Li, X., Feng, J., Meng, Y., Han, Q., Wu, F., & Li, J. (2020). A Unified MRC Framework for Named Entity Recognition. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 5849–5859. https://doi.org/10.18653/v1/2020.acl-main.519
“The task of named entity recognition (NER) is normally divided into nested NER and flat NER depending on whether named entities are nested or not.” (Li et al., 2020, p. 5849) 命名实体识别 (NER) 的任务通常根据命名实体是否嵌套分为嵌套 NER 和平面 NER。
“Models are usually separately developed for the two tasks, since sequence labeling models are only able to assign a single label to a particular token, which is unsuitable for nested NER where a token may be assigned several labels.” (Li et al., 2020, p. 5849) 通常为这两个任务分别开发模型,因为序列标记模型只能将单个标签分配给特定的标记,这不适合嵌套的 NER,其中一个标记可能被分配多个标签。
“In this paper, we propose a unified framework that is capable of handling both flat and nested NER tasks.” (Li et al., 2020, p. 5849) 在本文中,我们提出了一个能够处理平面和嵌套 NER 任务的统一框架。
“nstead of treating the task of NER as a sequence labeling problem, we propose to formulate it as a machine reading comprehension (MRC) task.” (Li et al., 2020, p. 5849) 我们建议将其表述为机器阅读理解 (MRC) 任务,而不是将 NER 的任务视为序列标记问题。
“Additionally, since the query encodes informative prior knowledge, this strategy facilitates the process of entity extraction, leading to better performances for not only nested NER, but flat NER.” (Li et al., 2020, p. 5849) 此外,由于查询编码了信息丰富的先验知识,这种策略促进了实体提取的过程,不仅为嵌套 NER 带来了更好的性能,而且为平面 NER 带来了更好的性能。
“The task of flat NER is commonly formalized as a sequence labeling task: a sequence labeling model” (Li et al., 2020, p. 5849) flat NER 的任务通常形式化为序列标记任务:序列标记模型
“However, pipelined systems suffer from the disadvantages of error propagation, long running time and the intensiveness in developing hand-crafted features, etc.” (Li et al., 2020, p. 5849) 然而,流水线系统存在错误传播、运行时间长、开发手工特征密集等缺点。
“Instead of treating the task of NER as a sequence labeling problem, we propose to formulate it as a SQuADstyle (Rajpurkar et al., 2016, 2018) machine reading comprehension (MRC) task.” (Li et al., 2020, p. 5850) 我们建议将其表述为 SQuADstyle (Rajpurkar et al., 2016, 2018) 机器阅读理解 (MRC) 任务,而不是将 NER 的任务视为序列标记问题。
“Each entity type is characterized by a natural language query, and entities are extracted by answering these queries given the contexts.” (Li et al., 2020, p. 5850) 每个实体类型都以自然语言查询为特征,并且通过在给定上下文的情况下回答这些查询来提取实体。
“For the latter, golden NER categories are merely class indexes and lack for semantic prior information for entity categories.” (Li et al., 2020, p. 5850) 对于后者,黄金 NER 类别仅仅是类别索引,缺乏实体类别的语义先验信息。
“Traditional sequence labeling models use CRFs (Lafferty et al., 2001; Sutton et al., 2007) as a backbone for NER.” (Li et al., 2020, p. 5850) 传统的序列标记模型使用 CRF(Lafferty 等人,2001 年;Sutton 等人,2007 年)作为 NER 的主干。
“MRC models (Seo et al., 2016; Wang et al., 2016; Wang and Jiang, 2016; Xiong et al., 2016, 2017; Wang et al., 2016; Shen et al., 2017; Chen et al., 2017) extract answer spans from a passage through a given question. The task can be formalized as two multi-class classification tasks, i.e., predicting the starting and ending positions of the answer spans.” (Li et al., 2020, p. 5851) MRC 模型 (Seo et al., 2016; Wang et al., 2016; Wang and Jiang, 2016; Xiong et al., 2016, 2017; Wang et al., 2016; Shen et al., 2017; Chen et al. , 2017) 从给定问题的段落中提取答案。该任务可以形式化为两个多类分类任务,即预测答案范围的开始和结束位置。
“Over the past one or two years, there has been a trend of transforming NLP tasks to MRC question answering.” (Li et al., 2020, p. 5851) 最近一两年,有一种将NLP任务转化为MRC问答的趋势。
“Given an input sequence X = {x1, x2, …, xn}, where n denotes the length of the sequence, we need to find every entity in X, and then assign a label y ∈ Y to it, where Y is a predefined list of all possible tag types (e.g., PER, LOC, etc).” (Li et al., 2020, p. 5851) 给定一个输入序列 X = {x1, x2, …, xn},其中 n 表示序列的长度,我们需要找到 X 中的每个实体,然后为其分配一个标签 y ∈ Y,其中 Y 是所有可能的标签类型(例如 PER、LOC 等)的预定义列表。
“Firstly we need to transform the tagging-style annotated NER dataset to a set of (QUESTION, ANSWER, CONTEXT) triples.” (Li et al., 2020, p. 5851) 首先,我们需要将标记样式的带注释 NER 数据集转换为一组(问题、答案、上下文)三元组。
“For each tag type y ∈ Y , it is associated with a natural language question qy = {q1, q2, …, qm}, where m denotes the length of the generated query.” (Li et al., 2020, p. 5851) 对于每个标签类型 y ∈ Y ,它与一个自然语言问题 qy = {q1, q2, …, qm} 相关联,其中 m 表示生成的查询的长度。
“By generating a natural language question qy based on the label y, we can obtain the triple (qy, xstart,end, X), which is exactly the (QUESTION, ANSWER, CONTEXT) triple that we need.” (Li et al., 2020, p. 5851) 通过根据标签y生成一个自然语言问题qy,我们可以得到三元组(qy, xstart,end, X),这正是我们需要的(QUESTION, ANSWER, CONTEXT)三元组。
“The question generation procedure is important since queries encode prior knowledge about labels and have a significant influence on the final results.” (Li et al., 2020, p. 5851) 问题生成过程很重要,因为查询编码了有关标签的先验知识并对最终结果产生重大影响。
“n this paper, we take annotation guideline notes as references to construct queries.” (Li et al., 2020, p. 5851) 在本文中,我们将注释指南注释作为构造查询的参考。

“To be in line with BERT, the question qy and the passage X are concatenated, forming the combined string {[CLS], q1, q2, …, qm, [SEP], x1, x2, …, xn}, where [CLS] and [SEP] are special tokens.” (Li et al., 2020, p. 5852) 为了与 BERT 一致,问题 qy 和段落 X 被连接起来,形成组合字符串 {[CLS], q1, q2, …, qm, [SEP], x1, x2, …, xn} ,其中 [CLS] 和 [SEP] 是特殊标记。
“Then BERT receives the combined string and outputs a context representation matrix E ∈ Rn×d, where d is the vector dimension of the last layer of BERT and we simply drop the query representations.” (Li et al., 2020, p. 5852) 然后 BERT 接收组合字符串并输出上下文表示矩阵 E ∈ Rn×d,其中 d 是 BERT 最后一层的向量维度,我们简单地删除查询表示。
“There are two strategies for span selection in MRC: the first strategy (Seo et al., 2016; Wang et al., 2016) is to have two n-class classifiers separately predict the start index and the end index, where n denotes the length of the context.” (Li et al., 2020, p. 5852) MRC中跨度选择有两种策略:第一种策略(Seo et al., 2016; Wang et al., 2016)是让两个n类分类器分别预测起始索引和结束索引,其中n表示上下文的长度。
“Since the softmax function is put over all tokens in the context, this strategy has the disadvantage of only being able to output a single span given a query;” (Li et al., 2020, p. 5852) 由于 softmax 函数覆盖上下文中的所有标记,因此该策略的缺点是只能输出给定查询的单个跨度;
“the other strategy is to have two binary classifiers, one to predict whether each token is the start index or not, the other to predict whether each token is the end index or not.” (Li et al., 2020, p. 5852) 另一种策略是有两个二元分类器,一个预测每个标记是否为起始索引,另一个预测每个标记是否为结束索引。
“This means that multiple start indexes could be predicted from the start-index prediction model and multiple end indexes predicted from the endindex prediction model.” (Li et al., 2020, p. 5852) 这意味着可以从起始索引预测模型预测多个起始索引,并从结束索引预测模型预测多个结束索引。
“Given any start index istart ∈ ˆ Istart and end index iend ∈ ˆ Iend, a binary classification model is trained to predict the probability that they should be matched, given as follows:” (Li et al., 2020, p. 5852) 给定任何起始索引 istart ∈ Istart 和结束索引 iend ∈ ^ Iend,训练一个二元分类模型来预测它们应该被匹配的概率,给出如下:
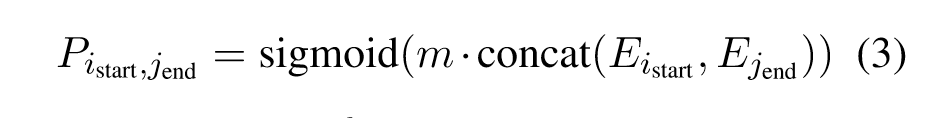
“At training time, X is paired with two label sequences Ystart and Yend of length n representing the ground-truth label of each token xi being the start index or end index of any entity.” (Li et al., 2020, p. 5852) 在训练时,X 与两个长度为 n 的标签序列 Ystart 和 Yend 配对,表示每个标记 xi 的真实标签,是任何实体的起始索引或结束索引。
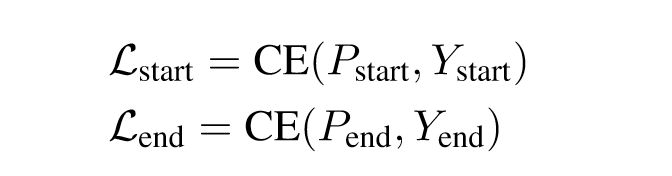
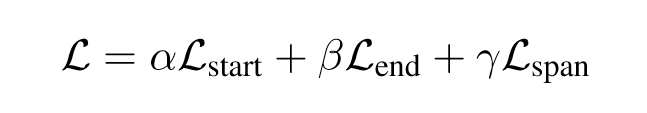
“The three losses are jointly trained in an end-to-end fashion, with parameters shared at the BERT layer. At test time, start and end indexes are first separately selected based on ˆ Istart and ˆ Iend. Then the index matching model is used to align the extracted start indexes with end indexes, leading to the final extracted answers.” (Li et al., 2020, p. 5853) 这三种损失以端到端的方式联合训练,在 BERT 层共享参数。在测试时,首先根据 istart 和 iend 分别选择开始和结束索引。然后使用索引匹配模型将提取的起始索引与结束索引对齐,从而得到最终提取的答案。
“Rule-based template filling: generates questions using templates. The query for tag ORG is “which organization is mentioned in the text”.” (Li et al., 2020, p. 5855) 基于规则的模板填充:使用模板生成问题。标签 ORG 的查询是“文本中提到了哪个组织”。
“Wikipedia: a query is constructed using its wikipedia definition.” (Li et al., 2020, p. 5855) 维基百科:查询是使用其维基百科定义构建的。
“Wikipedia underperforms Annotation Guideline Notes because definitions from Wikipedia are relatively general and may not precisely describe the categories in a way tailored to data annotations.” (Li et al., 2020, p. 5856) Wikipedia 的性能不如 Annotation Guideline Notes,因为 Wikipedia 的定义相对笼统,可能无法以适合数据注释的方式精确描述类别。