Samih, Y., & Darwish, K. (2021). A Few Topical Tweets are Enough for Effective User Stance Detection. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, 2637–2646. https://doi.org/10.18653/v1/2021.eacl-main.227
“We analyzed 56 papers based on a three-prong human-centeredness algorithm design framework – spanning theoretical, participatory, and speculative design.” (Kim et al., 2021, p. 3251) 我们根据以人为本的三管齐下算法设计框架分析了 56 篇论文——涵盖理论、参与和推测设计。
“We found that the past literature fell short of incorporating human-centeredness across multiple aspects, ranging from defining cyberbullying, establishing the ground truth in data annotation, evaluating the performance of the detection models, to speculating the usage and users of the models, including potential harms and negative consequences.” (Kim et al., 2021, p. 3251) 我们发现,过去的文献未能将以人为本的理念纳入多个方面,从定义网络欺凌、在数据注释中建立基本事实、评估检测模型的性能,到推测模型的使用和用户,包括潜在的危害和负面后果。
“However, cyberbullying detection is not merely a classification task to identify which and whose content might be abusive towards an individual or group; we posit that building machine learning models for cyberbullying detection needs to adopt a human-centered perspective.” (Kim et al., 2021, p. 3252) 然而,网络欺凌检测不仅仅是一项分类任务,用于识别哪些内容和哪些内容可能对个人或群体进行辱骂;我们假设构建用于网络欺凌检测的机器学习模型需要采用以人为本的视角。
“Recent research in Computer-Supported Cooperative Work and Social Computing (CSCW) has noted that “human-centered paradigms for computing advocate for integrating ‘personal, social, and cultural aspects’ [77] into the design of technology, and accounting for stakeholders in the creation of technological solutions” [22].” (Kim et al., 2021, p. 3252) 最近对计算机支持的协同工作和社会计算 (CSCW) 的研究指出,“以人为中心的计算范式提倡将‘个人、社会和文化方面’[77] 整合到技术设计中,并考虑利益相关者技术解决方案的创建”[22]。
“machine learning needs to stay grounded in human needs [22], models need to be built in inclusive ways that adequately represent the diverse experiences of different individuals and minimize biases [122], and that machine learning approaches ought to incorporate interpretability and transparency to not only elucidate its potential for harm [1, 15, 48, 66], but also how data-driven decisions are used in practical scenarios [22, 136].” (Kim et al., 2021, p. 3252) 机器学习需要以人类需求为基础 [22],模型需要以包容的方式构建,以充分代表不同个体的不同经历并最大限度地减少偏见 [122],并且机器学习方法应该结合可解释性和透明度,而不是仅阐明其潜在的危害 [1、15、48、66],以及如何在实际场景中使用数据驱动的决策 [22、136]。
“As Amershi et al. [8] rightly noted: “humans are more than “a source of labels” and because the process of design should not hinge entirely on the construct of “the user” [128], people’s involvement with machine learning can take many roles beyond data curation, such as in supporting algorithm selection and tuning, and identifying its points of success and failure.” (Kim et al., 2021, p. 3252) 正如 Amershi 等人。 [8] 正确地指出:“人类不仅仅是“标签的来源”,而且由于设计过程不应完全取决于“用户”[128] 的构造,人们对机器学习的参与可以发挥数据以外的许多作用策展,例如支持算法选择和调整,以及识别其成功点和失败点。
“we argue that building cyberbullying detection models necessitates a deep understanding of a) how cyberbullying can be operationalized based on its theoretical and psychological underpinnings; b) what could be effective ways to represent the varied subjective experiences of cyberbullying within the models given the subjective nature of bullying [135] and how model evaluation needs to look beyond quantifiable metrics to incorporate human feedback, mental models, and social interpretations [13]; and c) who could be the potential stakeholders that could potentially harness the outcomes of such models, and how.” (Kim et al., 2021, p. 3253) 我们认为,建立网络欺凌检测模型需要深入了解 a) 如何根据其理论和心理基础实施网络欺凌; b) 鉴于欺凌的主观性质 [135],以及模型评估如何需要超越可量化的指标以纳入人类反馈、心智模型和社会解释 [13],在模型中表示网络欺凌的各种主观体验的有效方法是什么? ]; c) 谁可以成为潜在的利益相关者,可以潜在地利用这些模型的结果,以及如何。
“From a theoretical standpoint, we first focus on existing algorithms’ alignment with theories of cyberbullying especially in operationalizing acts and incidents of cyberbullying.” (Kim et al., 2021, p. 3253) 从理论的角度来看,我们首先关注现有算法与网络欺凌理论的一致性,尤其是在实施网络欺凌行为和事件方面。
“Then from a participatory perspective, we describe if and how existing algorithms have involved the human (or broadly various stakeholders) in data annotation and model evaluation.” (Kim et al., 2021, p. 3253) 然后从参与的角度,我们描述了现有算法是否以及如何让人类(或广泛的各种利益相关者)参与数据注释和模型评估。
“Finally, from the perspective of speculative algorithm design, we shine a light on how researchers have envisioned the usage of existing detection algorithms in realworld scenarios, by who, including consideration of harms and negative consequences.” (Kim et al., 2021, p. 3253) 最后,从推测性算法设计的角度,我们阐明了研究人员如何设想由谁在现实场景中使用现有检测算法,包括对危害和负面后果的考虑。
“Other scholars noted that high quality datasets are lacking in this area [105, 135], primarily because of the lack of suitable ground truth data on cyberbullying and therefore a need to rely on manual annotation, which is time-, cost-, and effort-intensive [4, 91].” (Kim et al., 2021, p. 3253) 其他学者指出,该领域缺乏高质量的数据集 [105, 135],主要是因为缺乏关于网络欺凌的合适的基本事实数据,因此需要依赖人工注释,这是时间、成本和精力- 密集 [4, 91]。
“In fact, Emmery et al. [53] critiqued in their review that there is a reproducibility as well as an evaluation crisis in this research area – most prior work has used small, heterogeneous datasets, without a thorough evaluation of applicability across domains, platforms, and populations.” (Kim et al., 2021, p. 3254) 事实上,Emmery 等人。 [53] 在他们的评论中批评该研究领域存在可重复性和评估危机——大多数先前的工作使用了小型、异构的数据集,没有对跨领域、平台和人群的适用性进行全面评估。
“However, many researchers, based on their respective reviews, suggested machine learning methodological improvements, although none considered how these improvements need to stem from real-world scenarios where the algorithms could benefit or potentially harm intended individuals.” (Kim et al., 2021, p. 3254) 然而,许多研究人员根据他们各自的评论,提出了机器学习方法的改进建议,尽管没有人考虑到这些改进需要如何源于算法可能有益于或可能损害目标个体的现实场景。
“Kovačević argued that more work needs to be done in terms of taking into account user and contextual aspects of the cyberbullying incidents.” (Kim et al., 2021, p. 3254) Kovačević 认为,在考虑网络欺凌事件的用户和上下文方面需要做更多的工作。
“Accordingly, Al-Garadi et al. [4] recommended that cyberbullying detection use better feature engineering to capture the rich context of the incidents rather than overly stressing feature selection and machine learning methodological improvements, while Tokunaga [154] suggested careful consideration of user demographic attributes in operationalizing the concept of cyberbullying.” (Kim et al., 2021, p. 3254) 因此,Al-Garadi 等人。 [4] 建议网络欺凌检测使用更好的特征工程来捕获事件的丰富背景,而不是过分强调特征选择和机器学习方法的改进,而 Tokunaga [154] 建议在实施网络欺凌概念时仔细考虑用户人口统计属性。
“However, none of these papers suggested involving the stakeholders of cyberbullying incidents victims, bystanders, or bullies in capturing this valuable context.” (Kim et al., 2021, p. 3254) 然而,这些论文都没有建议让网络欺凌事件的受害者、旁观者或欺凌者的利益相关者参与捕捉这一有价值的背景。
“Suggested evaluation metrics included the F-1 score or the area under receiver-operating characteristic (ROC) curve (AUC), but the existing reviews did not discuss the significance and value of human involvement toward unpacking misclassifications.” (Kim et al., 2021, p. 3254) 建议的评估指标包括 F-1 分数或接受者操作特征 (ROC) 曲线 (AUC) 下的面积,但现有的评论没有讨论人类参与对拆包错误分类的意义和价值。
“Machine learning is increasingly adopted to address societal problems via data-driven decisionmaking [22], in Fiebrink and Gillies [56]’s words, however, it “often centers on impersonal algorithmic concerns, removed from human considerations such as usability, intuition, effort, and human learning; it is also too often detached from the variety and deep complexity of human contexts in which machine learning may be ultimately applied.”” (Kim et al., 2021, p. 3255) 用 Fiebrink 和 Gillies [56] 的话来说,机器学习越来越多地被用于通过数据驱动的决策制定 [22] 来解决社会问题,然而,它“通常以非个人的算法问题为中心,从可用性、直觉、努力和人类学习;它也常常脱离机器学习最终可能应用的人类环境的多样性和深度复杂性。”
“First, humancenteredness, in the form of behavioral and social science theories, can provide both prescriptive (helping identify which features might be valuable and why) as well as descriptive knowledge (what do the outcomes of the models mean) in the design of machine learning models [13].” (Kim et al., 2021, p. 3255) 首先,以行为和社会科学理论的形式,以人为本可以在机器学习的设计中提供说明性(帮助确定哪些特征可能有价值以及为什么)以及描述性知识(模型的结果意味着什么)模型 [13]。
“Next, Fiebrink and Gillies [56] advocated that examining machine learning from a humancentered perspective includes explicitly recognizing both human work and the human contexts in which machine learning is used.” (Kim et al., 2021, p. 3255) 接下来,Fiebrink 和 Gillies [56] 提倡从以人为本的角度检查机器学习,包括明确识别人类工作和使用机器学习的人类环境。
“Complementarily, when machine learning models are evaluated by human experts, such as psychologists and mental health professionals in the case of cyberbullying detection, they can help to bridge disconnects between the functionality of the models and their social uses [13].” (Kim et al., 2021, p. 3255) 作为补充,当机器学习模型由人类专家评估时,例如在网络欺凌检测中的心理学家和心理健康专家,他们可以帮助弥合模型功能与其社会用途之间的脱节 [13]。
“Third, a human-centered approach to machine learning demands making machine learning more usable and effective for a broader range of stakeholders, including those who would use the outcomes of the machine learning system and those who are affected by them [56].” (Kim et al., 2021, p. 3255) 第三,以人为本的机器学习方法要求机器学习对更广泛的利益相关者更有用和更有效,包括那些将使用机器学习系统结果的人和那些受其影响的人 [56]。
“Baumer [13] conceptualized human-centered algorithm design to engender three key dimensions or strategies – theoretical, participatory, and speculative design.” (Kim et al., 2021, p. 3256) Baumer [13] 将以人为本的算法设计概念化,以产生三个关键维度或策略——理论、参与和推测设计。
“The theories that are utilized for the design can, therefore, be prescriptive by giving a guideline to why certain features should be selected over others for the training of a machine learning model.” (Kim et al., 2021, p. 3256) 因此,用于设计的理论可以通过指导为什么应该选择某些特征而不是其他特征来训练机器学习模型来进行说明。
“Therefore, it essentially provides a bridge between people who might be interacting with the development of the system and the ones that designed it. By doing so, in the context of machine learning, this enables an exchange between the possibly varied end users of the algorithm and the designers of the algorithm.” (Kim et al., 2021, p. 3256) 因此,它本质上是在可能与系统开发交互的人员和系统设计人员之间架起了一座桥梁。通过这样做,在机器学习的背景下,可以在算法的可能不同的最终用户和算法的设计者之间进行交流。
“It emphasizes that it is important to not just produce artifacts that can be useful, but also be provocative in imagining possible futures with these artifacts. Since it involves going beyond the current problem context to such possible futures, this freedom can facilitate thinking through the ramifications of the algorithm’s use in different situations and the (positive or negative) impact on different groups of users or stakeholders.” (Kim et al., 2021, p. 3256) 它强调重要的是,不仅要生产有用的人工制品,而且要积极想象这些人工制品可能的未来。由于它涉及超越当前问题上下文到可能的未来,这种自由可以促进思考算法在不同情况下使用的后果以及对不同用户或利益相关者群体的(正面或负面)影响。
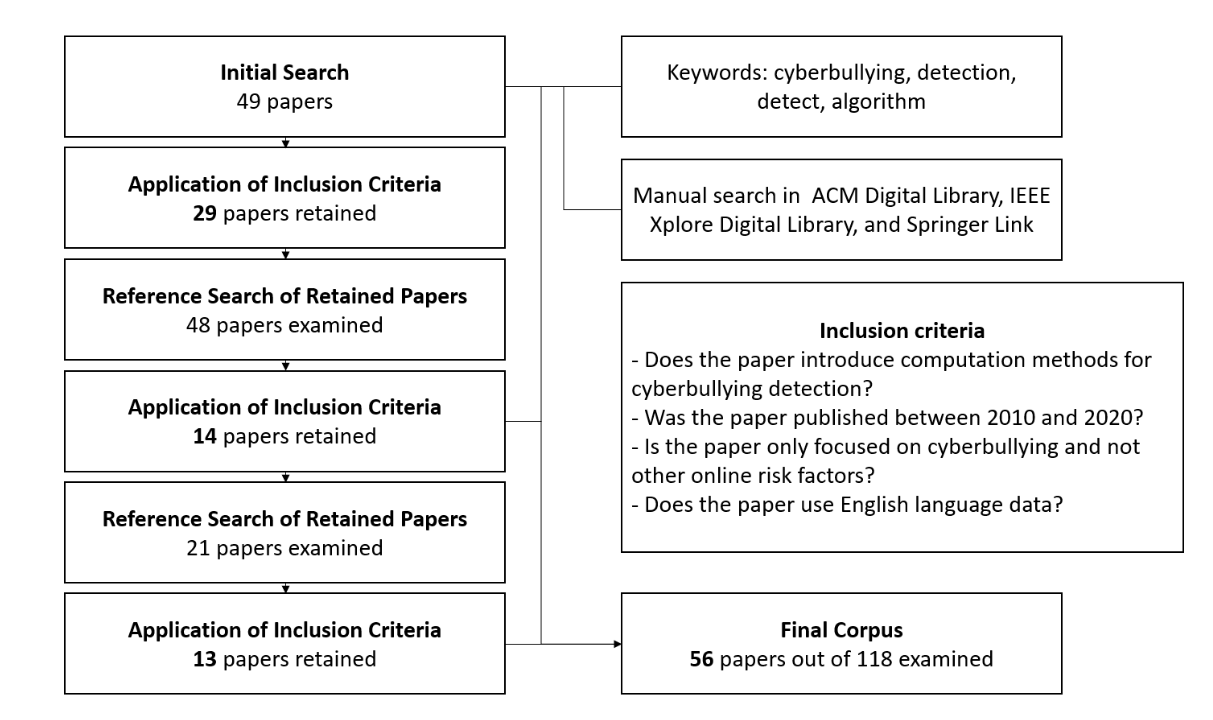
“we coded each document (paper) for relevancy to our scope based on close reads of the abstract, methodology, and discussion sections.” (Kim et al., 2021, p. 3257) 我们根据对摘要、方法论和讨论部分的仔细阅读,对每篇文档(论文)进行了编码,以便与我们的范围相关。
“we then adopted a snowball sampling approach, and went through the reference list to conduct a second pass of search.” (Kim et al., 2021, p. 3257) 然后我们采用滚雪球抽样的方法,通过参考列表进行第二次搜索。

Referred in Zotero Better Notes User Guide: Workflow