Bianchi, F., Terragni, S., & Hovy, D. (2021). Pre-training is a Hot Topic: Contextualized Document Embeddings Improve Topic Coherence. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), 759–766. https://doi.org/10.18653/v1/2021.acl-short.96
“Topic models extract groups of words from documents, whose interpretation as a topic hopefully allows for a better understanding of the data. However, the resulting word groups are often not coherent, making them harder to interpret.” (Bianchi 等, 2021, p. 759) 主题模型从文档中提取词组,将其解释为主题有望更好地理解数据。然而,由此产生的词组往往不连贯,使它们更难解释。
“In this paper, we combine contextualized representations with neural topic models.” (Bianchi 等, 2021, p. 759) 在本文中,我们将上下文表示与神经主题模型相结合。
“We find that our approach produces more meaningful and coherent topics than traditional bag-of-words topic models and recent neural models.” (Bianchi 等, 2021, p. 759) 我们发现我们的方法比传统的词袋主题模型和最近的神经模型产生更有意义和连贯的主题。
“One of the crucial issues with topic models is the quality of the topics they discover. Coherent topics are easier to interpret and are considered more meaningful.” (Bianchi 等, 2021, p. 759) 主题模型的关键问题之一是它们发现的主题的质量。连贯的主题更容易解释,也被认为更有意义。
“Coherence can be measured in numerous ways, from human evaluation via intrusion tests (Chang et al., 2009) to approximated scores (Lau et al., 2014; R ̈ oder et al., 2015).” (Bianchi 等, 2021, p. 759) 一致性可以通过多种方式衡量,从通过入侵测试进行的人类评估(Chang 等人,2009 年)到近似分数(Lau 等人,2014 年;R ̈ oder 等人,2015 年)。
“BoW models represent the input in an inherently incoherent manner.” (Bianchi 等, 2021, p. 759) BoW 模型以一种固有的不连贯方式表示输入。
“Various extensions of topic models incorporate several types of information (Xun et al., 2017; Zhao et al., 2017; Terragni et al., 2020a), use word relationships derived from external knowledge bases (Chen et al., 2013; Yang et al., 2015; Terragni et al., 2020b), or pre-trained word embeddings (Das et al., 2015; Dieng et al., 2020; Nguyen et al., 2015; Zhao et al., 2017). Even for neural topic models, there exists work on incorporating external knowledge, e.g., via word embeddings (Gupta et al., 2019, 2020; Dieng et al., 2020).” (Bianchi 等, 2021, p. 759) 主题模型的各种扩展包含多种类型的信息(Xun et al., 2017; Zhao et al., 2017; Terragni et al., 2020a),使用来自外部知识库的词关系(Chen et al., 2013; Yang等人,2015 年;Terragni 等人,2020b)或预训练词嵌入(Das 等人,2015 年;Dieng 等人,2020 年;Nguyen 等人,2015 年;Zhao 等人,2017 年)。即使对于神经主题模型,也存在整合外部知识的工作,例如,通过词嵌入(Gupta et al., 2019, 2020; Dieng et al., 2020)。
“In this paper, we show that adding contextual information to neural topic models provides a significant increase in topic coherence. This effect is even more remarkable given that we cannot embed long documents due to the sentence length limit in recent pre-trained language models architectures.” (Bianchi 等, 2021, p. 759) 在本文中,我们展示了将上下文信息添加到神经主题模型可以显着提高主题连贯性。由于最近的预训练语言模型体系结构中的句子长度限制,我们无法嵌入长文档,因此这种效果更加显着。
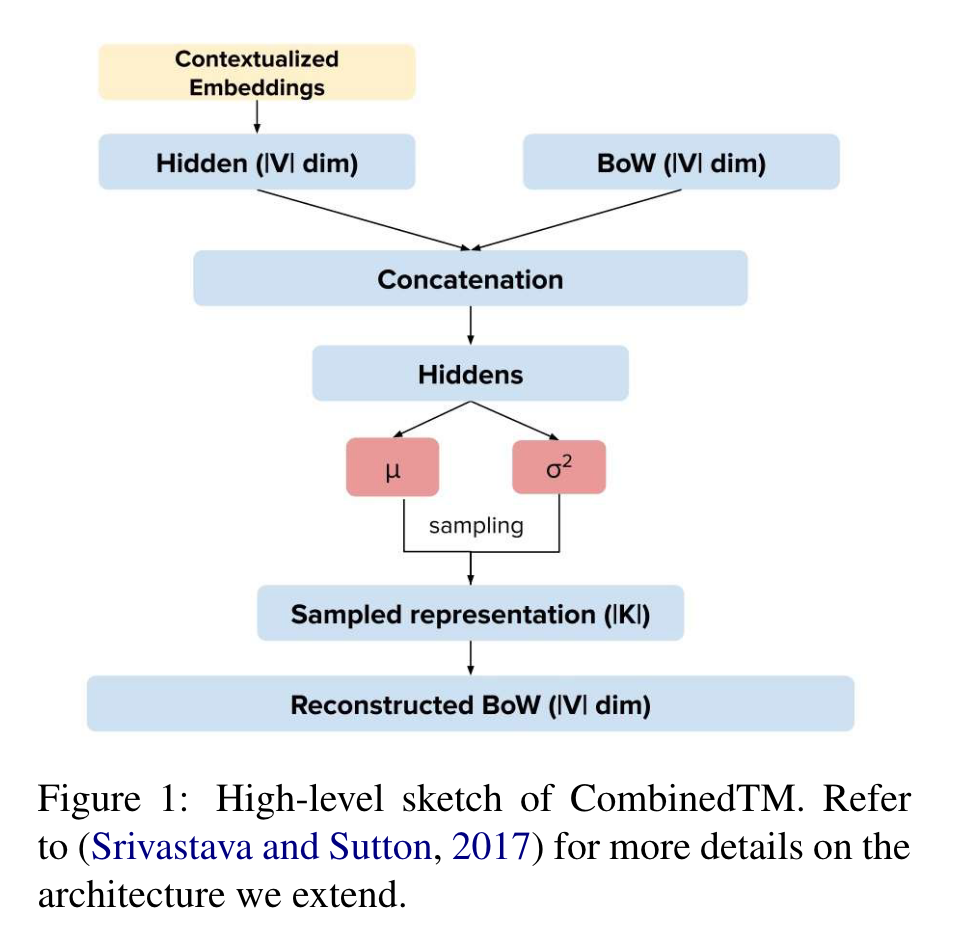
“Concretely, we extend Neural ProdLDA (Product-of-Experts LDA) (Srivastava and Sutton, 2017), a state-of-the-art topic model that implements black-box variational inference (Ranganath et al., 2014), to include contextualized representations.” (Bianchi 等, 2021, p. 759) 具体而言,我们扩展了 Neural ProdLDA(专家产品 LDA)(Srivastava 和 Sutton,2017 年),这是一种实现黑盒变分推理的最先进主题模型(Ranganath 等人,2014 年),以包括上下文表示。
“Our results suggest that topic models benefit from latent contextual information, which is missing in BoW representations.” (Bianchi 等, 2021, p. 760) 我们的结果表明,主题模型受益于潜在的上下文信息,而这在 BoW 表示中是缺失的。
“Let us notice that our method is indeed agnostic about the choice of the topic model and the pre-trained representations, as long as the topic model extends an autoencoder and the pre-trained representations embed the documents.” (Bianchi 等, 2021, p. 760) 让我们注意到,我们的方法确实对主题模型和预训练表示的选择不可知,只要主题模型扩展了自动编码器并且预训练表示嵌入了文档。
“ProdLDA is a neural topic modeling approach based on the Variational AutoEncoder (VAE). The neural variational framework trains a neural inference network to directly map the BoW document representation into a continuous latent representation. Then, a decoder network reconstructs the BoW by generating its words from the latent document representation1. The framework explicitly approximates the Dirichlet prior using Gaussian distributions, instead of using a Gaussian prior like Neural Variational Document Models (Miao et al., 2016). Moreover, ProdLDA replaces the multinomial distribution over individual words in LDA with a product of experts (Hinton, 2002).” (Bianchi 等, 2021, p. 760) ProdLDA 是一种基于变分自动编码器 (VAE) 的神经主题建模方法。神经变分框架训练神经推理网络将 BoW 文档表示直接映射为连续的潜在表示。然后,解码器网络通过从潜在文档表示 1 生成其单词来重建 BoW。该框架使用高斯分布显式地近似狄利克雷先验,而不是像神经变分文档模型那样使用高斯先验(Miao 等人,2016 年)。此外,ProdLDA 将 LDA 中单个单词的多项式分布替换为专家的产品 (Hinton, 2002)。
“We extend this model with contextualized document embeddings from SBERT (Reimers and Gurevych, 2019),2 a recent extension of BERT that allows the quick generation of sentence embeddings” (Bianchi 等, 2021, p. 760) 我们使用 SBERT(Reimers 和 Gurevych,2019 年)2 的上下文化文档嵌入扩展了该模型,这是 BERT 的最新扩展,可以快速生成句子嵌入
“e use a similar pipeline for 20NewsGroups and Wiki20K: removing digits, punctuation, stopwords, and infrequent words.” (Bianchi 等, 2021, p. 760) e 对 20NewsGroups 和 Wiki20K 使用类似的管道:删除数字、标点符号、停用词和不常用词。
“The sentence encoding model used is the pretrained RoBERTa model fine-tuned on SNLI (Bowman et al., 2015), MNLI (Williams et al., 2018)” (Bianchi 等, 2021, p. 761) 使用的句子编码模型是在 SNLI (Bowman et al., 2015)、MNLI (Williams et al., 2018) 上微调的预训练 RoBERTa 模型
“We evaluate each model on three different metrics: two for topic coherence (normalized pointwise mutual information and a word-embedding based measure) and one metric to quantify the diversity of the topic solutions.” (Bianchi 等, 2021, p. 761) 我们根据三个不同的指标评估每个模型:两个用于主题连贯性(归一化逐点互信息和基于词嵌入的度量)和一个用于量化主题解决方案多样性的指标。
“Normalized Pointwise Mutual Information (τ ) (Lau et al., 2014) measures how related the top-10 words of a topic are to each other, considering the words’ empirical frequency in the original corpus.” (Bianchi 等, 2021, p. 761) Normalized Pointwise Mutual Information (τ)(Lau 等人,2014 年)衡量一个主题的前 10 个单词彼此之间的相关性,考虑单词在原始语料库中的经验频率。
“External word embeddings topic coherence (α) provides an additional measure of how similar the words in a topic are.” (Bianchi 等, 2021, p. 761) External word embeddings topic coherence (α) 提供了一个额外的衡量主题中单词相似程度的方法。
“We follow Ding et al. (2018) and first compute the average pairwise cosine similarity of the word embeddings of the top-10 words in a topic, using Mikolov et al. (2013) embeddings.” (Bianchi 等, 2021, p. 761) 我们跟随丁等人。 (2018) 并首先使用 Mikolov 等人计算主题中前 10 个词的词嵌入的平均成对余弦相似度。 (2013)嵌入。
“Inversed Rank-Biased Overlap (ρ) evaluates how diverse the topics generated by a single model are.” (Bianchi 等, 2021, p. 761) Inversed Rank-Biased Overlap (ρ) 评估单个模型生成的主题的多样性。
“RBO (Webber et al., 2010; Terragni et al., 2021b). RBO compares the 10-top words of two topics. It allows disjointedness between the lists of topics (i.e., two topics can have different words in them) and uses weighted ranking. I.e., two lists that share some of the same words, albeit at different rankings, are penalized less than two lists that share the same words at the highest ranks.” (Bianchi 等, 2021, p. 761) RBO(Webber 等人,2010 年;Terragni 等人,2021b)。 RBO 比较两个主题的前 10 个词。它允许主题列表之间的脱节(即,两个主题中可以有不同的词)并使用加权排名。即,尽管排名不同,但共享一些相同单词的两个列表受到的惩罚少于共享最高排名的相同单词的两个列表。
“ETM shows good external coherence (α), especially in 20NewsGroups and StackOverflow. However, it fails at obtaining a good τ coherence for short texts. Moreover, ρ shows that the topics are very similar to one another. A manual inspection of the topics confirmed this problem.” (Bianchi 等, 2021, p. 762) ETM 显示出良好的外部一致性 (α),尤其是在 20NewsGroups 和 StackOverflow 中。然而,它无法为短文本获得良好的 τ 一致性。此外,ρ 表明主题彼此非常相似。对主题的手动检查证实了这个问题。
“We compare the performance of CombinedTM using two different models for embedding the contextualized representations found in the SBERT repository:8 stsb-roberta-large (Ours-R), as employed in the previous experimental setting, and using bert-base-nli-means (Ours-B).” (Bianchi 等, 2021, p. 762) 我们比较了 CombinedTM 的性能,使用两种不同的模型来嵌入在 SBERT 存储库中找到的上下文表示:8 stsb-roberta-large (Ours-R),如在先前的实验设置中使用的,并使用 bert-base-nli-means (我们的-B)。
“This result suggests that including novel and better contextualized embeddings can further improve a topic model’s performance.” (Bianchi 等, 2021, p. 763) 这一结果表明,包括新颖的和更好的上下文嵌入可以进一步提高主题模型的性能。