Kotnis, B., Gashteovski, K., Gastinger, J., Serra, G., Alesiani, F., Sztyler, T., Shaker, A., Gong, N., Lawrence, C., & Xu, Z. (2022). Human-Centric Research for NLP: Towards a Definition and Guiding Questions (arXiv:2207.04447). arXiv. https://doi.org/10.48550/arXiv.2207.04447
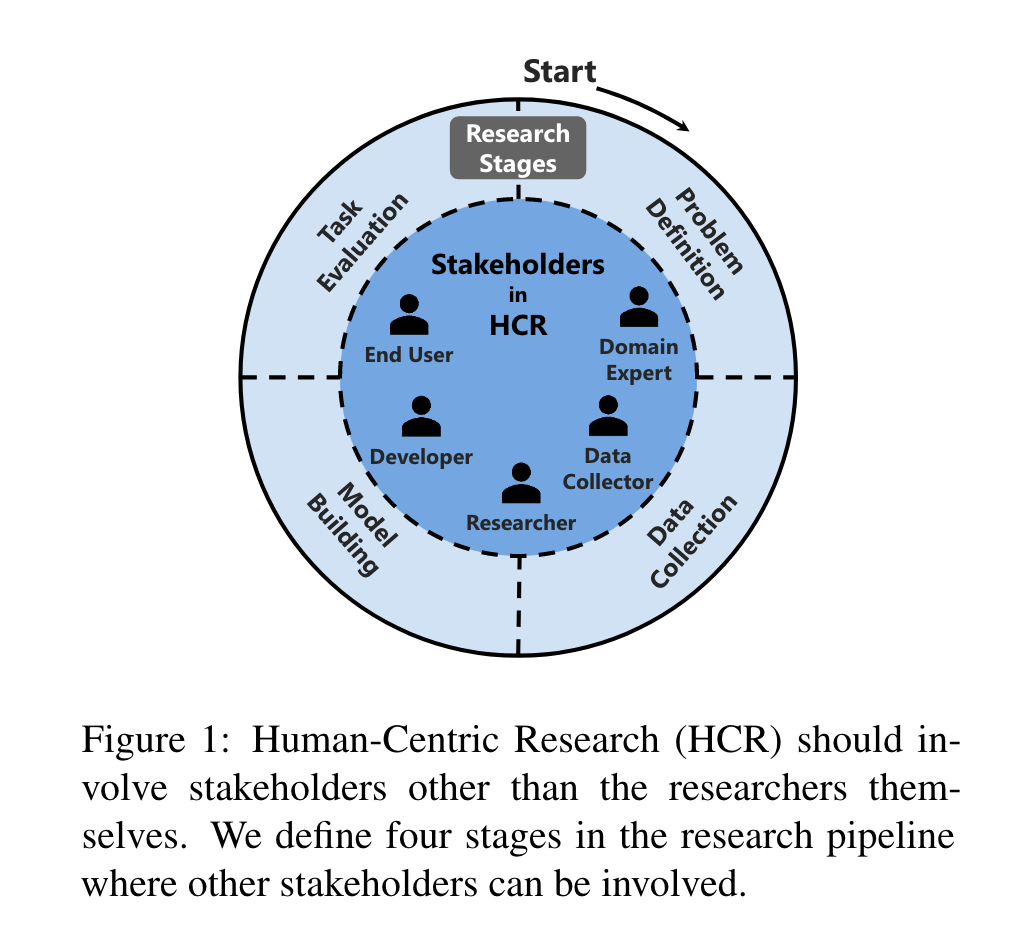
“We address this question by providing a working definition and define how a research pipeline can be split into different stages in which human-centric components can be added.” (Kotnis et al., 2022, p. 1) 🔤我们通过提供一个工作定义来解决这个问题,并定义如何将研究管道分为不同的阶段,在这些阶段可以添加以人为中心的组件。🔤
“However, such research is not necessarily human-centric: the research questions and the methods for answering them are often entirely designed and implemented by the researchers and their intuition.” (Kotnis et al., 2022, p. 1) 🔤然而,这样的研究不一定以人为中心:研究问题和回答问题的方法往往完全由研究人员和他们的直觉设计和实施。🔤
“In contrast, Human-Centric Research (HCR) aims to ensure that human stakeholders benefit from the outcome of the research. The stakeholders are people that have a stake in the research outcome and may include researchers, end users, data collectors, feedback providers or domain experts.” (Kotnis et al., 2022, p. 1) 🔤相比之下,以人为本的研究 (HCR) 旨在确保人类利益相关者从研究结果中受益。利益相关者是与研究成果有利害关系的人,可能包括研究人员、最终用户、数据收集者、反馈提供者或领域专家。🔤
“Not involving external stakeholders introduces the risk of spending great amounts of time and resources in solving problems that might turn out to be irrelevant in practical settings.” (Kotnis et al., 2022, p. 1) 🔤不让外部利益相关者参与会带来花费大量时间和资源来解决在实际环境中可能无关紧要的问题的风险。🔤
“Problem Definition. The goal is to study the real needs of target users—rather than relying on the intuition of the researchers—and identify the gap between existing methods and user demands (Liao et al., 2020; Hong et al., 2021). This then serves as the basis to formulate the research problem” (Kotnis et al., 2022, p. 2) 🔤问题定义。目标是研究目标用户的真实需求——而不是依赖研究人员的直觉——并找出现有方法与用户需求之间的差距(Liao et al., 2020; Hong et al., 2021)。这将作为制定研究问题的基础🔤
“Data Collection. Either external stakeholders are directly involved in the data collection from planning to execution (Nekoto et al., 2020), or the researchers use insights from the external stakeholders, which were obtained in the problem definition stage, to set up the data collection process.” (Kotnis et al., 2022, p. 2) 🔤数据采集。要么外部利益相关者直接参与从计划到执行的数据收集(Nekoto 等人,2020),要么研究人员使用在问题定义阶段获得的外部利益相关者的见解来设置数据收集过程。🔤
“Model Building. There are two possible ways in which external stakeholders can impact the model building stage. (1) stakeholders may be involved before or after the training process; (2) stakeholders can be involved during model inference stage (Kulesza et al., 2015; Smith et al., 2018; Koh and Liang, 2017).” (Kotnis et al., 2022, p. 2) 🔤建筑模型。外部利益相关者可以通过两种可能的方式影响模型构建阶段。 (1) 利益相关者可能在培训过程之前或之后参与; (2) 利益相关者可以在模型推理阶段参与(Kulesza 等人,2015 年;Smith 等人,2018 年;Koh 和 Liang,2017 年)。🔤
“Task Evaluation. Instead of—or in addition to—using automatic leaderboards or crowdsourced evaluations whose task is defined by researchers, systems are evaluated given requirements defined by external stakeholders (Ehsan et al., 2021; Lakkaraju et al., 2022).” (Kotnis et al., 2022, p. 2) 🔤任务评估。除了使用由研究人员定义任务的自动排行榜或众包评估之外,系统还根据外部利益相关者定义的要求来评估系统(Ehsan 等人,2021 年;Lakkaraju 等人,2022 年)。🔤
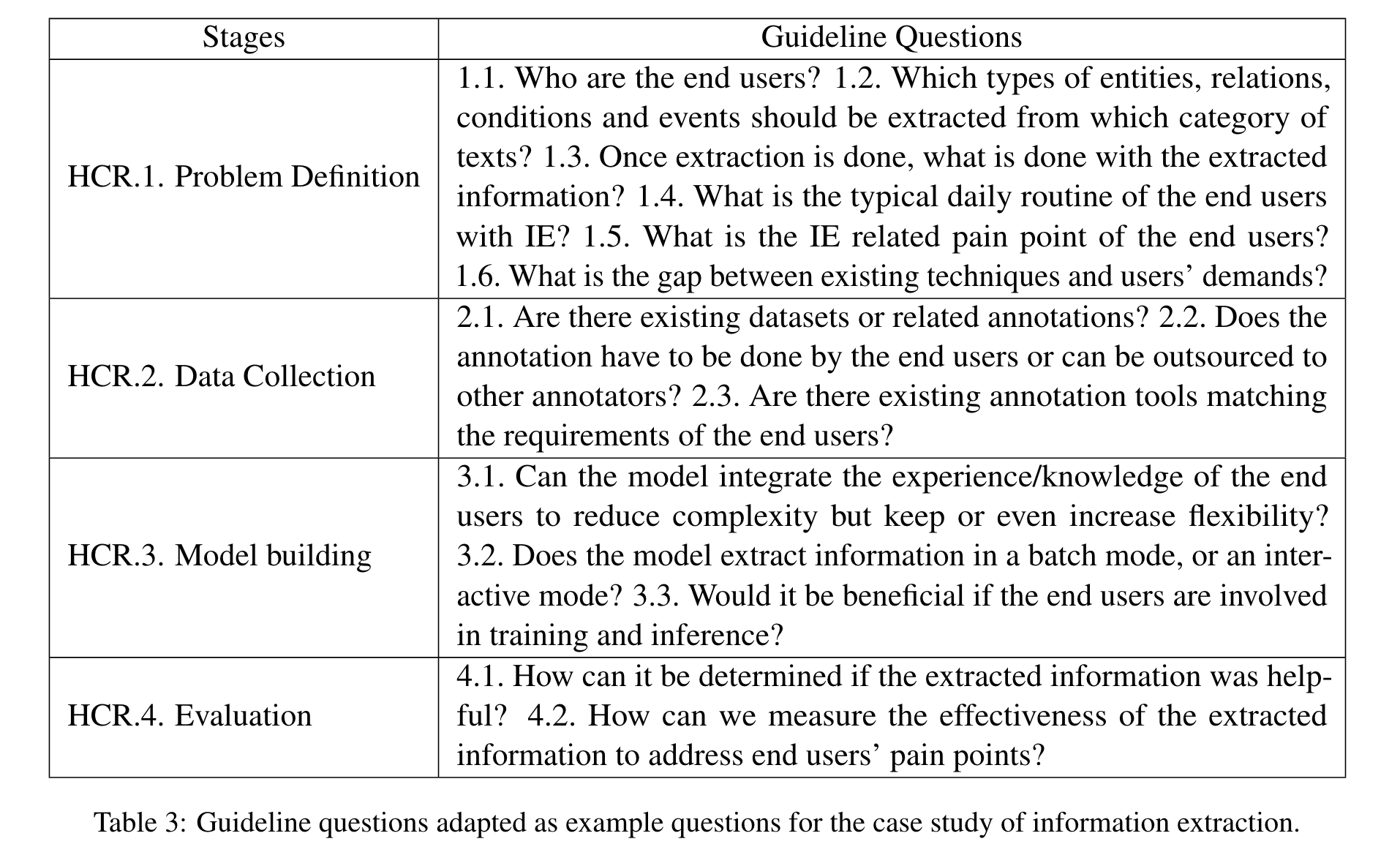
“To address this gap, we formulate four blocks of guiding questions that can help to make the problem definition of a research project more human-centric.” (Kotnis et al., 2022, p. 2) 为了弥补这一差距,我们制定了四个指导问题块,有助于使研究项目的问题定义更加以人为本。
🔤为了弥补这一差距,我们制定了四个指导问题块,有助于使研究项目的问题定义更加以人为本。🔤
“Selection: Which NLP task will be tackled? What methods should be used?” (Kotnis et al., 2022, p. 2) 🔤选择:将处理哪个 NLP 任务?应该使用什么方法?🔤
“Stakeholders: Who are the stakeholders, what are their characteristics?” (Kotnis et al., 2022, p. 2) 🔤利益相关者:利益相关者是谁,他们有什么特点?🔤
“Who operates the system, who owns it? Who shall be the target stakeholder?” (Kotnis et al., 2022, p. 3) 🔤谁操作该系统,谁拥有它?谁应该是目标利益相关者?🔤
“Pain points: What are the pain points for the target stakeholder?” (Kotnis et al., 2022, p. 3) 🔤痛点:目标利益相关者的痛点是什么?🔤
“Research question: What are the shortcomings of existing methods? What research question should we ask to address these shortcomings in a research project?” (Kotnis et al., 2022, p. 3) 🔤研究问题:现有方法的缺点是什么?我们应该提出什么研究问题来解决研究项目中的这些缺点?🔤
“Typically the research is now conducted by the researchers without any additional outside input.” (Kotnis et al., 2022, p. 3) 通常,研究现在由研究人员进行,没有任何额外的外部输入。
🔤通常,研究现在由研究人员进行,没有任何额外的外部输入。🔤
“In contrast, in a more human-centric view, researchers could first identify and involve stakeholders to derive a problem definition that would directly benefit the stakeholders by addressing their pain points in the area of research identified by the researchers.” (Kotnis et al., 2022, p. 3) 相比之下,在更以人为本的观点中,研究人员可以首先确定利益相关者并让他们参与进来,以得出一个问题定义,该定义将通过解决利益相关者在研究人员确定的研究领域中的痛点来直接使利益相关者受益。
🔤相比之下,在更以人为本的观点中,研究人员可以首先确定利益相关者并让他们参与进来,以得出一个问题定义,该定义将通过解决利益相关者在研究人员确定的研究领域中的痛点来直接使利益相关者受益。🔤
“Once a pain point to be addressed is defined, researchers should determine how well existing technology is able to address the defined problem.” (Kotnis et al., 2022, p. 3) 一旦定义了要解决的痛点,研究人员就应该确定现有技术能够在多大程度上解决定义的问题。
🔤一旦定义了要解决的痛点,研究人员就应该确定现有技术能够在多大程度上解决定义的问题。🔤
“Once the task is chosen, the researchers should explore promising existing methods which can solve the task.” (Kotnis et al., 2022, p. 3) 一旦选择了任务,研究人员就应该探索可以解决任务的有前途的现有方法。
🔤一旦选择了任务,研究人员就应该探索可以解决任务的有前途的现有方法。🔤
“The design of training datasets as well as systems that support data collection, are crucial for creating effective human-centric NLP systems.” (Kotnis et al., 2022, p. 3) 训练数据集的设计以及支持数据收集的系统对于创建有效的以人为本的 NLP 系统至关重要。
🔤训练数据集的设计以及支持数据收集的系统对于创建有效的以人为本的 NLP 系统至关重要。🔤
“For example, the standard crowdsourcing procedures could be intuitively considered as human-centric, because the data is collected with human input from non-researchers.” (Kotnis et al., 2022, p. 3) 例如,标准的众包程序可以直观地被认为是以人为中心的,因为数据是通过非研究人员的人工输入收集的。
🔤例如,标准的众包程序可以直观地被认为是以人为中心的,因为数据是通过非研究人员的人工输入收集的。🔤
“Therefore, the process lacks creative human input from non-researchers, with which more meaningful data could be collected.” (Kotnis et al., 2022, p. 3) 因此,该过程缺乏来自非研究人员的创造性人力投入,可以收集更有意义的数据。
🔤因此,该过程缺乏来自非研究人员的创造性人力投入,可以收集更有意义的数据。🔤
“Prior work on human-centric data collection includes (1) system that facilities domain knowledge acquisition from domain experts (Park et al., 2021), (2) collection process that is gamified, e.g. by asking users to generate text in a role playing game (Akoury et al., 2020), or (3) systems for machinehuman co-creation (Clark et al., 2018; Iskender et al., 2020; Tintarev et al., 2016).” (Kotnis et al., 2022, p. 3) 以人为中心的数据收集的先前工作包括 (1) 促进从领域专家那里获取领域知识的系统 (Park 等人,2021),(2) 游戏化的收集过程,例如通过要求用户在角色扮演游戏中生成文本(Akoury 等人,2020 年),或 (3) 人机共创系统(Clark 等人,2018 年;Iskender 等人,2020 年;Tintarev 等人, 2016 年)。
🔤以人为中心的数据收集的先前工作包括 (1) 促进从领域专家那里获取领域知识的系统 (Park 等人,2021),(2) 游戏化的收集过程,例如通过要求用户在角色扮演游戏中生成文本(Akoury 等人,2020 年),或 (3) 人机共创系统(Clark 等人,2018 年;Iskender 等人,2020 年;Tintarev 等人, 2016 年)。🔤
“The above examples demonstrate that NLP data generation tasks can benefit from creative and human-centric implementation of the data collection stage.” (Kotnis et al., 2022, p. 3) 上面的例子表明,NLP 数据生成任务可以从数据收集阶段的创造性和以人为中心的实施中受益。
🔤上面的例子表明,NLP 数据生成任务可以从数据收集阶段的创造性和以人为中心的实施中受益。🔤
“Data: What data needs to be collected to solve the pain points of the end users?” (Kotnis et al., 2022, p. 3) 数据:需要收集哪些数据来解决终端用户的痛点?
🔤数据:需要收集哪些数据来解决终端用户的痛点?🔤
“Annotation: Who is qualified to annotate?” (Kotnis et al., 2022, p. 3) 注释:谁有资格注释?
🔤注释:谁有资格注释?🔤
“Collection Approach: How should the annotation be done?” (Kotnis et al., 2022, p. 3) 采集方法:注解应该怎么做?
🔤采集方法:注解应该怎么做?🔤
“To address the above questions, ensure that all important angles are considered as well as offer transparency w.r.t. to the collected data for all stakeholders, we recommend the guide on creating datasheets for new datasets by Gebru et al. (2021).” (Kotnis et al., 2022, p. 3) 要解决上述问题,请确保考虑所有重要角度并提供透明度 w.r.t.对于为所有利益相关者收集的数据,我们推荐 Gebru 等人为新数据集创建数据表的指南。 (2021)。
🔤要解决上述问题,请确保考虑所有重要角度并提供透明度 w.r.t.对于为所有利益相关者收集的数据,我们推荐 Gebru 等人为新数据集创建数据表的指南。 (2021)。🔤
“Model building includes (1) defining the model and the training process, and (2) specifying the inference strategy.” (Kotnis et al., 2022, p. 3) 模型构建包括(1)定义模型和训练过程,以及(2)指定推理策略。
🔤模型构建包括(1)定义模型和训练过程,以及(2)指定推理策略。🔤
“Overall, the type of human-machine interaction during the model building shapes whether it is a human-in-the-loop (Smith et al., 2018; Yuksel et al., 2020; Khashabi et al., 2021) or machine-inthe-loop (Clark et al., 2018).” (Kotnis et al., 2022, p. 3) 总体而言,模型构建过程中人机交互的类型决定了它是人在环路中(Smith 等人,2018 年;Yuksel 等人,2020 年;Khashabi 等人,2021 年)还是机器-在循环中(Clark 等人,2018 年)。
🔤总体而言,模型构建过程中人机交互的类型决定了它是人在环路中(Smith 等人,2018 年;Yuksel 等人,2020 年;Khashabi 等人,2021 年)还是机器-在循环中(Clark 等人,2018 年)。🔤
“The former means the user intervenes with the system operation, and the latter happens when the system’s support is triggered by the user to finish a task.” (Kotnis et al., 2022, p. 3) 前者是用户干预系统运行,后者是用户触发系统支持完成任务。
🔤前者是用户干预系统运行,后者是用户触发系统支持完成任务。🔤
“Prototype: Can the designed model fulfil the external stakeholders’ expectations?” (Kotnis et al., 2022, p. 4) 原型:设计的模型能否满足外部利益相关者的期望?
🔤原型:设计的模型能否满足外部利益相关者的期望?🔤
“Inference: Should a stakeholder be involved in the inference process of the model?” (Kotnis et al., 2022, p. 4) 推理:利益相关者是否应该参与模型的推理过程?
🔤推理:利益相关者是否应该参与模型的推理过程?🔤
“To explore the answer to both questions, we recommend the researchers to repeatedly interact with the stakeholders in order to refine the prototype’s architecture and to understand how end users later want to interact with the model” (Kotnis et al., 2022, p. 4) 为了探索这两个问题的答案,我们建议研究人员反复与利益相关者互动,以完善原型的架构并了解最终用户以后希望如何与模型互动
🔤为了探索这两个问题的答案,我们建议研究人员反复与利益相关者互动,以完善原型的架构并了解最终用户以后希望如何与模型互动🔤
“While such automatic benchmarking provides quick evaluation—and, consequently, speeds up NLP research—such a metric may fail to capture the diverse needs of the end users (Ethayarajh and Jurafsky, 2020; Narayan et al., 2021).” (Kotnis et al., 2022, p. 4) 虽然这种自动基准测试提供了快速评估——并因此加快了 NLP 研究——但这种指标可能无法捕捉到最终用户的多样化需求(Ethayarajh 和 Jurafsky,2020 年;Narayan 等人,2021 年)。
🔤虽然这种自动基准测试提供了快速评估——并因此加快了 NLP 研究——但这种指标可能无法捕捉到最终用户的多样化需求(Ethayarajh 和 Jurafsky,2020 年;Narayan 等人,2021 年)。🔤
“While these works move into the right direction, they do not explicitly capture human reactions from stakeholders, such as whether a system meets expectations or which open pain-points remain and what future wishes exist.” (Kotnis et al., 2022, p. 4) 虽然这些工作朝着正确的方向发展,但它们并没有明确地捕捉利益相关者的人类反应,例如系统是否满足预期或仍然存在哪些开放的痛点以及未来存在什么愿望。
🔤虽然这些工作朝着正确的方向发展,但它们并没有明确地捕捉利益相关者的人类反应,例如系统是否满足预期或仍然存在哪些开放的痛点以及未来存在什么愿望。🔤
“Metric: What is a good evaluation measure?” (Kotnis et al., 2022, p. 4) 指标:什么是好的评估指标?
🔤指标:什么是好的评估指标?🔤
“Evaluator: Who evaluates the built model?” (Kotnis et al., 2022, p. 4) 评估者:谁评估构建的模型?
🔤评估者:谁评估构建的模型?🔤
“Level: At which level is the task evaluated?” (Kotnis et al., 2022, p. 4) 级别:在哪个级别评估任务?
🔤级别:在哪个级别评估任务?🔤
“Impact: What is done after the evaluation?” (Kotnis et al., 2022, p. 4) 影响:评估后做什么?
🔤影响:评估后做什么?🔤
“Together with external stakeholders, the researchers should determine the criteria for assessing if a stakeholder’s pain point is addressed by the model.” (Kotnis et al., 2022, p. 4) 研究人员应与外部利益相关者一起确定评估模型是否解决了利益相关者痛点的标准。
🔤研究人员应与外部利益相关者一起确定评估模型是否解决了利益相关者痛点的标准。🔤
“Therefore, following Doshi-Velez and Kim (2017), we propose an overall 3-step process for evaluation: (1) Non-HCR: perform an automatic evaluation to ensure the model output is reasonable. Since human evaluators can be a rare and/or costly resource, an automatic evaluation provides a baseline level for quality. (2) Towards HCR: recruit a human evaluator and evaluate on a pseudo-task. Due to time and cost constraints, it is often easier to find lay users (instead of e.g. a doctor) for evaluation. Additionally, if the real task is very complex, then a pseudo-task is helpful as a stepping stone; (3) HCR: ask the targeted stakeholder to evaluate the model built to solve their pain point(s).” (Kotnis et al., 2022, p. 4) 因此,在 Doshi-Velez 和 Kim(2017)之后,我们提出了一个整体的 3 步评估过程:(1)Non-HCR:执行自动评估以确保模型输出是合理的。由于人工评估员可能是一种稀有和/或昂贵的资源,因此自动评估提供了质量的基准水平。 (2) Towards HCR:招募人类评估员并对伪任务进行评估。由于时间和成本限制,通常更容易找到外行用户(而不是医生)进行评估。此外,如果真实任务非常复杂,那么伪任务作为垫脚石很有帮助; (3) HCR:要求目标利益相关者评估为解决他们的痛点而构建的模型。
🔤因此,在 Doshi-Velez 和 Kim(2017)之后,我们提出了一个整体的 3 步评估过程:(1)Non-HCR:执行自动评估以确保模型输出是合理的。由于人工评估员可能是一种稀有和/或昂贵的资源,因此自动评估提供了质量的基准水平。 (2) Towards HCR:招募人类评估员并对伪任务进行评估。由于时间和成本限制,通常更容易找到外行用户(而不是医生)进行评估。此外,如果真实任务非常复杂,那么伪任务作为垫脚石很有帮助; (3) HCR:要求目标利益相关者评估为解决他们的痛点而构建的模型。🔤
“Finally, researchers can observe or interview end users to understand if the model addresses their pain points, fulfils their needs etc.” (Kotnis et al., 2022, p. 4) 最后,研究人员可以观察或采访最终用户,以了解该模型是否解决了他们的痛点、满足了他们的需求等。
🔤最后,研究人员可以观察或采访最终用户,以了解该模型是否解决了他们的痛点、满足了他们的需求等。🔤