Kim, S., Razi, A., Stringhini, G., Wisniewski, P. J., & De Choudhury, M. (2021). A Human-Centered Systematic Literature Review of Cyberbullying Detection Algorithms. ACM 人机交互论文集, 5(CSCW2), 325:1-325:34. https://doi.org/10.1145/3476066
“We analyzed 56 papers based on a three-prong human-centeredness algorithm design framework – spanning theoretical, participatory, and speculative design.” (Kim 等, 2021, p. 3251) 我们根据以人为本的三管齐下算法设计框架分析了 56 篇论文——涵盖理论、参与和推测设计。
“We found that the past literature fell short of incorporating human-centeredness across multiple aspects, ranging from defining cyberbullying, establishing the ground truth in data annotation, evaluating the performance of the detection models, to speculating the usage and users of the models, including potential harms and negative consequences.” (Kim 等, 2021, p. 3251) 我们发现,过去的文献未能将以人为本的理念纳入多个方面,从定义网络欺凌、在数据注释中建立基本事实、评估检测模型的性能,到推测模型的使用和用户,包括潜在的危害和负面后果。
“However, cyberbullying detection is not merely a classification task to identify which and whose content might be abusive towards an individual or group; we posit that building machine learning models for cyberbullying detection needs to adopt a human-centered perspective.” (Kim 等, 2021, p. 3252) 然而,网络欺凌检测不仅仅是一项分类任务,用于识别哪些内容和哪些内容可能对个人或群体进行辱骂;我们假设构建用于网络欺凌检测的机器学习模型需要采用以人为本的视角。
“Recent research in Computer-Supported Cooperative Work and Social Computing (CSCW) has noted that “human-centered paradigms for computing advocate for integrating ‘personal, social, and cultural aspects’ [77] into the design of technology, and accounting for stakeholders in the creation of technological solutions” [22].” (Kim 等, 2021, p. 3252) 最近对计算机支持的协同工作和社会计算 (CSCW) 的研究指出,“以人为中心的计算范式提倡将‘个人、社会和文化方面’[77] 整合到技术设计中,并考虑利益相关者技术解决方案的创建”[22]。
“machine learning needs to stay grounded in human needs [22], models need to be built in inclusive ways that adequately represent the diverse experiences of different individuals and minimize biases [122], and that machine learning approaches ought to incorporate interpretability and transparency to not only elucidate its potential for harm [1, 15, 48, 66], but also how data-driven decisions are used in practical scenarios [22, 136].” (Kim 等, 2021, p. 3252) 机器学习需要以人类需求为基础 [22],模型需要以包容的方式构建,以充分代表不同个体的不同经历并最大限度地减少偏见 [122],并且机器学习方法应该结合可解释性和透明度,而不是仅阐明其潜在的危害 [1、15、48、66],以及如何在实际场景中使用数据驱动的决策 [22、136]。
“As Amershi et al. [8] rightly noted: “humans are more than “a source of labels” and because the process of design should not hinge entirely on the construct of “the user” [128], people’s involvement with machine learning can take many roles beyond data curation, such as in supporting algorithm selection and tuning, and identifying its points of success and failure.” (Kim 等, 2021, p. 3252) 正如 Amershi 等人。 [8] 正确地指出:“人类不仅仅是“标签的来源”,而且由于设计过程不应完全取决于“用户”[128] 的构造,人们对机器学习的参与可以发挥数据以外的许多作用策展,例如支持算法选择和调整,以及识别其成功点和失败点。
“we argue that building cyberbullying detection models necessitates a deep understanding of a) how cyberbullying can be operationalized based on its theoretical and psychological underpinnings; b) what could be effective ways to represent the varied subjective experiences of cyberbullying within the models given the subjective nature of bullying [135] and how model evaluation needs to look beyond quantifiable metrics to incorporate human feedback, mental models, and social interpretations [13]; and c) who could be the potential stakeholders that could potentially harness the outcomes of such models, and how.” (Kim 等, 2021, p. 3253) 我们认为,建立网络欺凌检测模型需要深入了解 a) 如何根据其理论和心理基础实施网络欺凌; b) 鉴于欺凌的主观性质 [135],以及模型评估如何需要超越可量化的指标以纳入人类反馈、心智模型和社会解释 [13],在模型中表示网络欺凌的各种主观体验的有效方法是什么? ]; c) 谁可以成为潜在的利益相关者,可以潜在地利用这些模型的结果,以及如何。
“From a theoretical standpoint, we first focus on existing algorithms’ alignment with theories of cyberbullying especially in operationalizing acts and incidents of cyberbullying.” (Kim 等, 2021, p. 3253) 从理论的角度来看,我们首先关注现有算法与网络欺凌理论的一致性,尤其是在实施网络欺凌行为和事件方面。
“Then from a participatory perspective, we describe if and how existing algorithms have involved the human (or broadly various stakeholders) in data annotation and model evaluation.” (Kim 等, 2021, p. 3253) 然后从参与的角度,我们描述了现有算法是否以及如何让人类(或广泛的各种利益相关者)参与数据注释和模型评估。
“Finally, from the perspective of speculative algorithm design, we shine a light on how researchers have envisioned the usage of existing detection algorithms in realworld scenarios, by who, including consideration of harms and negative consequences.” (Kim 等, 2021, p. 3253) 最后,从推测性算法设计的角度,我们阐明了研究人员如何设想由谁在现实场景中使用现有检测算法,包括对危害和负面后果的考虑。
“Other scholars noted that high quality datasets are lacking in this area [105, 135], primarily because of the lack of suitable ground truth data on cyberbullying and therefore a need to rely on manual annotation, which is time-, cost-, and effort-intensive [4, 91].” (Kim 等, 2021, p. 3253) 其他学者指出,该领域缺乏高质量的数据集 [105, 135],主要是因为缺乏关于网络欺凌的合适的基本事实数据,因此需要依赖人工注释,这是时间、成本和精力- 密集 [4, 91]。
“In fact, Emmery et al. [53] critiqued in their review that there is a reproducibility as well as an evaluation crisis in this research area – most prior work has used small, heterogeneous datasets, without a thorough evaluation of applicability across domains, platforms, and populations.” (Kim 等, 2021, p. 3254) 事实上,Emmery 等人。 [53] 在他们的评论中批评该研究领域存在可重复性和评估危机——大多数先前的工作使用了小型、异构的数据集,没有对跨领域、平台和人群的适用性进行全面评估。
“However, many researchers, based on their respective reviews, suggested machine learning methodological improvements, although none considered how these improvements need to stem from real-world scenarios where the algorithms could benefit or potentially harm intended individuals.” (Kim 等, 2021, p. 3254) 然而,许多研究人员根据他们各自的评论,提出了机器学习方法的改进建议,尽管没有人考虑到这些改进需要如何源于算法可能有益于或可能损害目标个体的现实场景。
“Kovačević argued that more work needs to be done in terms of taking into account user and contextual aspects of the cyberbullying incidents.” (Kim 等, 2021, p. 3254) Kovačević 认为,在考虑网络欺凌事件的用户和上下文方面需要做更多的工作。
“Accordingly, Al-Garadi et al. [4] recommended that cyberbullying detection use better feature engineering to capture the rich context of the incidents rather than overly stressing feature selection and machine learning methodological improvements, while Tokunaga [154] suggested careful consideration of user demographic attributes in operationalizing the concept of cyberbullying.” (Kim 等, 2021, p. 3254) 因此,Al-Garadi 等人。 [4] 建议网络欺凌检测使用更好的特征工程来捕获事件的丰富背景,而不是过分强调特征选择和机器学习方法的改进,而 Tokunaga [154] 建议在实施网络欺凌概念时仔细考虑用户人口统计属性。
“However, none of these papers suggested involving the stakeholders of cyberbullying incidents victims, bystanders, or bullies in capturing this valuable context.” (Kim 等, 2021, p. 3254) 然而,这些论文都没有建议让网络欺凌事件的受害者、旁观者或欺凌者的利益相关者参与捕捉这一有价值的背景。
“Suggested evaluation metrics included the F-1 score or the area under receiver-operating characteristic (ROC) curve (AUC), but the existing reviews did not discuss the significance and value of human involvement toward unpacking misclassifications.” (Kim 等, 2021, p. 3254) 建议的评估指标包括 F-1 分数或接受者操作特征 (ROC) 曲线 (AUC) 下的面积,但现有的评论没有讨论人类参与对拆包错误分类的意义和价值。
“Machine learning is increasingly adopted to address societal problems via data-driven decisionmaking [22], in Fiebrink and Gillies [56]’s words, however, it “often centers on impersonal algorithmic concerns, removed from human considerations such as usability, intuition, effort, and human learning; it is also too often detached from the variety and deep complexity of human contexts in which machine learning may be ultimately applied.”” (Kim 等, 2021, p. 3255) 用 Fiebrink 和 Gillies [56] 的话来说,机器学习越来越多地被用于通过数据驱动的决策制定 [22] 来解决社会问题,然而,它“通常以非个人的算法问题为中心,从可用性、直觉、努力和人类学习;它也常常脱离机器学习最终可能应用的人类环境的多样性和深度复杂性。”
“First, humancenteredness, in the form of behavioral and social science theories, can provide both prescriptive (helping identify which features might be valuable and why) as well as descriptive knowledge (what do the outcomes of the models mean) in the design of machine learning models [13].” (Kim 等, 2021, p. 3255) 首先,以行为和社会科学理论的形式,以人为本可以在机器学习的设计中提供说明性(帮助确定哪些特征可能有价值以及为什么)以及描述性知识(模型的结果意味着什么)模型 [13]。
“Next, Fiebrink and Gillies [56] advocated that examining machine learning from a humancentered perspective includes explicitly recognizing both human work and the human contexts in which machine learning is used.” (Kim 等, 2021, p. 3255) 接下来,Fiebrink 和 Gillies [56] 提倡从以人为本的角度检查机器学习,包括明确识别人类工作和使用机器学习的人类环境。
“Complementarily, when machine learning models are evaluated by human experts, such as psychologists and mental health professionals in the case of cyberbullying detection, they can help to bridge disconnects between the functionality of the models and their social uses [13].” (Kim 等, 2021, p. 3255) 作为补充,当机器学习模型由人类专家评估时,例如在网络欺凌检测中的心理学家和心理健康专家,他们可以帮助弥合模型功能与其社会用途之间的脱节 [13]。
“Third, a human-centered approach to machine learning demands making machine learning more usable and effective for a broader range of stakeholders, including those who would use the outcomes of the machine learning system and those who are affected by them [56].” (Kim 等, 2021, p. 3255) 第三,以人为本的机器学习方法要求机器学习对更广泛的利益相关者更有用和更有效,包括那些将使用机器学习系统结果的人和那些受其影响的人 [56]。
“Baumer [13] conceptualized human-centered algorithm design to engender three key dimensions or strategies – theoretical, participatory, and speculative design.” (Kim 等, 2021, p. 3256) Baumer [13] 将以人为本的算法设计概念化,以产生三个关键维度或策略——理论、参与和推测设计。
“The theories that are utilized for the design can, therefore, be prescriptive by giving a guideline to why certain features should be selected over others for the training of a machine learning model.” (Kim 等, 2021, p. 3256) 因此,用于设计的理论可以通过指导为什么应该选择某些特征而不是其他特征来训练机器学习模型来进行说明。
“Therefore, it essentially provides a bridge between people who might be interacting with the development of the system and the ones that designed it. By doing so, in the context of machine learning, this enables an exchange between the possibly varied end users of the algorithm and the designers of the algorithm.” (Kim 等, 2021, p. 3256) 因此,它本质上是在可能与系统开发交互的人员和系统设计人员之间架起了一座桥梁。通过这样做,在机器学习的背景下,可以在算法的可能不同的最终用户和算法的设计者之间进行交流。
“It emphasizes that it is important to not just produce artifacts that can be useful, but also be provocative in imagining possible futures with these artifacts. Since it involves going beyond the current problem context to such possible futures, this freedom can facilitate thinking through the ramifications of the algorithm’s use in different situations and the (positive or negative) impact on different groups of users or stakeholders.” (Kim 等, 2021, p. 3256) 它强调重要的是,不仅要生产有用的人工制品,而且要积极想象这些人工制品可能的未来。由于它涉及超越当前问题上下文到可能的未来,这种自由可以促进思考算法在不同情况下使用的后果以及对不同用户或利益相关者群体的(正面或负面)影响。
“we coded each document (paper) for relevancy to our scope based on close reads of the abstract, methodology, and discussion sections.” (Kim 等, 2021, p. 3257) 我们根据对摘要、方法论和讨论部分的仔细阅读,对每篇文档(论文)进行了编码,以便与我们的范围相关。
“we then adopted a snowball sampling approach, and went through the reference list to conduct a second pass of search.” (Kim 等, 2021, p. 3257) 然后我们采用滚雪球抽样的方法,通过参考列表进行第二次搜索。
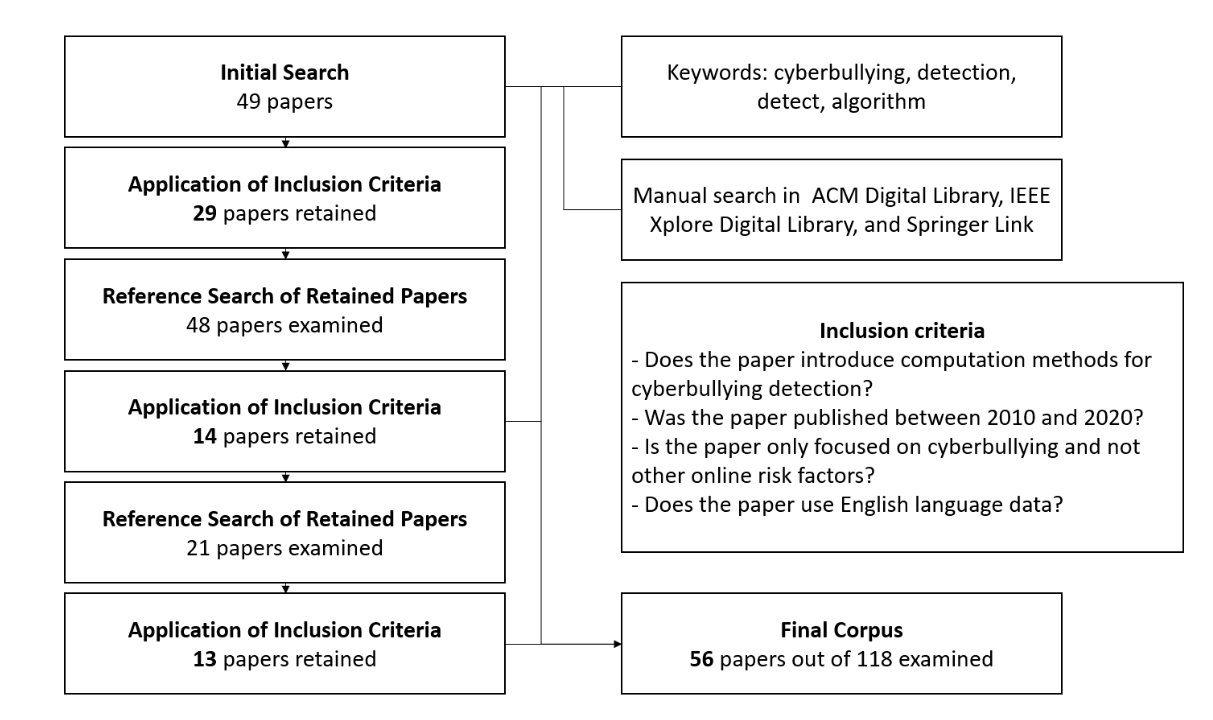

“We generated questions for each dimension in a deductive way and at the same time used an inductive approach for verification of the validity of the questions. The induction process first selected a random sample of five papers from the corpus to draft a question that would address a shared topic or concept in the subset. Once the question was drafted, another random sample of five papers was examined to see if the established questions were indeed closely related to the papers. Then in the deductive step, we placed the question to the most relevant dimension using their respective definitions (theoretical, participatory, speculative). If no suitable match was found, the inductive and deductive steps were reiterated to reach an alignment.” (Kim 等, 2021, p. 3259) 我们以演绎的方式为每个维度生成问题,同时使用归纳的方法来验证问题的有效性。归纳过程首先从语料库中随机抽取五篇论文来起草一个问题,以解决子集中的共同主题或概念。一旦问题被起草,另一个随机抽样的五篇论文将被检查以查看确定的问题是否确实与论文密切相关。然后在演绎步骤中,我们使用它们各自的定义(理论的、参与的、推测的)将问题置于最相关的维度。如果没有找到合适的匹配项,则重复归纳和演绎步骤以达到对齐。
“we note that questions related to incorporating theoretical concepts, models, or relationships within the design of the (cyberbullying detection) algorithm were put under the theoretical design category.” (Kim 等, 2021, p. 3259) 我们注意到,与将理论概念、模型或关系纳入(网络欺凌检测)算法设计相关的问题被归入理论设计类别。
“The participatory design category represents direct involvement of humans in the algorithm design process, the interpretations of the humans in the loop, as well as the end users of the algorithms.” (Kim 等, 2021, p. 3259) 参与式设计类别代表人类直接参与算法设计过程、循环中人类的解释以及算法的最终用户。
“Similarly, interpreting how the performance of these models were evaluated provides insight into how humans interpreted or were (potentially) affected by their success and failure modes.” (Kim 等, 2021, p. 3260) 同样,解释如何评估这些模型的性能可以深入了解人类如何解释或(潜在地)受其成功和失败模式的影响。
“Lastly, questions related to the envisions and projections that the researchers had about the future use of cyberbullying detection algorithms were put under the speculative design.” (Kim 等, 2021, p. 3260) 最后,与研究人员对未来使用网络欺凌检测算法的设想和预测相关的问题被置于推测设计之下。
“Speculative design also allows us to shine a light on the various stakeholders of the algorithms, when deployed in real-world scenarios, and how those different deployments may impact the stakeholders in varied ways, from the perspective of the benefits-harms calculus.” (Kim 等, 2021, p. 3260) 推测性设计还使我们能够从利益-损害演算的角度阐明算法在实际场景中部署时的各种利益相关者,以及这些不同的部署如何以不同的方式影响利益相关者。
“The first dimension examines how the various theories from behavioral and social sciences were incorporated in the design of the cyberbullying detection algorithms.” (Kim 等, 2021, p. 3260) 第一个维度检查如何将行为和社会科学的各种理论纳入网络欺凌检测算法的设计。
“Dan Olweus [116] introduced the traits of bullying that differentiates it from other types of aggression: repetitive occurrence and clear imbalance between the victim and the aggressor.” (Kim 等, 2021, p. 3260) Dan Olweus [116] 介绍了欺凌与其他类型的攻击不同的特征:重复发生和受害者与攻击者之间明显的不平衡。
“Dadvar and De Jong’s paper adopted the definition of cyberbullying “as an aggressive, intentional act carried out by a group or individual, using electronic forms of contact (e.g. email and chat rooms) repeatedly or over time against a victim who cannot easily defend herself” (p.121, [34]) from a study on bullying and peer victimization in schools [55].” (Kim 等, 2021, p. 3261) Dadvar 和 De Jong 的论文采用了网络欺凌的定义“作为一个团体或个人实施的一种侵略性的、故意的行为,反复或长期使用电子联系方式(例如电子邮件和聊天室)来对抗无法轻易保护自己的受害者” (p.121, [34]) 来自一项关于学校欺凌和同伴受害的研究 [55]。
“However, there did not seem to be a set or benchmarked dataset that was universally used to drive which platforms were selected as data sources and why; all of the datasets were either from social media platforms (e.g. Twitter, YouTube, Slashdot) or a designated dataset for cybercrimes such as Perverted-Justice [121].” (Kim 等, 2021, p. 3261) 然而,似乎没有一套或基准数据集被普遍用于驱动选择哪些平台作为数据源以及原因;所有数据集要么来自社交媒体平台(例如 Twitter、YouTube、Slashdot),要么来自网络犯罪的指定数据集,例如 Perverted-Justice [121]。
“Unlike studies like that of Wijesiriwardene et al. [161], there was little mention of focusing on contextual data when creating the datasets; contextual information such as user activities [38] was later extracted as features.” (Kim 等, 2021, p. 3261) 与 Wijesiriwardene 等人的研究不同。 [161],几乎没有提到在创建数据集时关注上下文数据;用户活动 [38] 等上下文信息后来被提取为特征。
“There were also no particular theoretical frameworks from the behavioral or social science literature involved in curating the dataset collected from various platforms.” (Kim 等, 2021, p. 3261) 在管理从各种平台收集的数据集时,也没有来自行为或社会科学文献的特定理论框架。
“The majority of the studies (71.4%) used the specified platform’s API to scrap and collect their own data, thus focusing on primarily public data, essentially indicating an approach to obtain a convenience sample due to ease of access, rather than a sample that is theoretically-justified.” (Kim 等, 2021, p. 3261) 大多数研究 (71.4%) 使用指定平台的 API 来废弃和收集他们自己的数据,因此主要关注公共数据,本质上表明一种获取方便样本的方法,因为易于访问,而不是样本是理论上是合理的。
“The selection of these features was largely data-driven and convenience-driven, rather than theoretically-driven” (Kim 等, 2021, p. 3261) 这些功能的选择主要是数据驱动和便利性驱动,而不是理论驱动
“That said, the keywords and vocabulary that represented cyberbullying varied; these were often defined by the researchers as a form of domain-knowledge, and therefore a proxy to cyberbullying specific theories.” (Kim 等, 2021, p. 3262) 也就是说,代表网络欺凌的关键词和词汇各不相同;这些通常被研究人员定义为领域知识的一种形式,因此是网络欺凌特定理论的代表。
“While there was a commonly shared characteristic between these studies that they extracted information about the specific dataset entity to further support textual information, there was wide variety in the metadata that the researchers chose, the theoretical or conceptual motivation behind whose selection was rarely clearly articulated in the respective papers.” (Kim 等, 2021, p. 3262) 虽然这些研究之间有一个共同的特征,即它们提取了有关特定数据集实体的信息以进一步支持文本信息,但研究人员选择的元数据种类繁多,选择背后的理论或概念动机很少清楚地阐明各自的论文。
“Summarily, there is a large focus on the vocabulary that is used in the posts when it comes to feature selection. Although non-textual features such as user profile data and network features are used, there is a heavy reliance on a bottom-up approach using the content of the posts when it comes to cyberbullying detection, rather than harnessing or unpacking the context of the specific cyberbullying incident.” (Kim 等, 2021, p. 3262) 总之,在特征选择方面,人们非常关注帖子中使用的词汇。尽管使用了用户配置文件数据和网络特征等非文本特征,但在网络欺凌检测方面,严重依赖使用帖子内容的自下而上的方法,而不是利用或解包特定的上下文网络欺凌事件。
“This is an important point to note, given that it is commonly accepted that contextual and temporally varying data is important for cyberbullying detection, as the content alone does not provide enough information for the classifiers [135].” (Kim 等, 2021, p. 3262) 这是一个需要注意的重要点,因为人们普遍认为上下文和时间变化的数据对于网络欺凌检测很重要,因为内容本身并不能为分类器提供足够的信息 [135]。
“Still, despite the limited use of theory, we do acknowledge that choices of the features in existing research may have been motivated by subjective human observations, which can be valuable to eventually develop or refine cyberbullying theories. In addition, post-hoc analyses of the features that were useful and influential could inspire future work to discover meaningful connections between cyberbullying theories and the features, explaining not only what features were important but also why they were crucial.” (Kim 等, 2021, p. 3262) 尽管如此,尽管理论的使用有限,但我们确实承认,现有研究中对特征的选择可能是由主观的人类观察所激发的,这对于最终发展或完善网络欺凌理论可能很有价值。此外,对有用和有影响力的特征进行事后分析可以激发未来的工作,以发现网络欺凌理论与特征之间有意义的联系,不仅可以解释哪些特征重要,还可以解释为什么它们至关重要。
“Scholars have argued that purely optimizing for model performance in machine learning may result in ill-posed problems [7] because such algorithms simply “identify correlations among big data” [7] without fundamentally assessing relationships and inter-dependence between factors, and the mechanisms with which specific attributes may relate to outcomes of interest – insights that are often provided by social science theories.” (Kim 等, 2021, p. 3263) 学者们认为,纯粹优化机器学习中的模型性能可能会导致不适定问题 [7],因为此类算法只是“识别大数据之间的相关性”[7],而没有从根本上评估因素之间的关系和相互依赖性,以及机制哪些特定属性可能与感兴趣的结果相关——社会科学理论通常提供的见解。
“In addition, model selections are heavily influenced by the problem statement, as they shape the characteristic of the task and the corresponding set of suitable models.” (Kim 等, 2021, p. 3263) 此外,模型选择在很大程度上受问题陈述的影响,因为它们塑造了任务的特征和相应的一组合适的模型。
“The insufficient amount of publicly available annotated datasets has always bestowed a challenge to the researchers in the cyberbullying detection field, as they have to establish a way to collect and reasonably label their datasets.” (Kim 等, 2021, p. 3263) 公开可用的注释数据集数量不足一直给网络欺凌检测领域的研究人员带来挑战,因为他们必须建立一种方法来收集和合理标记他们的数据集。
“Given the noisiness of crowd-gathered ground labels [30], most of these papers adopted best practices suggested in crowdsourcing research to assess crowdworkers’ task quality and competence [100], but rarely followed them up with additional phases of human verification, triangulation, or a systematic reconciliation of discrepancies when the crowdworkers disagreed.” (Kim 等, 2021, p. 3264) 鉴于人群聚集的地面标签 [30] 的噪音,这些论文中的大多数采用了众包研究中建议的最佳实践来评估众包工作者的任务质量和能力 [100],但很少跟进人工验证、三角测量、或者当众包工作者不同意时系统地调和差异。
“Still, there remains the question of how researchers can control for the different perceptions of cyberbullying of different people, for instance, the authors of the posts being labeled, the targeted victims, the bystander social media users, community members/moderators, or the platform managers, given the subjectivity of the experience [49] and the diversity of humans who are involved in or impacted by cyberbullying [96].” (Kim 等, 2021, p. 3264) 尽管如此,仍然存在研究人员如何控制不同人对网络欺凌的不同看法的问题,例如,被标记帖子的作者、目标受害者、旁观者社交媒体用户、社区成员/版主或平台考虑到经验的主观性 [49] 以及参与网络欺凌或受其影响的人的多样性 [96]。
“However, the absence of adequate and a principled unpacking of these varied perspectives of different stakeholders and the lack of involvement of people with lived experience of cyberbullying indicate a clear shortcoming, since it would only provide one subset of the possible perspectives.” (Kim 等, 2021, p. 3264) 然而,缺乏对不同利益相关者的这些不同观点进行充分和有原则的分析,以及缺乏具有网络欺凌生活经验的人的参与表明了一个明显的缺点,因为它只能提供可能观点的一个子集。
“While some papers did report multiple performance metrics (91.1%), many relied almost exclusively on one or two metrics such as precision and recall (58.9% and 58.9% papers respectively), without a clear or a rationale, from a human interpretability or understand perspective, why some metrics were prioritized or why certain others were not considered. We rarely found the use of popular metrics from other domains, such as sensitivity, specificity, and positive and negative predictive value.” (Kim 等, 2021, p. 3265) 虽然一些论文确实报告了多个性能指标 (91.1%),但许多论文几乎完全依赖于一个或两个指标,例如精确率和召回率(分别为 58.9% 和 58.9% 的论文),没有明确的或合理的理由,来自人类的可解释性或理解观点,为什么某些指标被优先考虑或为什么某些其他指标没有被考虑。我们很少发现使用其他领域的流行指标,例如敏感性、特异性以及阳性和阴性预测值。
“Importantly, only 3 papers used some of human-evaluation of the models, in fact, just 2 involved experts to assess how well the proposed techniques did in detecting cyberbullying in social media content. But unfortunately, even within these two papers, the background or qualifications of the experts, including how their expertise was defined or assessed were not mentioned [106, 110].” (Kim 等, 2021, p. 3265) 重要的是,只有 3 篇论文使用了模型的一些人工评估,事实上,只有 2 篇涉及专家来评估所提出的技术在检测社交媒体内容中的网络欺凌方面的表现。但不幸的是,即使在这两篇论文中,也没有提及专家的背景或资格,包括如何定义或评估他们的专业知识 [106, 110]。
“In fact, even for these papers that do provide an error analysis, a human-centered approach to identify potential reasons behind why the algorithm may have misclassified a particular post was absent.” (Kim 等, 2021, p. 3265) 事实上,即使对于这些确实提供了错误分析的论文,也没有以人为本的方法来识别算法可能错误分类特定帖子的潜在原因。
“Summarily, the majority of model evaluation approaches lacked detailed interpretation of the performance metrics based on direct human feedback, whether experts or other stakeholders involved in cyberbullying – information that can provide a deeper look at the misclassifications.” (Kim 等, 2021, p. 3265) 总之,大多数模型评估方法都缺乏基于直接人类反馈对性能指标的详细解释,无论是专家还是参与网络欺凌的其他利益相关者——这些信息可以更深入地了解错误分类。
“The third and final dimension of our human-centered review focuses on speculative design considered in this existing body of research.” (Kim 等, 2021, p. 3265) 我们以人为本的审查的第三个也是最后一个维度侧重于现有研究机构中考虑的推测设计。
“Central to speculative design is also the emphasis to look beyond technical feasibility, and bring to the fore the assumptions and values embedded in technology, espousing a value fiction approach [52]. While the vast majority of the papers we reviewed adopted a purely technical stance in framing their problem statements and articulating their goals, some did seek to incorporate interdisciplinary knowledge by drawing from fields like psychology [5, 27, 34].” (Kim 等, 2021, p. 3266) 推测性设计的核心还在于强调超越技术可行性,突出技术中嵌入的假设和价值,支持价值虚构方法 [52]。虽然我们审查的绝大多数论文在构建问题陈述和阐明目标时都采用纯技术立场,但有些论文确实试图通过借鉴心理学等领域的知识来整合跨学科知识 [5、27、34]。
“The speculations ranged from hypothesizing that governments and governing bodies take action before users become victims of cyberbullying [148, 149], providing support for the victim while tracking the perpetrators [34], giving feedback to stakeholders with authority (parents, law enforcement, etc.) to initiate manual validation of suspected messages [142], inferring trigger comments that cause bullying incidents [171], to offering a way to detect “real” users or those behind fake profiles involved in cyberbullying [59]” (Kim 等, 2021, p. 3266) 猜测范围从假设政府和管理机构在用户成为网络欺凌的受害者之前采取行动 [148, 149],在追踪肇事者的同时为受害者提供支持 [34],向具有权威的利益相关者(父母、执法部门等)提供反馈.) 启动对可疑消息的手动验证 [142],推断导致欺凌事件的触发评论 [171],提供一种方法来检测“真实”用户或参与网络欺凌的虚假个人资料背后的人 [59]
“Therefore, they argued that such domain specificity of the classifiers would limit their application to only those social media platforms that have the same types of features and affordances, limiting generalizable future use.” (Kim 等, 2021, p. 3267) 因此,他们认为分类器的这种领域特异性会将它们的应用限制在那些具有相同类型的功能和功能的社交媒体平台上,从而限制了未来的普遍使用。
“the heavy reliance on external annotators for curating training data raises critical questions about how to control for subjectivity of the annotators – a concern noted in previous literature reviews as well [132]. Beyond a notable technical challenge, our review found a small handful of papers speculating that real-world use might be hampered due to the lack of a nuanced approach in the annotation scheme, because the annotators’ perspectives simply may not generalize [23, 33, 46, 106, 144, 155].” (Kim 等, 2021, p. 3267) 严重依赖外部注释者来管理训练数据引发了关于如何控制注释者主观性的关键问题——这一问题在之前的文献评论中也有所提及 [132]。除了一个显着的技术挑战之外,我们的评论还发现了一小部分论文推测,由于注释方案中缺乏细致入微的方法,现实世界的使用可能会受到阻碍,因为注释者的观点可能根本无法概括 [23, 33, 46、106、144、155]。
“Tomkins et al.’s study further mentioned a complementary intrinsic challenge with using externally annotations because they are not only subjective but also prone to errors due to a lack of awareness of the situation, even with high inter-rater agreement [155].” (Kim 等, 2021, p. 3267) Tomkins 等人的研究进一步提到了使用外部注释的补充性内在挑战,因为它们不仅是主观的,而且由于缺乏对情况的认识而容易出错,即使评估者之间的一致性很高 [155]。
“Notably, Nahar et al.’s study pointed out that false positives and false negatives within cyberbullying detection can have differential impact and interpretation in practical scenarios, and suggested that systems should implement a carefully weighted approach so that while cyberbullying-like posts are not overlooked” (Kim 等, 2021, p. 3267) 值得注意的是,Nahar 等人的研究指出,网络欺凌检测中的误报和漏报在实际场景中可能会产生不同的影响和解释,并建议系统应实施谨慎的加权方法,以便在不忽视类似网络欺凌的帖子的同时
“any paper discuss any potential negative consequences that could arise from implementing the models in social media platforms.” (Kim 等, 2021, p. 3268) 任何论文都讨论了在社交媒体平台上实施模型可能产生的任何潜在负面后果。
“Despite a core focus on optimizing for model performance of the detection models, the reviewed papers identified a wide range of such stakeholders who could potentially use the outcomes of the detection models.” (Kim 等, 2021, p. 3268) 尽管核心重点是优化检测模型的模型性能,但审查的论文确定了广泛的此类利益相关者,他们可能会使用检测模型的结果。
“After all, a platform has little meaning without its users, however, the reviewed papers rarely discussed the impacts these automated services will have on the users beyond the potential business or commercial benefits of timeliness and scalability in detecting cyberbullying.” (Kim 等, 2021, p. 3268) 毕竟,没有用户的平台就没有什么意义,然而,除了检测网络欺凌的及时性和可扩展性的潜在业务或商业利益之外,被审查的论文很少讨论这些自动化服务对用户的影响。
“But the algorithmic transformation of theoretical concepts, as is the case for cyberbullying complicates opportunities for theoretical hypothesis testing [13], because the goal of most machine learning models is often to optimize for prediction, instead of generating theoretically-grounded explanations of human behaviors or social phenomena [72]” (Kim 等, 2021, p. 3269) 但是理论概念的算法转换,就像网络欺凌的情况一样,使理论假设检验的机会变得复杂 [13],因为大多数机器学习模型的目标通常是优化预测,而不是对人类行为或行为产生基于理论的解释。社会现象 [72]
“To address these gaps, first, in order to account for differences in transferring definition of bullying to specific and unique online contexts from definitions proposed for the offline world, researchers in future work need to identify and understand the affordances of social platforms such as technological affordances as well their social affordances [61, 154].” (Kim 等, 2021, p. 3269) 为了解决这些差距,首先,为了解释将欺凌定义从为线下世界提出的定义转移到特定和独特的在线环境的差异,研究人员在未来的工作中需要识别和理解社交平台的可供性,例如技术可供性以及他们的社会负担 [61, 154]。
“Theories in the behavioral and social sciences can also help the researchers better define different cyberbullying types and its characteristics” (Kim 等, 2021, p. 3269) 行为和社会科学的理论也可以帮助研究人员更好地定义不同的网络欺凌类型及其特征
“Basically, since the availability of features and usefulness of features are subject to the specific traits of the dataset domain, due to epistemological issues around what social media-derived signals really mean when taken out of context [18], and owing to the varied perceptions and nature of cyberbullying across cultural contexts [11], there is a need to establish a set of theoretically-grounded features that can be benchmarked across datasets, cyberbullying types and definitions.” (Kim 等, 2021, p. 3270) 基本上,由于特征的可用性和特征的有用性取决于数据集域的特定特征,由于围绕社交媒体衍生信号在脱离上下文时真正意味着什么的认识论问题 [18],以及由于不同的看法和跨文化背景下网络欺凌的性质 [11],有必要建立一套基于理论的特征,这些特征可以跨数据集、网络欺凌类型和定义进行基准测试。
“None of the papers we reviewed included the elements of subjectivity and perspective differences in the way the data was curated or the machine learning approach developed. Therefore, how can we measure one’s intention to hurt someone that can be operationalized into a computational feature in a machine learning model?” (Kim 等, 2021, p. 3270) 我们审查的所有论文均未包含数据整理方式或机器学习方法开发方面的主观性和视角差异因素。因此,我们如何衡量一个人伤害某人的意图,这种意图可以在机器学习模型中转化为计算特征?
“Complementarily, in studying bullying, Menesini et al. [94] found that among adolescents across six European countries, young teens had a slightly different perception of power imbalance from the researchers” (Kim 等, 2021, p. 3270) 作为补充,在研究欺凌行为时,Menesini 等人。 [94] 发现,在六个欧洲国家的青少年中,青少年对权力失衡的看法与研究人员略有不同
“Using the traditional definition of bullying and adding the medium of such actions as the definition of cyberbullying, as we observed in the reviewed research, while at a glance seems valid, needs to further take into consideration that a different channel of communication also changes the dynamic of how one bullies another.” (Kim 等, 2021, p. 3271) 正如我们在审查的研究中观察到的那样,使用欺凌的传统定义并添加此类行为的媒介作为网络欺凌的定义,虽然乍一看似乎是正确的,但需要进一步考虑到不同的沟通渠道也会改变动态一个人如何欺负另一个人。
“That said, direct comparison between any two studies, even with a knowledge of their respective limitations may be challenging, given significant demographic differences in terms of who uses which platform, and structural idiosyncrasies stemming from different platforms’ distinct characteristics [133].” (Kim 等, 2021, p. 3271) 也就是说,任何两项研究之间的直接比较,即使知道它们各自的局限性也可能具有挑战性,因为在谁使用哪个平台方面存在显着的人口差异,以及不同平台的不同特征所产生的结构特质 [133]。
“Instead, we found a singular focus on building the most accurate and well-performing cyberbullying detection model in a way that often meant leaving out the actual and direct participants of the incidents such as the bully and the victim, in the machine learning pipeline,” (Kim 等, 2021, p. 3271) 相反,我们发现专注于构建最准确和性能最佳的网络欺凌检测模型的方式通常意味着在机器学习管道中忽略事件的实际和直接参与者,例如欺凌者和受害者,
“There are cultural differences related to perceptions of harassment and aggression among victims as well as bystanders [88]: traditional bullying can take many forms and the prevalence and significance of the behaviors may vary from one cultural setting to another [104].” (Kim 等, 2021, p. 3272) 受害者和旁观者对骚扰和攻击的看法存在文化差异 [88]:传统欺凌可以采取多种形式,并且行为的普遍性和重要性可能因文化背景而异 [104]。
“The body of research we reviewed did not explicitly account for cultural background in either annotation of data or evaluation even while involving humans – whether external annotators or experts. Cultural gaps were overlooked even when repurposing an existing corpus” (Kim 等, 2021, p. 3272) 我们审查的研究主体没有明确说明数据注释或评估中的文化背景,即使涉及人类——无论是外部注释者还是专家。即使在重新利用现有语料库时也忽略了文化差距
“A participatory approach that directly connects with the victims of cyberbullying incidents can help to build a ground truth dataset that justly and accurately reflects people’s lived experiences [79], rather than that interpreted by third parties removed from the particular situations.” (Kim 等, 2021, p. 3272) 与网络欺凌事件的受害者直接联系的参与式方法可以帮助建立一个真实数据集,该数据集公正准确地反映了人们的生活经历 [79],而不是由脱离特定情况的第三方解释的数据集。
“When victims and participating actors in cyberbullying are not engaged in ground truth curation, not only does it preclude the inclusion of private conversations in dataset – a consideration important for generalizability – but also misses the context and implicit information that these individuals may provide related to their interpretations of cyberbullying in public and private conversations.” (Kim 等, 2021, p. 3272) 当网络欺凌的受害者和参与者不参与地面实况管理时,它不仅排除了将私人对话包含在数据集中的可能性——这是对普遍性很重要的考虑因素——而且还错过了这些人可能提供的与他们的行为相关的上下文和隐含信息在公共和私人谈话中对网络欺凌的解释。
“Critiques of using machine learning for real-world problems [160] acknowledge that performance metrics are an important and necessary aspect of model evaluation because of their ability to provide precise, numerical quantification of performance that is intuitively understandable without needing elaborate or deep understanding of the dataset or the problem domain. They are, however, far from being sufficient – it would be an overstatement to conclude that a highly accurate classifier implies an algorithm that always performs well under any set of circumstances.” (Kim 等, 2021, p. 3273) 对将机器学习用于现实世界问题的批评 [160] 承认性能指标是模型评估的一个重要且必要的方面,因为它们能够提供精确的、直观可理解的性能数值量化,而无需对模型进行详细或深入的理解数据集或问题域。然而,它们还远远不够——得出高度准确的分类器意味着一种算法在任何情况下都表现良好的结论是夸张的。
“For instance, although many of the approaches in the papers we reviewed performed well in terms of quantitative performance metrics, their performance from the perspective of their real world users should be evaluated as well.” (Kim 等, 2021, p. 3273) 例如,尽管我们审查的论文中的许多方法在定量性能指标方面表现良好,但也应从真实世界用户的角度评估它们的性能。
“Next, participatory approaches involving humans could also be used in future work to improve the quality of detection by checking for edge-cases, adding new categories, and so on. Finally, while conducting such evaluations, it will be important to have potential users evaluate the system than researchers, as the latter group might be biased toward the technology that they are building [138].” (Kim 等, 2021, p. 3273) 接下来,在未来的工作中也可以使用涉及人类的参与式方法,通过检查边缘情况、添加新类别等来提高检测质量。最后,在进行此类评估时,重要的是让潜在用户比研究人员评估系统,因为后者可能会偏向于他们正在构建的技术 [138]。
“although we did note some diversity of research goals focusing on timeliness, scalability, or multimodality within the detection algorithms, we found them to rarely shine a light on how the models could translate to real-life scenarios, involving diverse stakeholders, and the impacts – positive or negative – the models could have on them.” (Kim 等, 2021, p. 3273) 尽管我们确实注意到了一些侧重于检测算法中的及时性、可扩展性或多模态的研究目标的多样性,但我们发现它们很少阐明模型如何转化为现实生活场景,涉及不同的利益相关者,以及影响——正面或负面——模型可能对他们有影响。
“Overlooking negative impacts could result in considering only the positive side of the models, and could lead to damaging negative impacts [69]. For example, a user might be wrongfully flagged as a cyberbully by a detection model.” (Kim 等, 2021, p. 3274) 忽视负面影响可能导致只考虑模型的积极方面,并可能导致破坏性的负面影响 [69]。例如,检测模型可能会错误地将用户标记为网络欺凌者。
“In addition, researchers need to speculate potential biases of their developed models – a discussion that was missing in the reviewed papers. Potential bias may originate in the dataset – whether its source, filtering and curation strategy used by the researchers, or the manner in which ground truth data is annotated [75].” (Kim 等, 2021, p. 3274) 此外,研究人员需要推测他们开发的模型的潜在偏差——审查论文中缺少的讨论。潜在的偏见可能源于数据集——无论是数据集的来源、研究人员使用的过滤和管理策略,还是注释地面实况数据的方式 [75]。
“For instance, researchers can consider approaches like “data statements” [14] and “model cards” [98] that have been advocated recently to being transparency to ML systems.” (Kim 等, 2021, p. 3275) 例如,研究人员可以考虑最近提倡的“数据声明”[14] 和“模型卡”[98] 等方法,以提高 ML 系统的透明度。
“Together, data statements and models cards not only can provide benchmarked evaluation of a cyberbullying detection system in a variety of conditions, such as across different cultural, demographic, phenotypic, or intersectional groups, but also help to disclose the context in which the data and the models are intended to be used, the details of the performance evaluation procedures, how the system might be appropriately deployed, what biases might be reflected in practical uses of the system, as well as what harms may be perpetuated” (Kim 等, 2021, p. 3275) 数据陈述和模型卡一起,不仅可以在各种条件下(例如跨不同文化、人口统计、表型或交叉群体)提供网络欺凌检测系统的基准评估,而且还有助于揭示数据和模型的使用目的、绩效评估程序的细节、系统如何适当部署、系统的实际使用中可能反映出哪些偏见,以及哪些危害可能会永久存在
“Complementarily, these efforts could be augmented by research that have explored techniques to mitigate potential unwanted biases in the models such as by adding a fairness constraint [60], odd post-processing technique [143], incorporating of a fairness score when optimizing for accuracy [6], and penalizing for unfairness in the training of the models [126].” (Kim 等, 2021, p. 3275) 作为补充,这些努力可以通过探索减轻模型中潜在有害偏差的技术的研究来加强,例如通过添加公平约束 [60]、奇怪的后处理技术 [143]、在优化准确性时结合公平分数[6],并对模型训练中的不公平进行惩罚 [126]。
“Social science research has indicated that social desirability bias remains a significant issue in collecting data on the behavioral patterns of perpetrators and bystanders: respondents who engage in socially undesirable acts tend to under-report their participation, whereas those who engage in socially desirable acts tend to over-report their participation, in order to be viewed favorably respectively [63].” (Kim 等, 2021, p. 3275) 社会科学研究表明,在收集有关肇事者和旁观者行为模式的数据时,社会期望偏差仍然是一个重要问题:参与社会不受欢迎行为的受访者往往低报他们的参与,而那些参与社会期望行为的人往往过度报告他们的参与,以便分别被看好[63]。
“we therefore suggest guidelines suggested by Jo and Gebru [78] who emphasize considering issues such as consent, power, inclusivity, transparency, and ethics and privacy in the data curation practices and approaches to develop machine learning pipelines.” (Kim 等, 2021, p. 3275) 因此,我们建议 Jo 和 Gebru [78] 建议的指南,他们强调在数据管理实践和开发机器学习管道的方法中考虑同意、权力、包容性、透明度以及道德和隐私等问题。
“In this paper we conducted a systematic review of the past literature on automated cyberbullying detection models. After establishing a corpus of relevant documents to cyberbullying detection, we analyzed the human involvement in the development of these models using an established human-centered algorithmic design framework [13]. Specifically, we reviewed the past research in terms of their considerations for theoretical, participatory, and speculative design. Our review revealed that despite extensive research on developing cyberbullying detection models that optimize for statistical performance and methodological innovation, there were clear gaps in terms of a) how the complex phenomenon of cyberbullying was defined and operationalized from a theoreticalgrounding perspective; b) how a lack of involvement of stakeholders of bullying in data curation exposed potential for construct validity issues; and c) how poor speculation of the uses and users of the algorithms not only hampered model evaluation in real-world scenarios, but opened up opportunities for harm to various participating actors of cyberbullying. We concluded with guidelines on how a human-centered approach can help to address these pervasive concerns in this important research area within social computing.” (Kim 等, 2021, p. 3276) 在本文中,我们对过去关于自动网络欺凌检测模型的文献进行了系统回顾。在建立了网络欺凌检测相关文档的语料库之后,我们使用已建立的以人为中心的算法设计框架 [13] 分析了人类参与这些模型开发的情况。具体来说,我们回顾了过去的研究,从他们对理论、参与和思辨设计的考虑来看。我们的审查表明,尽管对开发针对统计性能和方法创新进行优化的网络欺凌检测模型进行了广泛的研究,但在以下方面存在明显差距:a)如何从理论基础的角度定义和实施网络欺凌的复杂现象; b) 欺凌利益相关者在数据管理中缺乏参与如何暴露出结构有效性问题的可能性; c) 对算法的用途和用户的推测不当不仅阻碍了现实场景中的模型评估,而且还为网络欺凌的各种参与者带来了伤害的机会。我们总结了关于以人为本的方法如何帮助解决社会计算这一重要研究领域中普遍存在的问题的指导方针。