借助notion提供的api将豆瓣电影中观影记录同步至notion数据库中
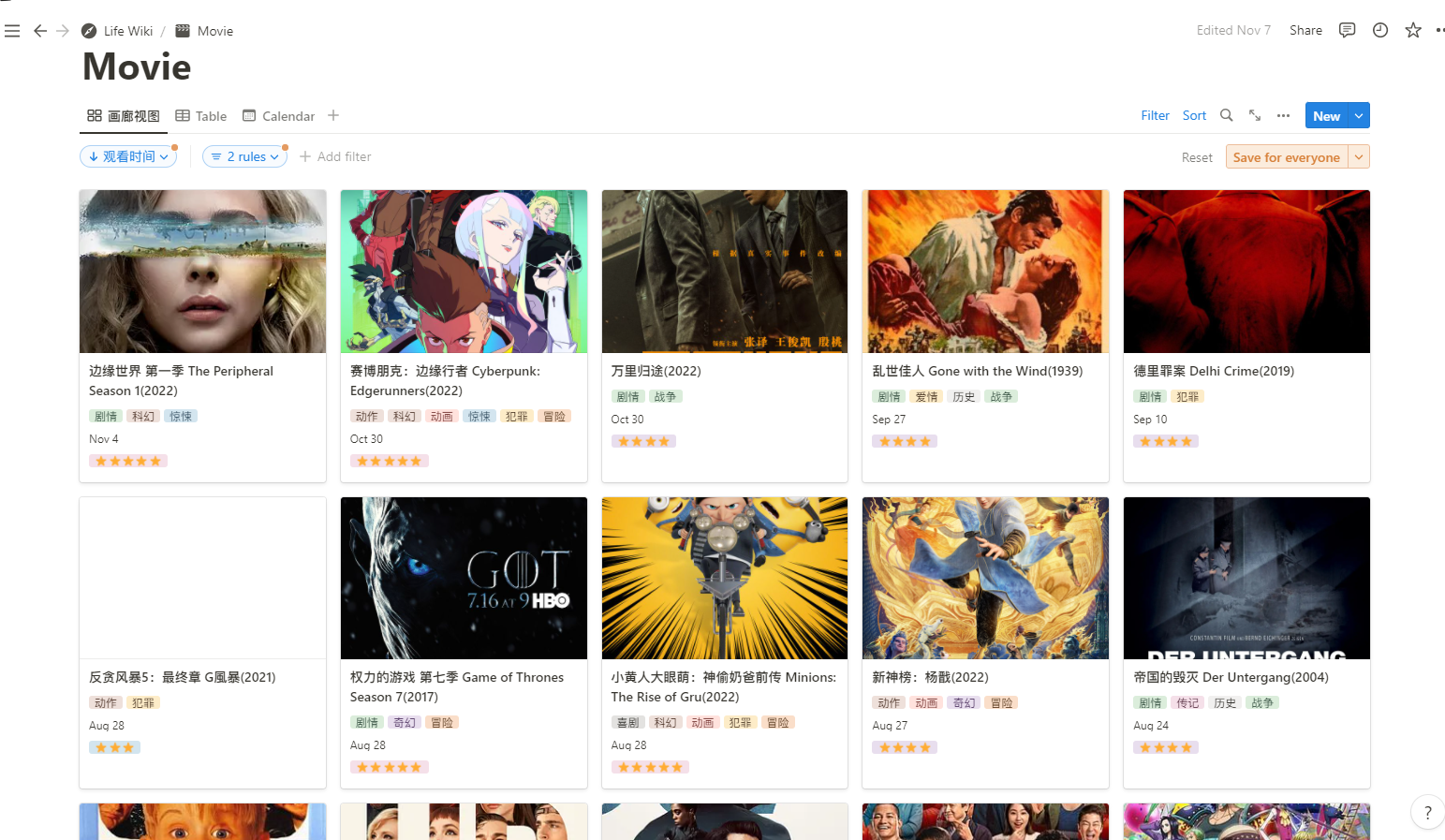
实现效果
文中所需要的代码
2022年11月13日更新
由于原来的代码上传有风险问题,现在自己的databaseid等需要修改的信息,统一通过新建一个config.py文件然后按照下图添加自己的配置文件
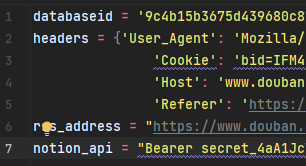
databaseid = ''
headers = {'User_Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0',
'Cookie': '',
'Host': 'www.douban.com',
'Referer': 'https://accounts.douban.com/'}
rss_address = ""
notion_api = "Bearer 你的密钥"
总体思路
先将看到的所有电影导出为csv文件,添加至notion数据库中,然后使用豆瓣api爬取账号下看到的电影动态。
所需工具
Python
beautifulsoup4==4.11.1
feedparser==6.0.8
requests==2.28.1
Tampermonkey
具体步骤
同步看过的电影
在greasyfork中下载豆瓣读书+电影+音乐+游戏+舞台剧导出工具安装至tampermonkey中
安装后在自己的豆瓣首页可以看到导出看过的片按钮
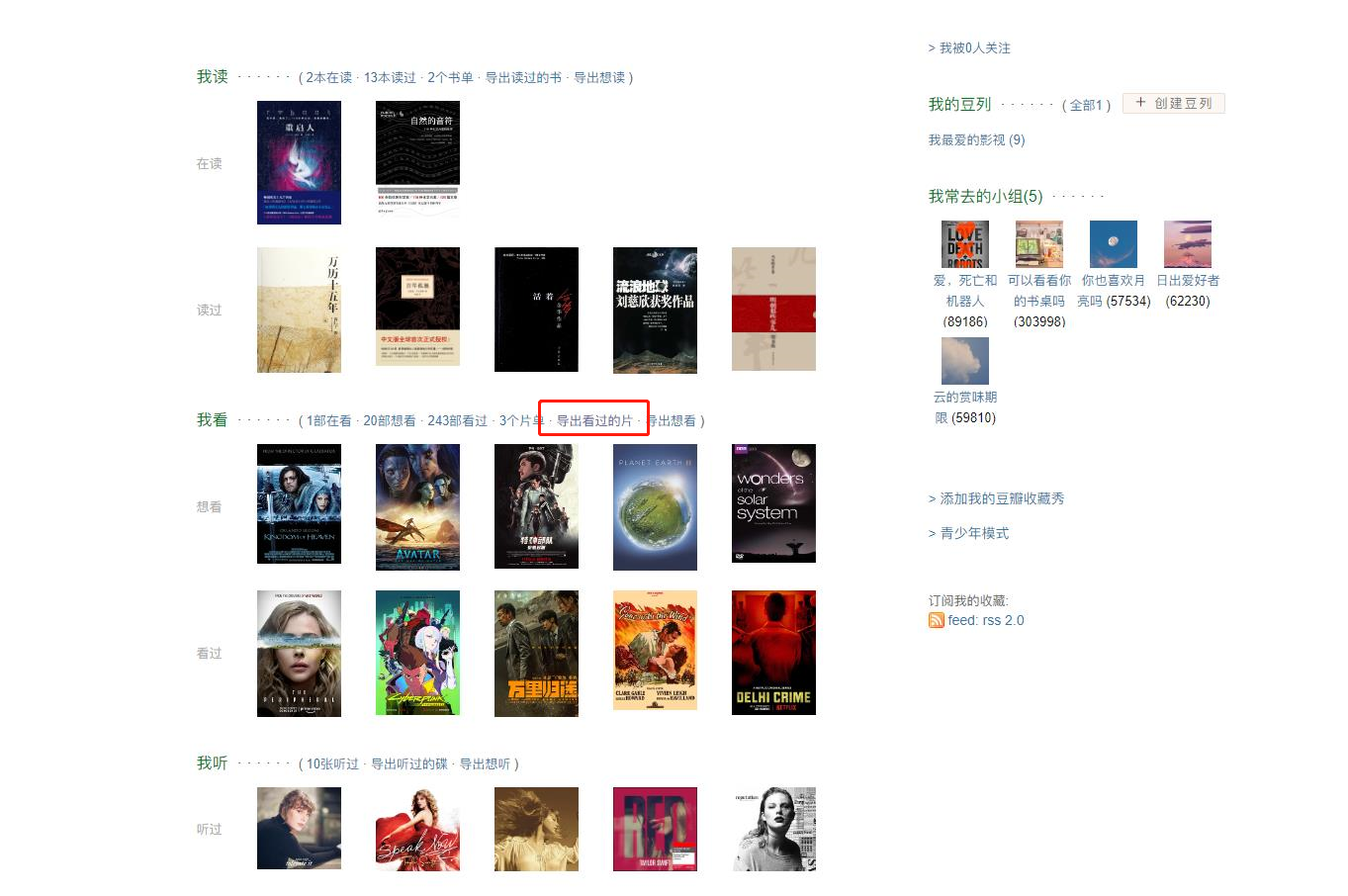 点击导出后为csv文件。
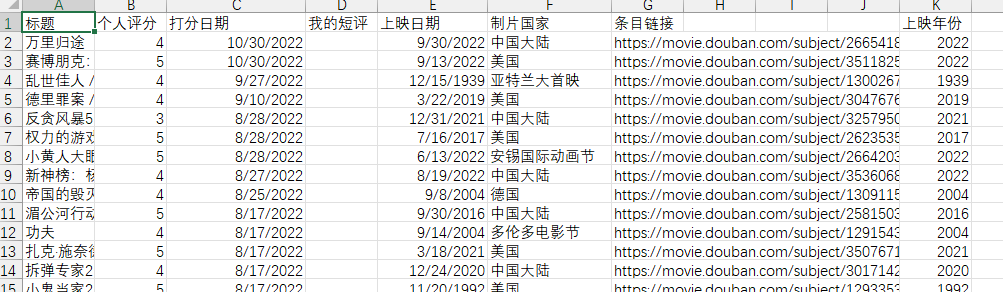
打开导出的csv文件在我这边直接导入notion当中会有一些问题。如果有问题可以修改为下面这种格式。
点击导出后为csv文件。
打开导出的csv文件在我这边直接导入notion当中会有一些问题。如果有问题可以修改为下面这种格式。
 随后导入至notion当中,选择csv格式
随后导入至notion当中,选择csv格式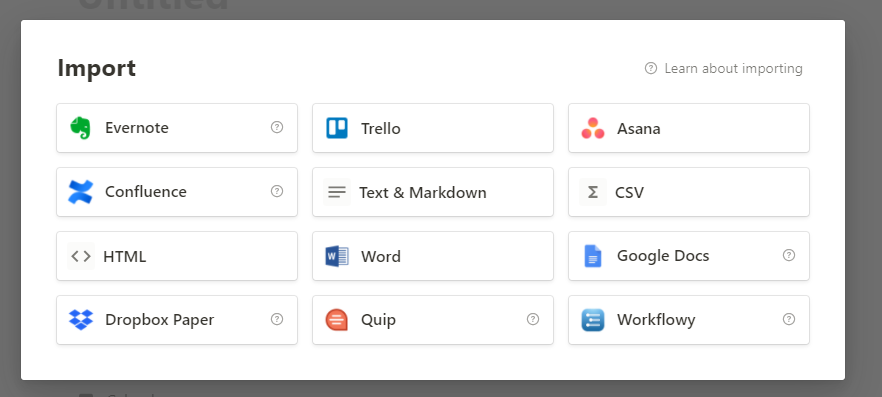
获取数据库id以及notion机器人密钥
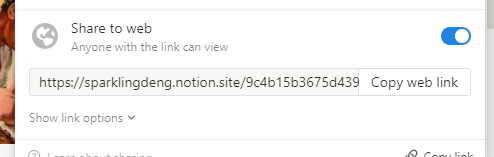
点开刚刚导入生成的page,获取databaseid,databaseid是固定位数的字母,在notion界面点击share,share to web,就可以看到自己的databaseid。
注意
这种的不是databaseid,你需要点进数据库页面,实在不会可以参考这里(https://www.likecs.com/ask-132446.html)

这种才是
在NotionAPI.py文件中,添加自己的机器人密钥(Bearer后面有空格),在这之前,需要创建自己的notion机器人。 Notion Integrations 官方创建机器人教程
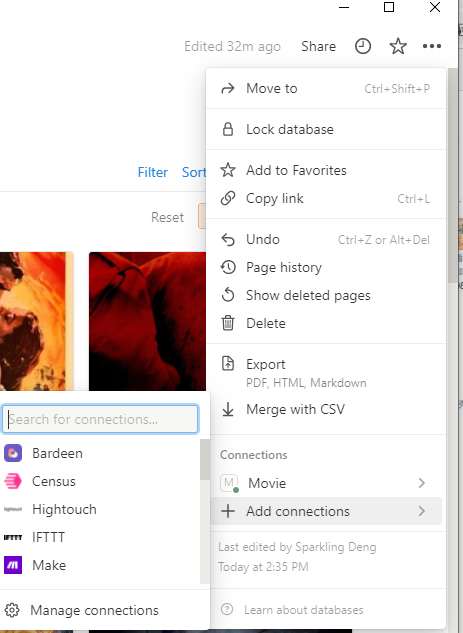
创建后需要将机器人链接至数据库页面
在Add connections就可以看到刚刚创建的机器人名
扩充导入的电影元数据
由于导入的数据中缺少导演、封面、标签等数据,所以使用update.py文件更新数据,部分需要修改的代码如下(databaseid、cookie需要更改)
databaseid = '你自己的databaseid'
headers = {'User_Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0',
'Cookie': '你自己的cookie',
'Host': 'www.douban.com',
'Referer': 'https://accounts.douban.com/'}
在NotionAPI.py中也需要修改自己的机器人密钥
import requests
# notion基本参数
headers = {
"accept": "application/json",
"Notion-Version": "2022-06-28",
"content-type": "application/json",
"authorization": "Bearer 你自己的密钥"
}
随后直接运行update.py就可以扩充封面、导演、标签等数据了。
获取最新观看的电影数据
在自己豆瓣主页的右下角可以看到自己有一个rss订阅链接,复制这个链接
在movietrack.py中需要修改下面代码
if __name__ == '__main__':
# notion相关配置
# 需要在notionAPI.py中配置notion token
databaseid = '你的databaseid'
headers = {'User_Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0',
'Cookie': '你的cookie',
'Host': 'www.douban.com',
'Referer': 'https://accounts.douban.com/'}
rss_movietracker = feedparser.parse("你的rss订阅链接",
request_headers=headers)
最后直接运行,python会爬取你最近看过的电影,并与数据库中已经存在的电影进行匹配,更新数据库中不存在的电影。