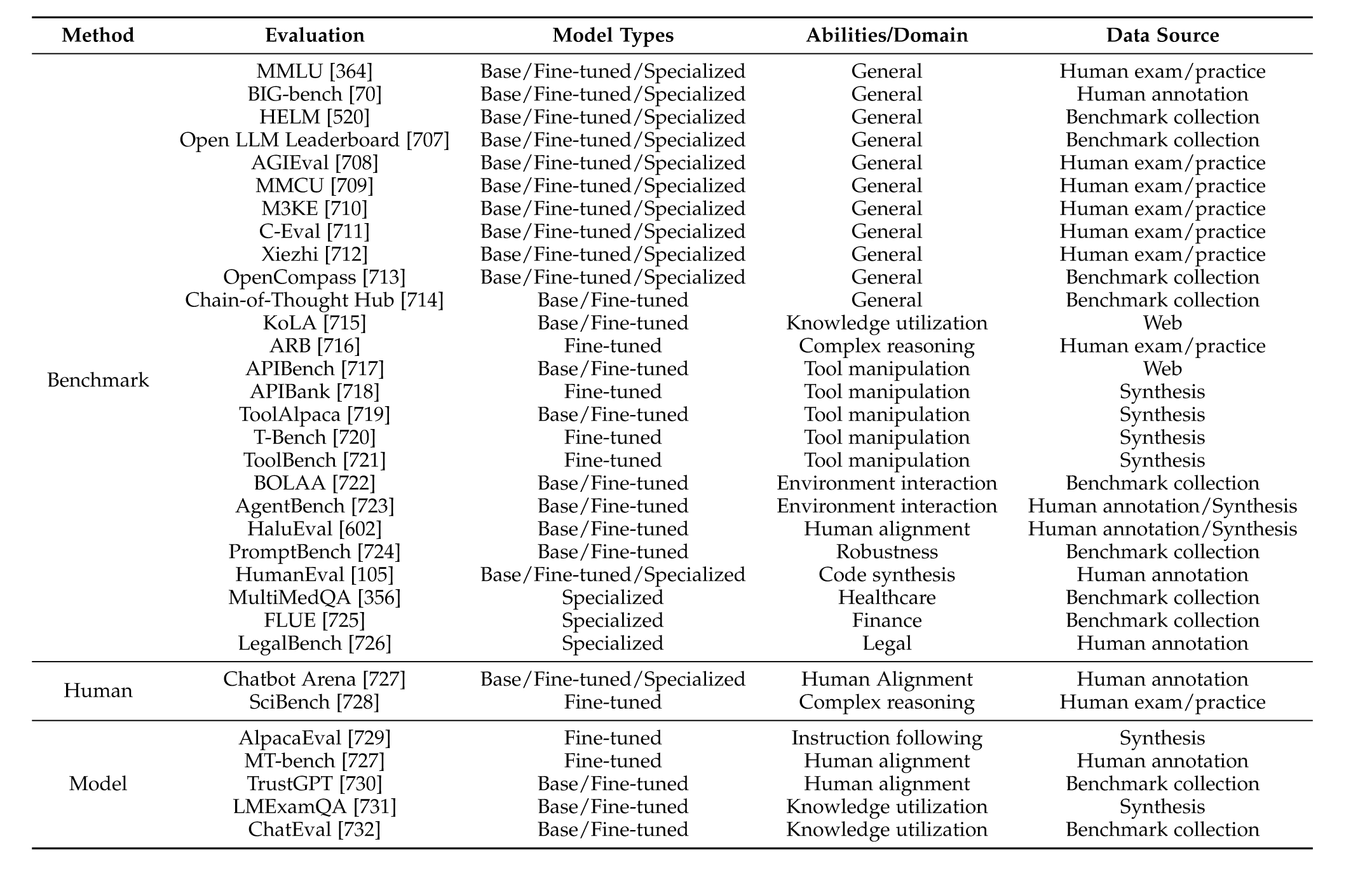
“Benchmark based evaluation procedure. To perform the benchmark evaluation, each problem will first be formatted into a prompt for LLMs to generate the result text. Then, the generated result text will be parsed with human-written rules to get the predicted answer. Finally, the performance of LLMs can be automatically calculated using standard metrics like accuracy by comparing the predicted answer with the ground-truth one.” (Zhao et al., 2023, p. 67) 基于基准的评估程序。为了执行基准评估,每个问题将首先被格式化为提示,以便 LLM 生成结果文本。然后,生成的结果文本将使用人工编写的规则进行解析,以获得预测的答案。最后,通过将预测答案与真实答案进行比较,可以使用准确性等标准指标自动计算 LLM 的性能。
“Human-based evaluation. Unlike automatic evaluation for basic abilities, human evaluation typically considers more factors or abilities in real-world use, such as human alignment and tool manipulation. In this evaluation approach, test tasks are usually in the form of openended questions, and human evaluators are invited to make judgments on the quality of answers generated by LLMs.” (Zhao et al., 2023, p. 68) 以人为本的评估。与对基本能力的自动评估不同,人工评估通常会考虑实际使用中的更多因素或能力,例如人类对齐和工具操作。在这种评估方法中,测试任务通常采用开放式问题的形式,并邀请人类评估者对LLM生成的答案的质量进行判断。
“Typically, there are two main types of scoring methods for human evaluators: pairwise comparison and singleanswer grading. In pairwise comparison, given the same question, humans are assigned two answers from different models to determine which one is better, while in singleanswer grading, they only need to score a single answer at a time.” (Zhao et al., 2023, p. 68) 通常,人工评估者的评分方法主要有两种类型:成对比较和单答案评分。在成对比较中,给定相同的问题,人类被分配来自不同模型的两个答案以确定哪个更好,而在单答案评分中,他们一次只需要对一个答案进行评分。
“However, LLMs are often sensitive to the evaluation settings, including the question prompts, zero-shot or few-shot tests, and the answer parsing methods. Thus, one should take possible influencing factors into consideration when conducting the evaluation experiments.” (Zhao et al., 2023, p. 68) 然而,LLM 通常对评估设置很敏感,包括问题提示、零样本或少样本测试以及答案解析方法。因此,在进行评价实验时,应考虑可能的影响因素。
“Another issue is the data contamination [56, 738], i.e., the test data itself or relevant content has been contained in the pre-training corpora. This phenomenon has become increasingly severe since more and more open data has been collected for developing LLMs.” (Zhao et al., 2023, p. 68) 另一个问题是数据污染[56,738],即测试数据本身或相关内容已包含在预训练语料库中。随着越来越多的开放数据被收集用于开发LLM,这种现象变得越来越严重。
“Human-based approach. Human evaluation offers several advantages when assessing the capabilities of LLMs to solve real-world tasks. One of the key benefits is its ability to directly reflect the actual abilities of LLMs. Based on feedback and experiences from real users, human evaluation provides a more direct measure of LLMs’ performance in real-world scenarios. Further, it can conduct more flexible and diverse evaluation tasks based on human evaluators.” (Zhao et al., 2023, p. 68) 以人为本的方法。在评估 LLM 解决现实世界任务的能力时,人工评估具有多种优势。主要好处之一是它能够直接反映LLM的实际能力。 基于真实用户的反馈和经验,人工评估提供了更直接的LLM在真实场景中的表现衡量标准。此外,它可以基于人类评估者进行更灵活、更多样化的评估任务。
“However, human evaluation also has inherent limitations that could potentially affect its accuracy and consistency. Factors such as personalized tastes and varying education levels among evaluators can introduce biases or even inconsistencies in the evaluation process.” (Zhao et al., 2023, p. 68) 然而,人工评估也有固有的局限性,可能会影响其准确性和一致性。评估人员的个性化品味和教育水平不同等因素可能会在评估过程中引入偏见甚至不一致。
“Recent studies [55, 752] have also tested the performance of LLMs on these tasks, showing that LLMs can also perform well via in-context learning (with very few examples). Whereas, as small models can be specially optimized on these tasks to learn the specific task requirement and domain knowledge, full-data fine-tuned small models can mostly outperform LLMs using in-context learning on several classic tasks [753, 754], e.g., semantic matching and sentiment analysis.” (Zhao et al., 2023, p. 73) 最近的研究[55,752]也测试了LLM在这些任务上的表现,表明LLM也可以通过上下文学习表现良好(例子很少)。然而,由于小模型可以针对这些任务进行专门优化,以学习特定的任务需求和领域知识,因此在几个经典任务上使用上下文学习,全数据微调的小模型大多可以优于LLM[753,754],例如语义匹配和情感分析。
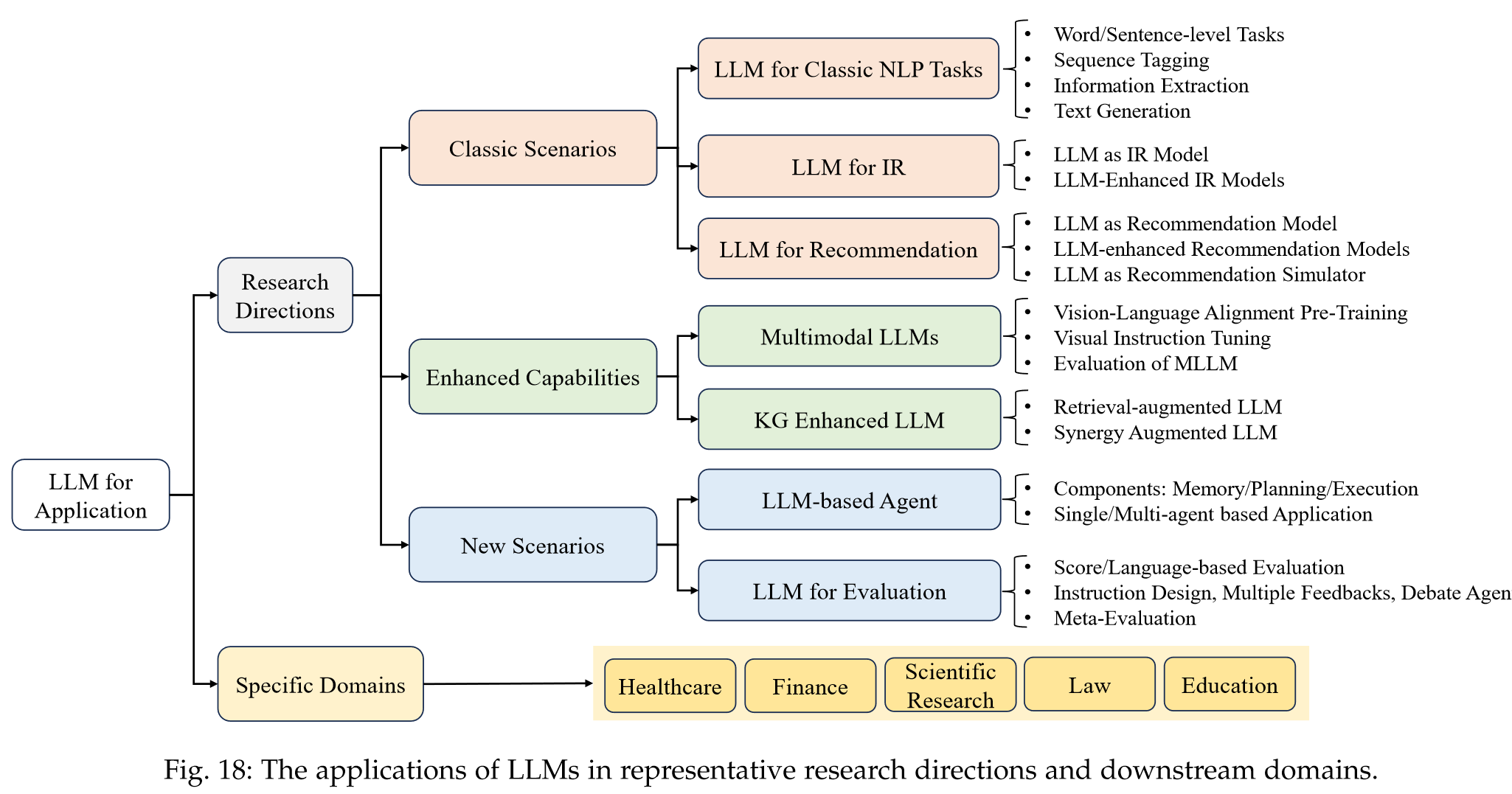
“Suggestions: LLMs and small models have their own merits in different aspects: LLMs are can provide unified solutions to various NLP tasks and achieve competitive performance (especially in the zero/few-shot setting), while small models are economical to develop and can be specially tuned according to target tasks, which can achieve good performance with sufficient high-quality labeled data [753, 754, 770, 771]. In applications, one can make suitable choices based on the actual needs, comprehensively considering flexibility, data availability, training compute, and efficiency” (Zhao et al., 2023, p. 74) 建议:LLM和小模型在不同方面各有千秋:LLM可以为各种NLP任务提供统一的解决方案,并实现有竞争力的性能(特别是在零/少样本设置下),而小模型开发经济,可以根据目标任务进行专门调整,在有足够高质量的标记数据的情况下可以达到良好的性能[753, 754, 770, 771].在应用中,可以根据实际需求做出合适的选择,综合考虑灵活性、数据可用性、训练计算和效率
“It is also promising to combine LLMs and fine-tuned small language models for complementing with each other in solving complex cases of classic NLP tasks [772].” (Zhao et al., 2023, p. 74) 在解决经典NLP任务的复杂情况时,将LLM和微调的小语言模型结合起来,相互补充也是很有希望的[772]。
“Existing IR models can be overall categorized into sparse models (relying on term-based lexical similarity) and dense models (relying on embedding based semantic similarity) [740].” (Zhao et al., 2023, p. 74) 现有的IR模型总体上可分为稀疏模型(依赖于基于术语的词汇相似性)和密集模型(依赖于基于嵌入的语义相似性)[740]。
“Typically, existing studies train a recommendation model (either classic or deep learning model) by fitting it over the user’s logged data (e.g., click data) [745, 802]. However, these models often suffer from a series of technical issues, e.g., cold-start recommendation, domain transfer, and poor explainability.” (Zhao et al., 2023, p. 75) 通常,现有研究通过对用户记录的数据(例如点击数据)进行拟合来训练推荐模型(经典或深度学习模型)[745,802]。然而,这些模型经常存在一系列技术问题,例如冷启动推荐、域名转移和可解释性差。
“Vision-language alignment pre-training. To develop MLLMs, existing work mostly initializes the vision encoder and the LLM with pre-trained models [149, 150, 826]. These models retain excellent vision and language capacities, but span different semantic spaces. Thus, the goal of visionlanguage alignment pre-training (i.e., the first-stage training) is to align the vision encoder and the LLM through end-toend training on large-scale image-text pairs [827, 828].” (Zhao et al., 2023, p. 76) 视觉语言对齐预训练。为了开发 MLLM,现有工作主要使用预训练模型来初始化视觉编码器和 LLM [149,150,826]。这些模型保留了出色的视觉和语言能力,但跨越了不同的语义空间。因此,视觉语言对齐预训练(即第一阶段训练)的目标是通过大规模图像文本对的端到端训练来对齐视觉编码器和LLM [827, 828]。
“Visual instruction tuning. After vision-language pretraining, the second-stage training, i.e., visual instruction tuning, aims to improve the instruction-following and tasksolving abilities of MLLMs.” (Zhao et al., 2023, p. 76) 视觉指令调整。在视觉语言预训练之后,第二阶段训练,即视觉指令调整,旨在提高 MLLM 的指令跟踪和任务解决能力。
“Model training. Different from LLMs, MLLMs are not trained from scratch, but instead developed based on pretrained language and vision models. Existing work employs a typical two-stage approach for training MLLMs, i.e., vision-language alignment pre-training and visual instruction tuning.” (Zhao et al., 2023, p. 78) 模型训练。与 LLM 不同,MLLM 不是从头开始训练,而是基于预训练的语言和视觉模型进行开发。现有工作采用典型的两阶段方法来训练 MLLM,即视觉语言对齐预训练和视觉指令调整。
“For the first issue (i.e., retrieving relevant knowledge), a typical approach is to train a small language model (e.g., RoBERTa) to identify question-related fact triples [866]. To further improve the retrieval performance, several studies also propose an iterative reading-then-reasoning framework, enabling the LLM to interact with the KG multiple times and acquire the required knowledge in a more accurate way [458].” (Zhao et al., 2023, p. 78) 对于第一个问题(即检索相关知识),典型的方法是训练小型语言模型(例如 RoBERTa)来识别与问题相关的事实三元组 [866]。为了进一步提高检索性能,一些研究还提出了迭代阅读推理框架,使法学硕士能够与知识图谱多次交互,并以更准确的方式获取所需的知识[458]。
“Synergy-Augmented LLM. To solve complex tasks (e.g., multi-hop question answering [656]), it often requires LLMs to query a KG multiple times, following a systematic solution plan. We call such a multi-turn interaction approach to enhancing LLM synergy-augmented LLM. To better synergize the LLM and KG in a complementary manner, recent studies propose to decompose the complex task into multiple subgoals and iteratively solve each one by leveraging the necessary knowledge from KG [458, 870, 871].” (Zhao et al., 2023, p. 78) 协同增强法学硕士。为了解决复杂的任务(例如,多跳问答[656]),通常需要法学硕士按照系统的解决方案多次查询知识图谱。我们将这种多轮交互增强LLM的方法称为协同增强LLM。为了更好地以互补的方式协同 LLM 和 KG,最近的研究建议将复杂的任务分解为多个子目标,并利用 KG 中的必要知识迭代地解决每个子目标 [458,870,871]。
“Components. Typically, there are three main components in an LLM-based agent: memory, planning50, and execution. Specifically, the memory component aims to store the information perceived from the environment and can be utilized to support decision-making.” (Zhao et al., 2023, p. 79) 成分。通常,基于 LLM 的代理包含三个主要组件:内存、规划50 和执行。具体来说,记忆组件旨在存储从环境中感知到的信息,并可用于支持决策。
“Workflow. With the three components mentioned above, a typical workflow of an LLM-based agent is as follows. First, it receives information from the environment and writes it into short-term memory. Then, the agent processes the newly received information in the short-term memory. Such a process can be enhanced with information retrieved from long-term memory. Subsequently, the planning component utilizes the processed information from short-term memory to generate the next plan. Finally, the execution component carries out the plan generated from the planning component, which can be further assisted with external tools. By repeating the aforementioned process, the LLM-based agent can autonomously adjust its behavior in response to feedback from the environment and ultimately achieve its goal. Once LLM-based agents receive user requests or are assigned goals, they follow the above workflow to accomplish tasks through multi-turn interactions with the environment” (Zhao et al., 2023, p. 79) 工作流程。有了上述三个组件,基于 LLM 的代理的典型工作流程如下。首先,它从环境接收信息并将其写入短期记忆。然后,代理在短期记忆中处理新接收到的信息。这种过程可以通过从长期记忆中检索到的信息来增强。随后,规划组件利用短期记忆中经过处理的信息来生成下一个计划。最后,执行组件执行规划组件生成的计划,可以通过外部工具进一步辅助。通过重复上述过程,基于LLM的智能体可以根据环境的反馈自主调整其行为,最终实现其目标。一旦基于LLM的代理收到用户请求或被分配目标,它们就会遵循上述工作流程,通过与环境的多轮交互来完成任务
“Recently, with the emergence of LLMs as general task solvers highlights their potential as automatic evaluators [647, 727], making it promising to conduct LLM based evaluation.” (Zhao et al., 2023, p. 80) 最近,随着法学硕士作为通用任务求解器的出现,凸显了它们作为自动评估器的潜力[647, 727],使得基于法学硕士的评估有希望进行。
“Basics and Principles. Instead of training on specific task goals, LLMs learn from unsupervised pre-training on largescale text data. This is quite different from previous multitask learning approaches, which aim to extend the training tasks as possible to achieve sufficient generalization. Thus, it is essential to reveal the basic principles or elements that establish the foundation of the abilities of LLMs.” (Zhao et al., 2023, p. 82) 基础知识和原则。法学硕士不是针对特定任务目标进行培训,而是从大规模文本数据的无监督预培训中学习。这与以前的多任务学习方法有很大不同,以前的多任务学习方法旨在尽可能扩展训练任务以实现足够的泛化。因此,有必要揭示奠定法学硕士能力基础的基本原则或要素。